







MMDeploy详解
1. 简介
- 一个 ONNX 模型主要由 ModelProto,GraphProto,NodeProto,ValueInfoProto 这几个数据类的对象组成。
- ONNX:Open Neural Network Exchange
- 是 Facebook 和微软在2017年共同发布的,用于标准描述计算图的一种格式。
- ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样
- ONNX是一个静态的计算图,即没有控制流(分支语句、循环语句)的计算图
- 模型部署要解决的两大问题
- 模型框架兼容性差
- 模型运行速度慢
- 推理引擎
- ONNX Runtime
- 是由微软维护的一个跨平台机器学习推理加速器,即”推理引擎“
- TensorRT
- ncnn
- openppl
- OpenVINO
- ONNX Runtime
- MMDeploy 建立了一个统一高效的模型转换框架,并实现了高度可扩展的组件式 SDK,支持了 7 种后端推理引擎,支持将 OpenMMLab 各算法库训练的模型一键式部署到硬件设备上并高效运行。为人工智能应用部署建立了一套适应全场景、高性能的部署框架,可高效适配各类芯片硬件,满足终端用户对人工智能应用的需求。
- 模型部署相关的知识:
- 中间表示 ONNX 的定义标准。
- PyTorch 模型转换到 ONNX 模型的方法。
- 推理引擎 ONNX Runtime、TensorRT 的使用方法。
- 部署流水线 PyTorch - ONNX - ONNX Runtime/TensorRT 的示例及常见部署问题的解决方法。
- MMDeploy C/C++ 推理 SDK。
1.1 流程简介
-
运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
-
深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。 因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:

-
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
-
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
-
MMDeploy 定义的模型部署流程,如下图所示:

1.1.1 模型转换(Model Converter)
- 模型转换的主要功能是把输入的模型格式,转换为目标设备的推理引擎所要求的模型格式。
- 目前,MMDeploy 可以把 PyTorch 模型转换为 ONNX、TorchScript 等和设备无关的 IR 模型。也可以将 ONNX 模型转换为推理后端模型。两者相结合,可实现端到端的模型转换,也就是从训练端到生产端的一键式部署。
1.1.2 MMDeploy 模型(MMDeploy Model)
- 也称 SDK Model。它是模型转换结果的集合。不仅包括后端模型,还包括模型的元信息。这些信息将用于推理 SDK 中。
1.1.3 推理 SDK(Inference SDK)
- 封装了模型的前处理、网络推理和后处理过程。对外提供多语言的模型推理接口。
1.2 支持多种OpenMMLab算法库
- mmcls
- mmdet
- mmseg
- mmedit
- mmocr
- mmpose
- mmdet3d
- mmrotate
- mmaction2
- mmyolo
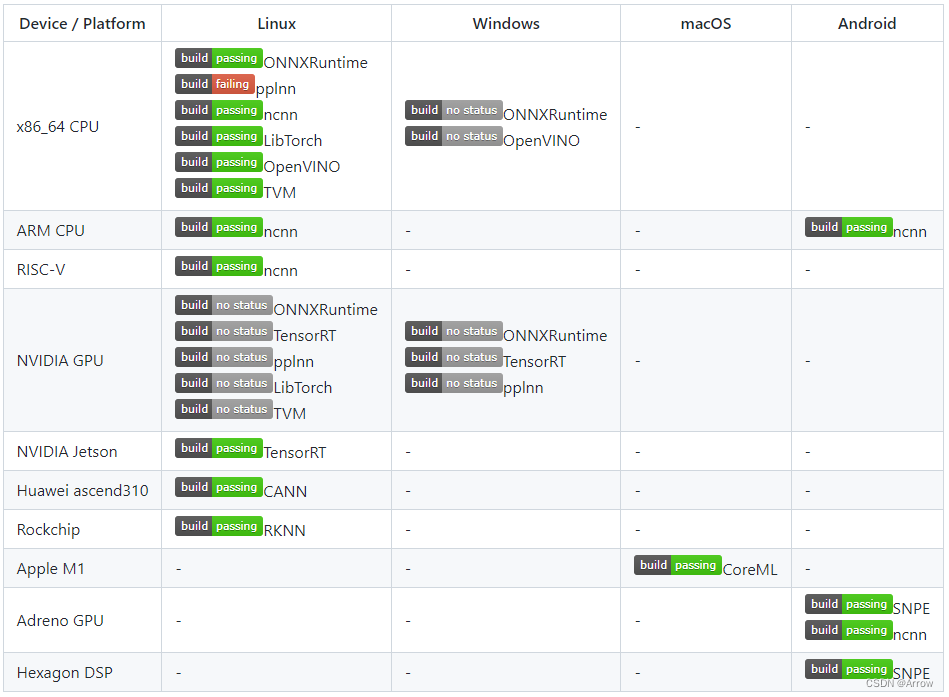
1.3 支持多种推理后端
2. 模型部署中常见的难题
- 模型的动态化。出于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛用性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
- 新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于 ONNX 维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在 ONNX 和推理引擎中支持新算子。
- 中间表示与推理引擎的兼容问题。由于各推理引擎的实现不同,对 ONNX 难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
3. PyTorch 转 ONNX 详解 (torch.onnx.export)
3.1 计算图导出方法
- TorchScript 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个torch.nn.Module模型会被转换成 TorchScript 的torch.jit.ScriptModule模型。
- 现在, TorchScript 也被常当成一种中间表示使用。
- torch.onnx.export中需要的模型实际上是一个torch.jit.ScriptModule。而要把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和脚本化(script)两种导出计算图的方法。如果给torch.onnx.export传入了一个普通 PyTorch 模型(torch.nn.Module),那么这个模型会默认使用跟踪的方法导出。这一过程如下图所示:

