










大数据之Redis集群(三主三从)系统的部署(主从容错切换迁移+主从扩容+主从缩容 )
1.Centos 系统部署
本次Centos系统部署虚拟机选用的为VMware Workstation Pro16版本:
进入阿里云镜像源地址下载所需镜像文件:
https://mirrors.aliyun.com/centos/7/isos/x86_64/
这里Linux镜像文件下我选择下载:CentOS-7-x86_64-DVD-2009.iso:
开始设置虚拟机配置:
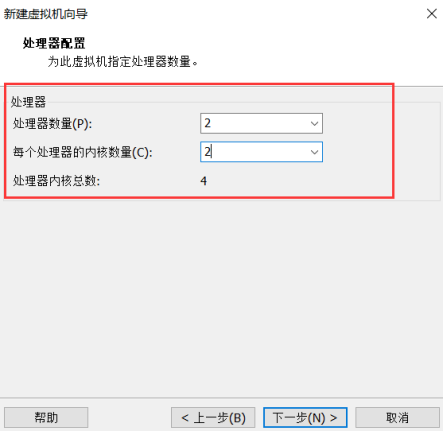
设置处理器和内核:
设置内存:
设置网络类型:
设置系统磁盘内存:
其他配置默认即可。
选择我们下载的镜像文件:
开启CentOS7虚拟机:
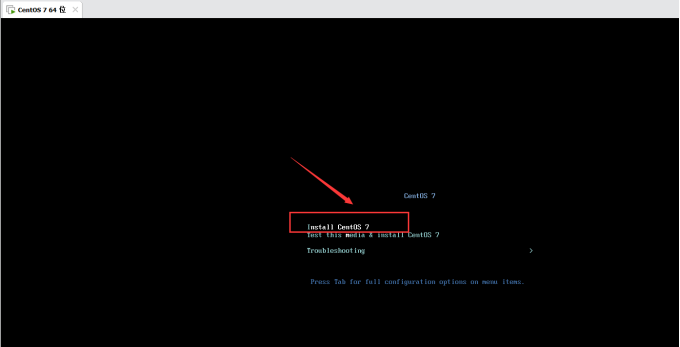
如图,选择第一个安装,然后就等待:
设置系统语言:

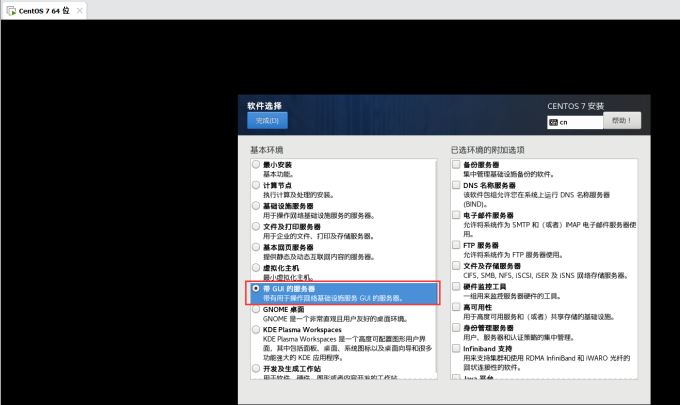
选择带GUI的服务器:
GUI 即图形用户界面(Graphical User Interface,简称 GUI,又称图形用户接口)是指采用图形方式显示的计算机操作用户界面。
图形用户界面是一种人与计算机通信的界面显示格式,允许用户使用鼠标等输入设备操纵屏幕上的图标或菜单选项,以选择命令、调用文件、启动程序或执行其它一些日常任务。
图形界面对于用户来说在视觉上更易于接受,可以图形化操作一些软件或者应用,服务器带有gui的目的主要是为了简单操作。
图形化的操作方式具有很强的实用性,方便了用户的使用,提高了使用效率。开发人员通过对图形用户界面的不断优化,使信息、数据传输更高效,结果运行与反馈更便捷、准确。
打开以太网连接网络:
设置root密码:
等待安装:
配置完成重启:
重启之后进入虚拟机许可证接受:

同意许可后设置语言和时区:

设置用户名和密码:

成功安装CentOS 7:

将虚拟机名称修改为master:
开始对虚拟机进行网卡配置:
先查看虚拟网络编辑器相关网络信息:
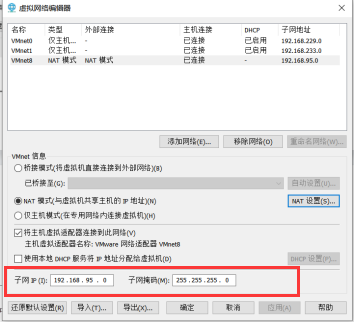
图中的子网IP范围,表示虚拟机在192.168.95.0~192.168.95.255范围内。
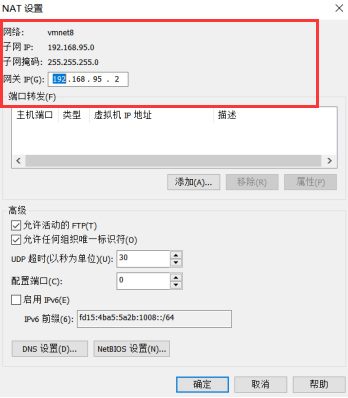
图中192.168.95.2为网关地址,192.168.95.255为广播地址,192.168.95.0一般为网段IP,所以0,2,255这三个地址不能设置。
进入虚拟机进行网卡配置:
命令:
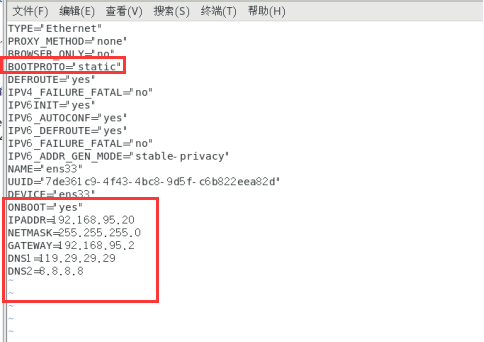
vim /etc/sysconfig/network-scripts/ifcfg-ens33