- 跟踪法:只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环)
- 脚本化:则能通过解析模型来正确记录所有的控制流。
- 这两种转换方法的区别:
import torch
class Model(torch.nn.Module):
def __init__(self, n):
super().__init__()
self.n = n
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
for i in range(self.n):
x = self.conv(x)
return x
models = [Model(2), Model(3)]
model_names = ['model_2', 'model_3']
for model, model_name in zip(models, model_names):
dummy_input = torch.rand(1, 3, 10, 10)
dummy_output = model(dummy_input)
model_trace = torch.jit.trace(model, dummy_input)
model_script = torch.jit.script(model)
# 跟踪法与直接 torch.onnx.export(model, ...)等价
torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output)
# 脚本化必须先调用 torch.jit.script
torch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)
- 在这段代码里,我们定义了一个带循环的模型,模型通过参数n来控制输入张量被卷积的次数。之后,我们各创建了一个n=2和n=3的模型。我们把这两个模型分别用跟踪和脚本化的方法进行导出。 值得一提的是,由于这里的两个模型(model_trace, model_script)是 TorchScript 模型,export函数已经不需要再运行一遍模型了。
- (如果模型是用跟踪法得到的,那么在执行torch.jit.trace的时候就运行过一遍了;而用脚本化导出时,模型不需要实际运行)参数中的dummy_input和dummy_output仅仅是为了获取输入和输出张量的类型和形状。 运行上面的代码,我们把得到的4个 onnx 文件用 Netron 可视化。
- 首先看跟踪法得到的 ONNX 模型结构。可以看出来,对于不同的 n,ONNX 模型的结构是不一样的。
- 而用脚本化的话,最终的 ONNX 模型用 Loop 节点来表示循环。这样哪怕对于不同的 n,ONNX 模型也有同样的结构。 由于推理引擎对静态图的支持更好,通常我们在模型部署时不需要显式地把 PyTorch 模型转成 TorchScript 模型,直接把 PyTorch 模型用 torch.onnx.export 跟踪导出即可。了解这部分的知识主要是为了在模型转换报错时能够更好地定位问题是否发生在 PyTorch 转 TorchScript 阶段。
3.2 参数讲解
- torch.onnx.export 在 torch.onnx.__init__.py文件中的定义如下:
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
input_names=None, output_names=None, aten=False, export_raw_ir=False,
operator_export_type=None, opset_version=None, _retain_param_name=True,
do_constant_folding=True, example_outputs=None, strip_doc_string=True,
dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,
enable_onnx_checker=True, use_external_data_format=False):
- 参数详解:
- model:要转换的模型
- args:模型的任意一组输入
- f:导出的 ONNX 文件的文件名
- export_params:模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX 是用同一个文件表示记录模型的结构和权重的。 我们部署时一般都默认这个参数为 True。如果 onnx 文件是用来在不同框架间传递模型(比如 PyTorch 到 Tensorflow)而不是用于部署,则可以令这个参数为 False。
- input_names, output_names:设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。 ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。 在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
- opset_version:转换时参考哪个 ONNX 算子集版本,默认为9。后文会详细介绍 PyTorch 与 ONNX 的算子对应关系。
- dynamic_axes:指定输入输出张量的哪些维度是动态的。 为了追求效率,ONNX 默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的。 我们来看一个dynamic_axes的设置例子