设置 BOOTPROTO=static 为网络分配方式,静态否则无法连通网络。
ONBOOT=yes #指的是系统启动时是否激活网卡
添加
IPADDR=192.168.95.20
NETMASK=255.255.255.0
GATEWAY=192.168.95.2
DNS1=119.29.29.29
DNS2=8.8.8.8
之后设置DNS:
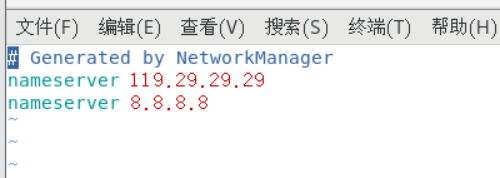
vim /etc/resolv.conf
dns就是用来解析域名的,域名就是我们经常在浏览器中输入的网址,域名的真正目的是为了方便记忆,当我们输入域名的时候,其实是要去访问一个服务器(可以想象成一台电脑),其实真正访问是通过IP地址访问的,当我们只输入域名的时候就需要一个中间人帮我们把域名翻译成ip地址,这个“中间人”就是dns服务器了。
加入nameserver解析:
nameserver 119.29.29.29
nameserver 8.8.8.8
重启虚拟机(命令:shutdown -r now或者reboot)
或使用service network restart命令重启网卡,更新配置信息。
输入重启命令:
reboot
重启之后试试ping一下百度能否ping的通(ctrl+c停止ping)
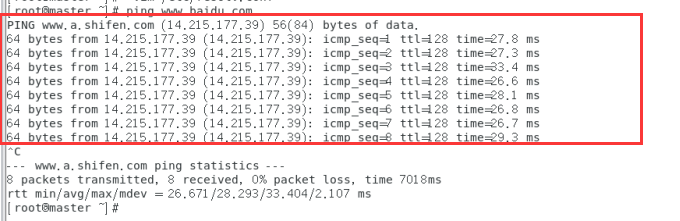
成功ping通!
成功打开浏览器连上网络,CentOS 7网卡配置成功!
2.Docker部署
Docker部署选择root用户登录:
选择root用户更加方便,不用再麻烦输入sudo等权限问题。
安装Docker
Docker是基于Go语言实现的云开源项目。
Docker的主要目标是“Build,Ship and Run Any App,Anywhere”,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP(可以是一个WEB应用或数据库应用等等)及其运行环境能够做到“一次镜像,处处运行”。

Docker 将应用打成镜像,通过镜像成为运行在Docker容器上面的实例,而 Docker容器在任何操作系统上都是一致的,这就实现了跨平台、跨服务器。只需要一次配置好环境,换到别的机子上就可以一键部署好,达到应用程式跨平台间的无缝接轨运作,大大简化了操作。解决了运行环境和配置问题的软件容器, 方便做持续集成并有助于整体发布的容器虚拟化技术。
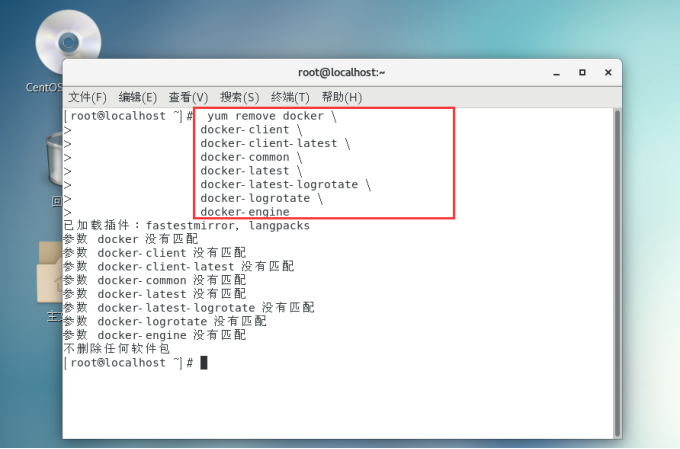
先卸载旧版本:
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
开始安装docker:
CentOS7能上外网:
安装需要的软件包:
GCC是以GPL许可证所发行的自由软件,也是GNU计划的关键部分。GCC的初衷是为GNU操作系统专门编写一款编译器,现已被大多数类Unix操作系统(如Linux、BSD、MacOS X等)采纳为标准的编译器,甚至在微软的Windows上也可以使用GCC。GCC支持多种计算机体系结构芯片,如x86、ARM、MIPS等,并已被移植到其他多种硬件平台 。
GCC原名为GNU C语言编译器(GNU C Compiler),只能处理C语言。但其很快扩展,变得可处理C++,后来又扩展为能够支持更多编程语言,如Fortran、Pascal、Objective -C、Java、Ada、Go以及各类处理器架构上的汇编语言等,所以改名GNU编译器套件(GNU Compiler Collection) 。
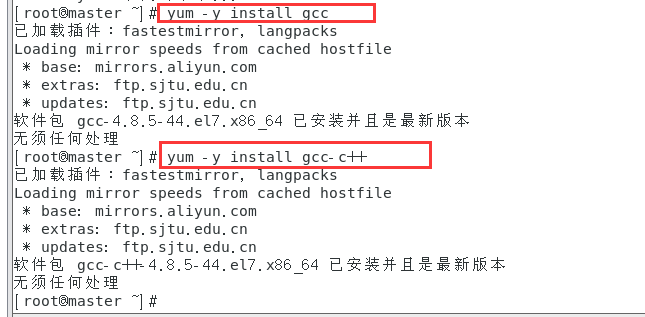
命令:
yum -y install gcc
yum -y install gcc-c++
yum install -y yum-utils