- 下面的代码导出3个 ONNX 模型,分别为没有动态维度、第0维动态、第2第3维动态的模型。 在这份代码里,我们是用列表的方式表示动态维度,例如:
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
x = self.conv(x)
return x
model = Model()
dummy_input = torch.rand(1, 3, 10, 10)
model_names = ['model_static.onnx',
'model_dynamic_0.onnx',
'model_dynamic_23.onnx']
dynamic_axes_0 = {
'in' : [0],
'out' : [0]
}
dynamic_axes_23 = {
'in' : [2, 3],
'out' : [2, 3]
}
torch.onnx.export(model, dummy_input, model_names[0],
input_names=['in'], output_names=['out'])
torch.onnx.export(model, dummy_input, model_names[1],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
torch.onnx.export(model, dummy_input, model_names[2],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
4. PyTorch 对 ONNX 的算子支持
- 在确保torch.onnx.export()的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。而具体添加算子的方法我们会在之后的文章里介绍。 在转换普通的torch.nn.Module模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:
- 该算子可以一对一地翻译成一个 ONNX 算子。
- 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
- 该算子没有定义翻译成 ONNX 的规则,报错。
4.1 ONNX 算子文档
4.2 PyTorch 对 ONNX 算子的映射
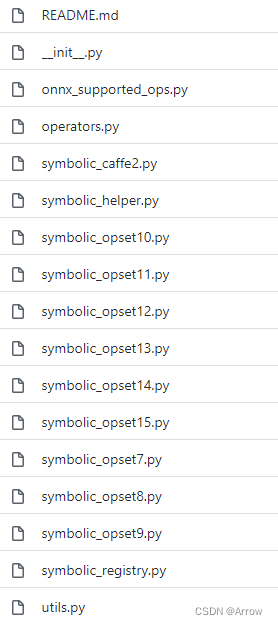
- 在 PyTorch 中,和 ONNX 有关的定义全部放在 torch.onnx 目录中,如下图所示:
5. 在 PyTorch 中支持更多 ONNX 算子
- 而要使 PyTorch 算子顺利转换到 ONNX ,我们需要保证以下三个环节都不出错:
- 算子在 PyTorch 中有实现
- 有把该 PyTorch 算子映射成一个或多个 ONNX 算子的方法
- ONNX 有相应的算子
- 可在实际部署中,这三部分的内容都可能有所缺失。其中最坏的情况是:我们定义了一个全新的算子,它不仅缺少 PyTorch 实现,还缺少 PyTorch 到 ONNX 的映射关系。但所谓车到山前必有路,对于这三个环节,我们也分别都有以下的添加支持的方法:
- PyTorch 算子
- 组合现有算子
- 添加 TorchScript 算子
- 添加普通 C++ 拓展算子
- 映射方法
- 为 ATen 算子添加符号函数
- 为 TorchScript 算子添加符号函数
- 封装成 torch.autograd.Function 并添加符号函数
- ONNX 算子
- 使用现有 ONNX 算子
- 定义新 ONNX 算子
- PyTorch 算子
6. ONNX 模型的修改与调试
6.1 ONNX 的底层实现
6.1.1 ONNX 的存储格式
- ONNX 在底层是用 Protobuf 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文件把数据存储进一份二进制文件。可以说,数据定义文件就是数据类,二进制文件就是数据类的实例。 这里给出一个 Protobuf 数据定义文件的例子:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}
- 这段定义表示在 Person 这种数据类型中,必须包含 name、id 这两个字段,选择性包含 email 字段。根据这份定义文件,用户就可以选择一种编程语言,定义一个含有成员变量 name、id、email 的 Person 类,把这个类的某个实例用 Protobuf 存储成二进制文件;反之,用户也可以用二进制文件和对应的数据定义文件,读取出一个 Person 类的实例。
- ONNX 提供了很多实用 API,我们可以在完全不了解 Protobuf 的前提下,构造和读取 ONNX 模型。
6.1.2 ONNX 的结构定义
- 在用 API 对 ONNX 模型进行操作之前,我们还需要先了解一下 ONNX 的结构定义规则,学习一下 ONNX 在 Protobuf 定义文件里是怎样描述一个神经网络的。
- 回想一下,神经网络本质上是一个计算图。计算图的节点是算子,边是参与运算的张量。而通过可视化 ONNX 模型,我们知道 ONNX 记录了所有算子节点的属性信息,并把参与运算的张量信息存储在算子节点的输入输出信息中。事实上,ONNX 模型的结构可以用类图大致表示如下:

7. MMDeploy源码手动安装
7.1 下载
git clone -b 1.x git@github.com:open-mmlab/mmdeploy.git --recursive
- 如果由于网络等原因导致拉取仓库子模块失败,可以尝试通过如下指令手动再次安装子模块:
git clone git@github.com:NVIDIA/cub.git third_party/cub
cd third_party/cub
git checkout c3cceac115
# 返回至 third_party 目录, 克隆 pybind11
cd ..
git clone git@github.com:pybind/pybind11.git pybind11
cd pybind11
git checkout 70a58c5
- 如果以 SSH 方式 git clone 代码失败,您可以尝试使用 HTTPS 协议下载代码:
git clone -b 1.x https://github.com/open-mmlab/mmdeploy.git MMDeploy
cd MMDeploy
git submodule update --init --recursive
7.2 编译
- 根据您的目标平台,点击如下对应的链接,按照说明编译 MMDeploy
8. Hobot DNN模型推理引擎(MMDeploy暂不支持)
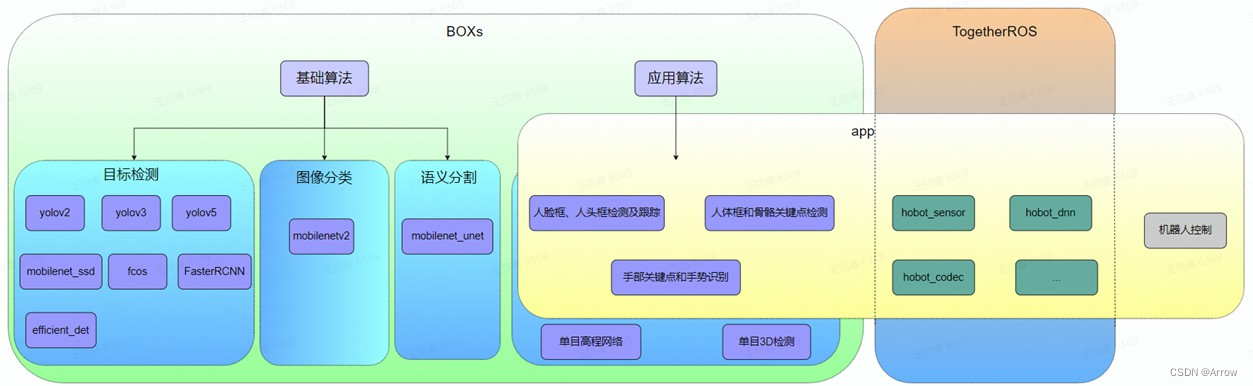
- TogetherROS集成了Hobot DNN模型推理库,集成了众多开源模型,借助底层芯片中的AI引擎BPU,提供充足的算力保障,开发者实际使用中,就不用花费很多时间在模型的调教和数据的训练上,基于这套系统,很快就可以部署人工智能应用啦。

- 基础算法和应用算法















 6054
6054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