设置stable镜像仓库:
docker默认的官方仓库地址:
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
##此地址为官方的仓库地址,在国内建议不要用
用阿里云的镜像仓库地址:
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo

安装docker相关的引擎
#先更新yum软件包索引:
yum makecache fast

安装DOCKER CE
yum -y install docker-ce docker-ce-cli containerd.io
Docker CE指的是docker社区版,用于为了开发人员或小团队创建基于容器的应用,与团队成员分享和自动化的开发管道。Docker CE版本提供了简单的安装和快速的安装,以便可以立即开始开发。

执行结果:
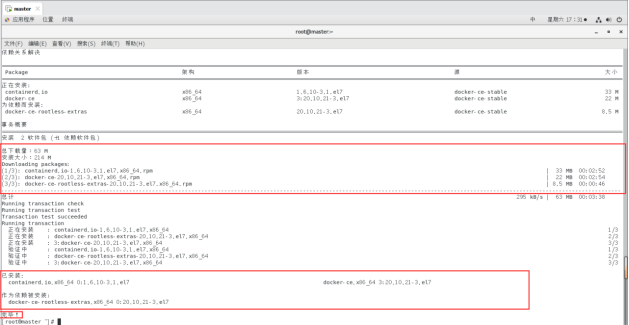
启动docker
systemctl start docker

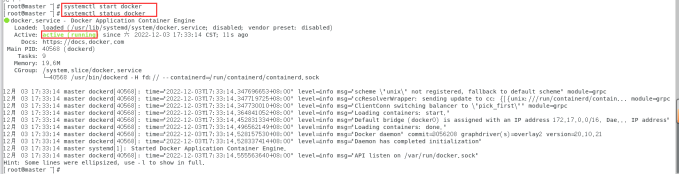
查看docker运行状态:
systemctl status docker
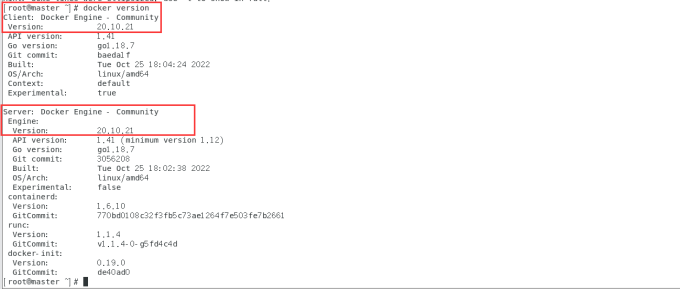
查看安装版本信息:
docker version
测试docker安装:
docker run hello-world
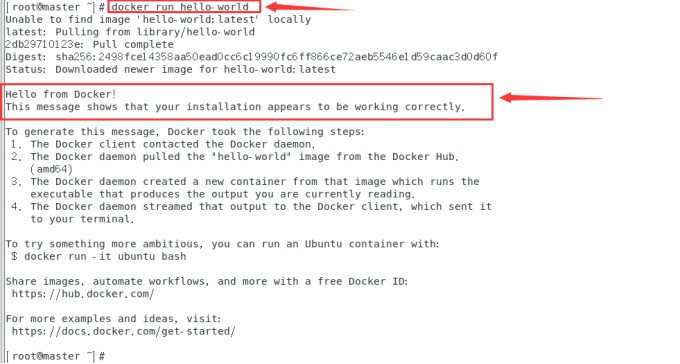
在这个过程run做了以下流程: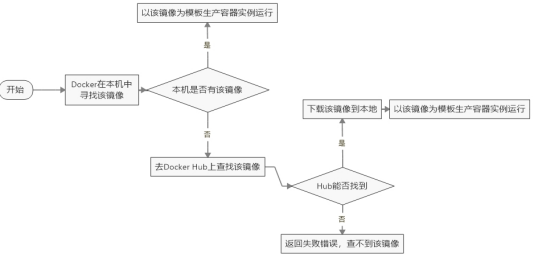
至此,Docker部署完成!
3.Redis集群
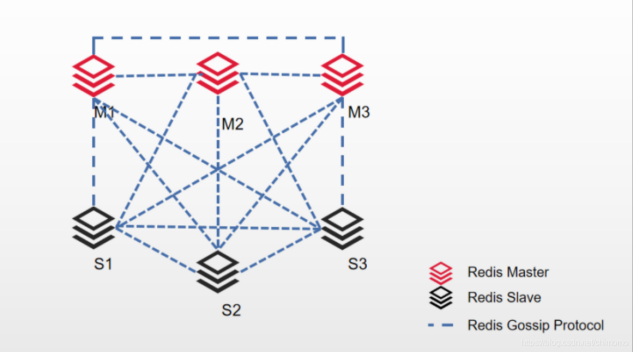
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
一组Redis Cluster是由多个Redis实例组成,使用6实例,其中3个为主节点,3个为从节点。一旦有主节点发生故障的时候,Redis Cluster可以选举出对应的从节点成为新的主节点,继续对外服务,从而保证服务的高可用性
注意:
1、当集群内一个Master以及其对应的Slave同时宕机,集群将无法提供服务。
2、当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
原理架构图:
一致性哈希算法分区作用:
提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
部署Redis集群依然选择root用户登录:
启动docker:
systemctl start docker

查看docker运行状态:
systemctl status docker
部署3主3从redis集群配置之前先搜索redis镜像:
docker search redis:6.0.8
拉取redis:6.0.8镜像
docker pull redis:6.0.8
已经成功拉取的redis镜像查看:
docker images
查看自己ip地址:
Ifconfig
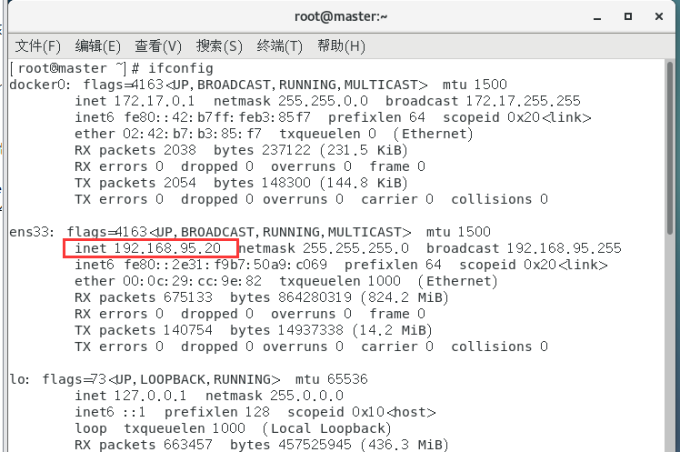
可知Ip地址为之前我们设置的 192.168.95.20
查看防火墙状态是否关闭:
systemctl status firewalld
如果没有关闭设置永久关闭防火墙:
systemctl disable firewalld
查看防火墙状态:
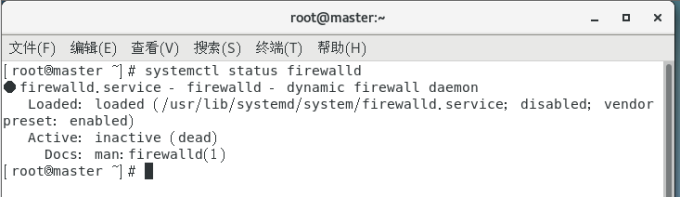
查看状态后发现,防火墙服务已关闭。
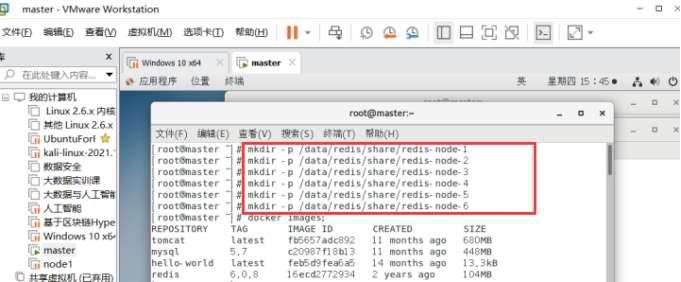
先新建6个宿主机对应redis目录:
mkdir -p /data/redis/share/redis-node-1
mkdir -p /data/redis/share/redis-node-2
mkdir -p /data/redis/share/redis-node-3
mkdir -p /data/redis/share/redis-node-4
mkdir -p /data/redis/share/redis-node-5
mkdir -p /data/redis/share/redis-node-6
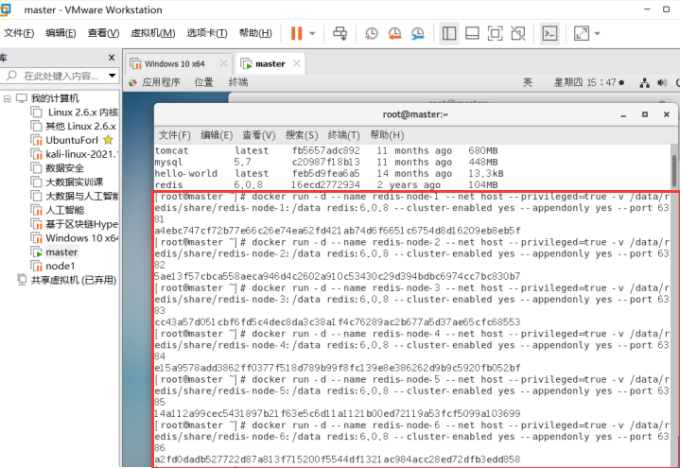
创建并运行docker容器实例:
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
查看正在运行的docker容器
docker ps
6个redis容器运行成功,效果如下:

命令分步解释:
docker run #创建并运行docker容器实例
--name redis-node-6 #容器名字
--net host #使用宿主机的IP和端口,默认
--privileged=true #获取宿主机root用户权限
-v /data/redis/share/redis-node-6:/data #容器卷,宿主机地址:docker内部地址
redis:6.0.8 #redis镜像和版本号
--cluster-enabled yes #开启redis集群
--appendonly yes #开启持久化
--port 6386 #redis端口号
进入容器redis-node-1并为6台机器构建集群关系
//进入docker容器后才能执行构建主从关系命令,注意本机的真实IP地址。
进入redis-node-1容器构建主从关系:
docker exec -it redis-node-1 /bin/bash
redis-cli --cluster create 192.168.95.20:6381 192.168.95.20:6382 192.168.95.20:6383 192.168.95.20:6384 192.168.95.20:6385 192.168.95.20:6386 --cluster-replicas 1
–cluster-replicas 1 表示为每个master创建一个slave节点
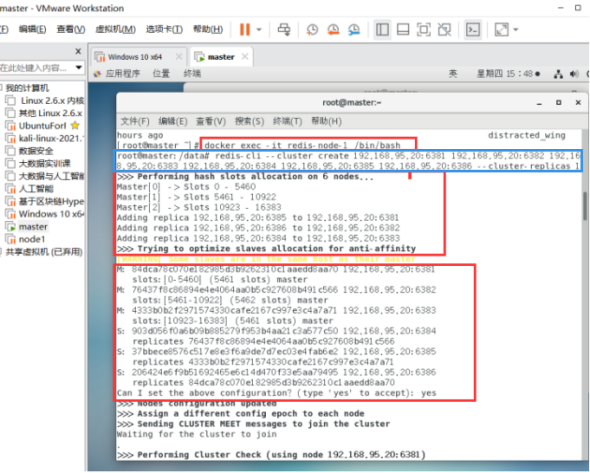
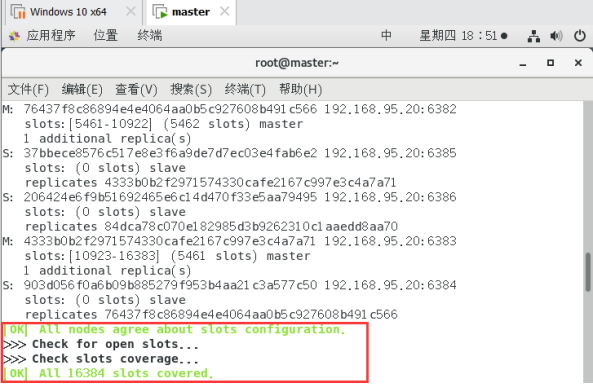
链接进入6381作为切入点,查看集群状态:
redis-cli -p 6381
cluster info
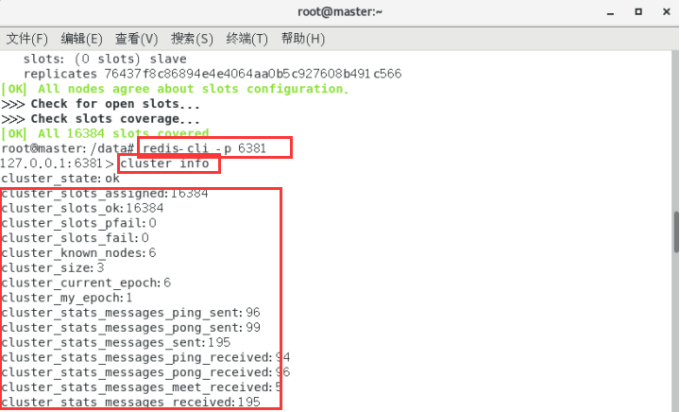
cluster_state: ok状态表示集群可以正常接受查询请求。fail 状态表示,至少有一个哈希槽没有被绑定(说明有哈希槽没有被绑定到任意一个节点),或者在错误的状态(节点可以提供服务但是带有FAIL 标记),或者该节点无法联系到多数master节点。.
cluster_slots_assigned: 已分配到集群节点的哈希槽数量(不是没有被绑定的数量)。16384个哈希槽全部被分配到集群节点是集群正常运行的必要条件.
cluster_slots_ok: 哈希槽状态不是FAIL 和 PFAIL 的数量.
cluster_slots_pfail: 哈希槽状态是 PFAIL的数量。只要哈希槽状态没有被升级到FAIL状态,这些哈希槽仍然可以被正常处理。PFAIL状态表示我们当前不能和节点进行交互,但这种状态只是临时的错误状态。
cluster_slots_fail: 哈希槽状态是FAIL的数量。如果值不是0,那么集群节点将无法提供查询服务,除非cluster-require-full-coverage被设置为no .
cluster_known_nodes: 集群中节点数量,包括处于握手状态还没有成为集群正式成员的节点.
cluster_size: 至少包含一个哈希槽且能够提供服务的master节点数量.
cluster_current_epoch: 集群本地Current Epoch变量的值。这个值在节点故障转移过程时有用,它总是递增和唯一的。
cluster_my_epoch: 当前正在使用的节点的Config Epoch值. 这个是关联在本节点的版本值.
cluster_stats_messages_sent: 通过node-to-node二进制总线发送的消息数量.
cluster_stats_messages_received: 通过node-to-node二进制总线接收的消息数量.
链接进入6381作为切入点,查看节点状态:
cluster nodes:提供了当前连接节点所属集群的配置信息,信息格式和Redis集群在磁盘上存储使用的序列化格式完全一样(在磁盘存储信息的结尾还存储了一些额外信息)
cluster nodes
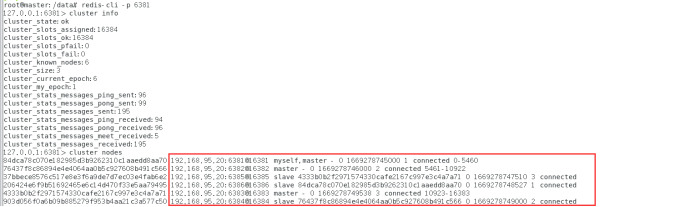
至此,3主3从redis集群完成!
4.主从容错切换迁移
主从切换是指某个master不可用时,它的其中一个从节点升级为master的操作。
通过投票机制来判断master是否不可用,参与投票的是所有的master,所有的master之间维持着心跳,如果一半以上的master确定某个master失联,则集群认为该master挂掉,此时发生主从切换。
通过选举机制来确定哪一个从节点升级为master。选举的依据依次是:网络连接正常->5秒内回复过INFO命令->10*down-after-milliseconds内与主连接过的->从服务器优先级->复制偏移量->运行id较小的。选出之后通过slaveif no ont将该从服务器升为新master。
通过配置文件参数【cluster-node-timeout】指定心跳超时时间,默认是15秒。
先链接6381redis节点:
redis -cli -p 6381
设置key时候出现error:

加入参数-c,优化路由:
redis-cli -p 6381 -c
set k1 v-cluster1
set k2 v-cluster2
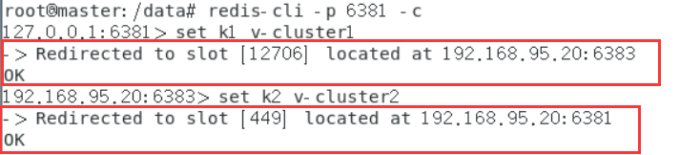
查看集群信息:
redis-cli --cluster check 192.168.95.20:6381

进行容错切换迁移:
主6381和从机切换,先停止主机6381
6381主机停了,对应的真实从机上位
6381作为1号主机分配的从机以实际情况为准,具体是几号机器就是几号
再次查看集群信息
先还原之前的3主3从:
docker start redis-node1
docker stop redis-node-5
docker start redis-node-5
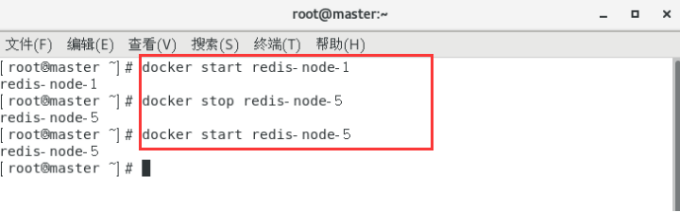
中间需要等待一会儿,docker集群重新响应。
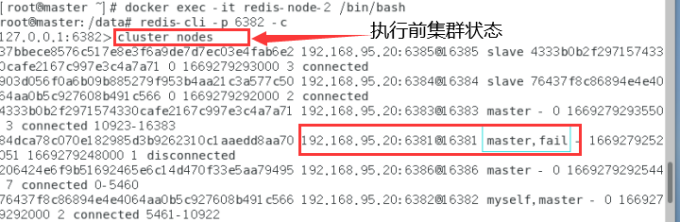
执行前的集群状态:
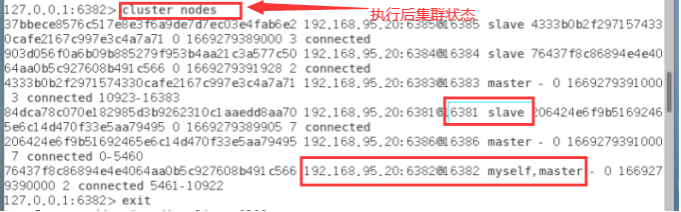
执行后的集群状态:
docker start redis-node-1

再停6385

查看集群节点状态:
cluster nodes
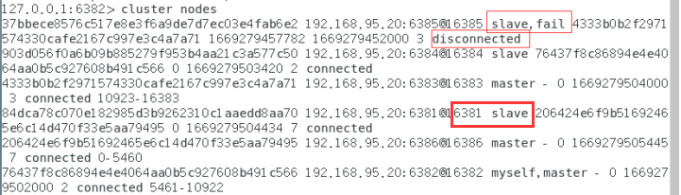
再次启动6385集群
docker start redis-node-5
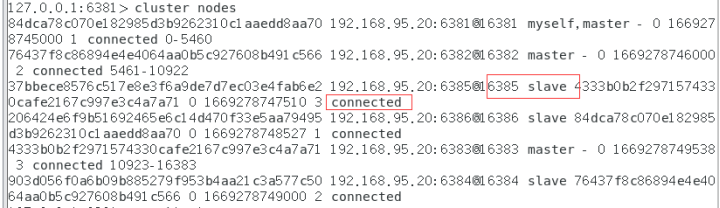
Redis Cluster:
为了支持高可用,Redis提供了集群部署方案,当master发生故障时,能及时进行主从切换。
redis-cli 使用参数【-c】连接集群中任意一个节点,无论是主还是从,都没有任何区别,都能访问整个集群。
Jedis使用JedisCluster时也一样,配置一个节点即可访问整个集群,配置多个更安全。
这是因为Redis集群是去中心化的,每个节点都维护着集群所有节点的信息。
查看集群状态:
redis-cli --cluster check 192.168.95.20:6381
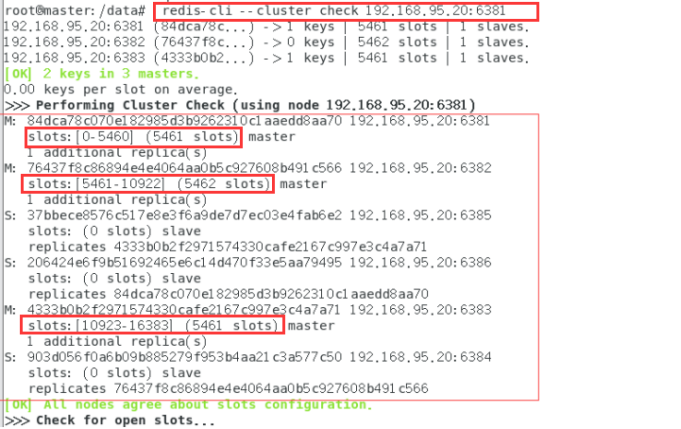
主从容错切换迁移完成!
主从容错切换迁移的优点:
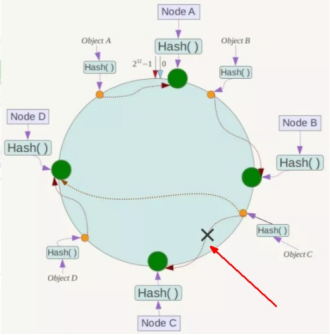
一致性哈希算法的容错性:
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
5.主从缩容
先开始主从扩容,后面主从缩容:
扩容原理:
1、redis cluster可以实现对节点的灵活上下线控制
2、3个主节点分别维护自己负责的槽和对应的数据,如果希望加入一个节点实现扩容,就需要把一部分槽和数据迁移和新节点
3、每个master把一部分槽和数据迁移到新的节点
新节点刚开始都是master节点,但是由于没有负责的槽,所以不能接收任何读写操作,对新节点的后续操作,一般有两种选择:
1、从其他的节点迁移槽和数据给新节点
2、作为其他节点的slave负责故障转移
slot迁移说明:
1、迁移过程是同步的,在目标节点执行restore指令到原节点删除key之间,原节点的主线程处于阻塞状态,直到key被删除成功
2、如果迁移过程突然出现网路故障,整个slot迁移只进行了一半,这时两个节点仍然会被标记为中间过滤状态,即"migrating"和"importing",下次迁移工具连接上之后,会继续进行迁移
3、在迁移过程中,如果每个key的内容都很小,那么迁移过程很快,不会影响到客户端的正常访问
4、如果key的内容很大,由于迁移一个key的迁移过程是阻塞的,就会同时导致原节点和目标节点的卡顿,影响集群的稳定性,所以,集群环境下,业务逻辑要尽可能的避免大key的产生
什么是哈希槽分区:
1、哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
2、解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据
3、槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
4、哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
一致性哈希算法的扩展性扩展性:
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
新建6387、6388两个节点
先新建对应redis目录:
mkdir -p /data/redis/share/redis-node-7:/data
mkdir -p /data/redis/share/redis-node-8:/data
新建节点后启动容器实例:
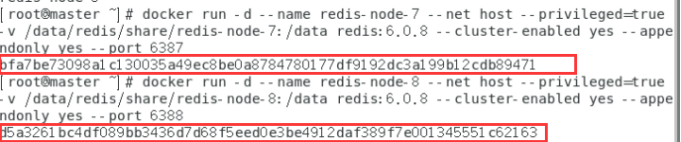
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
进入6387容器实例内部:
docker exec -it redis-node-7 /bin/bash

将新增的6387节点(空槽号)作为master节点加入原集群:
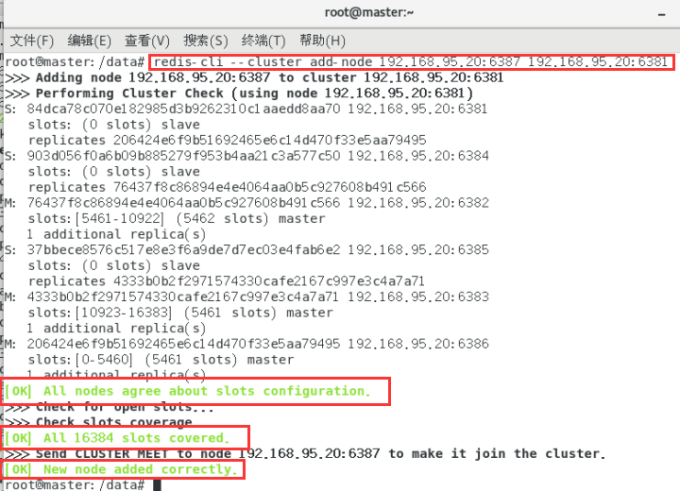
redis-cli --cluster add-node 192.168.95.20:6387 192.168.95.20:6381
6387 就是将要作为master新增节点
6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
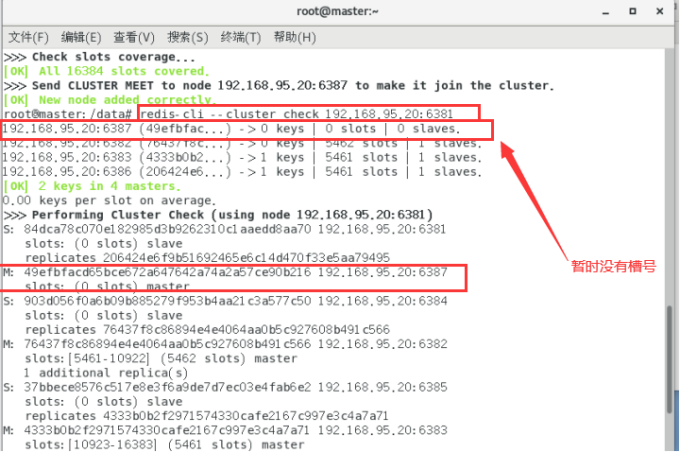
检查集群情况第1次
redis-cli --cluster check 192.168.95.20:6381
重新分派槽号:
redis-cli --cluster reshard 192.168.95.20:6381
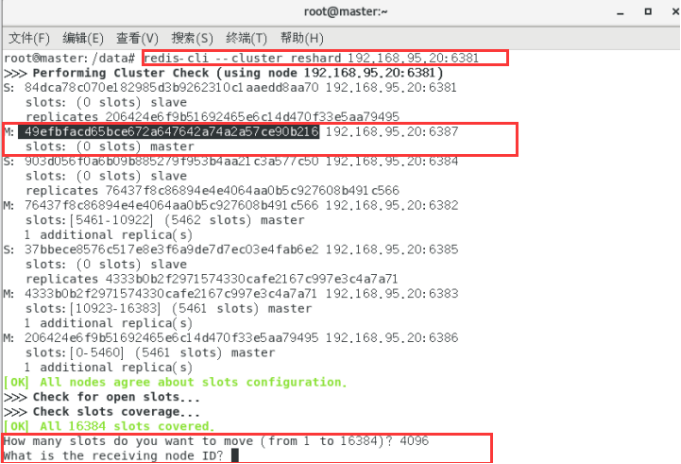
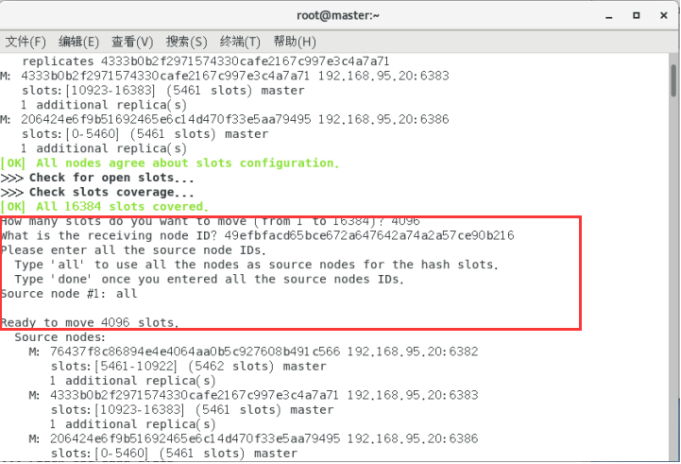
检查集群情况第2次:
redis-cli --cluster check 192.168.95.20:6381
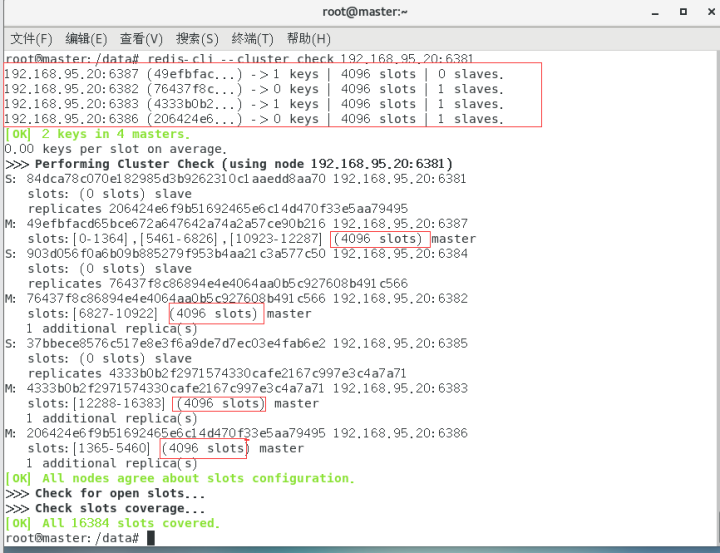
槽号分派说明:
重新分配成本太高,所以从6382/6383/6386三个旧节点分别匀出1364个坑位给新节点6387
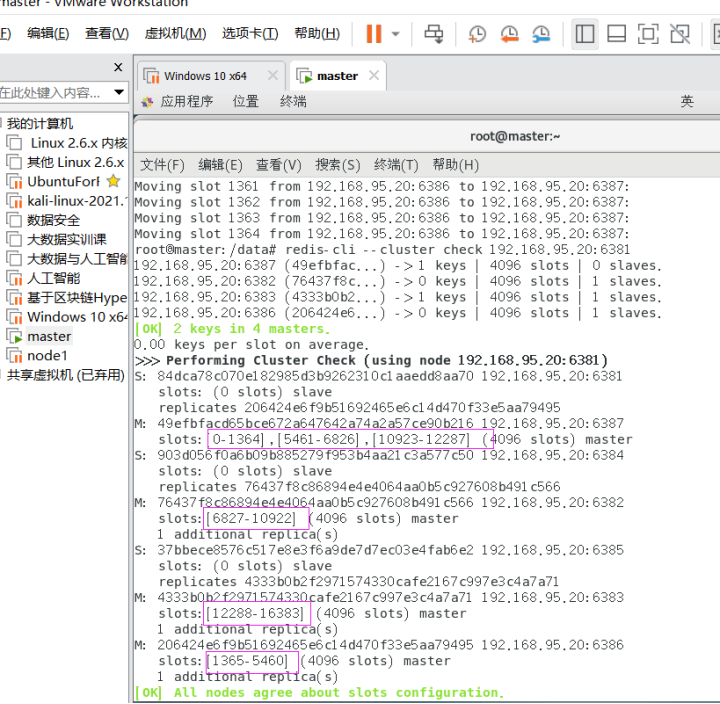
为主节点6387分配从节点6388:
命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
6387的编号:49efbfacd65bce672a647642a74a2a57ce90b216
redis-cli --cluster add-node 192.168.95.20:6388 192.168.95.20:6387 --cluster-slave --cluster-master-id 49efbfacd65bce672a647642a74a2a57ce90b216
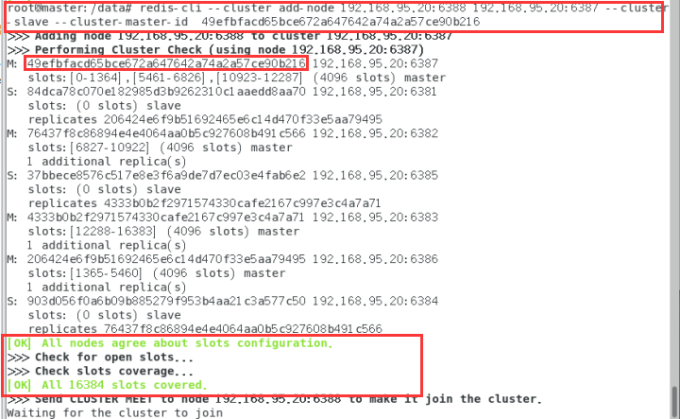
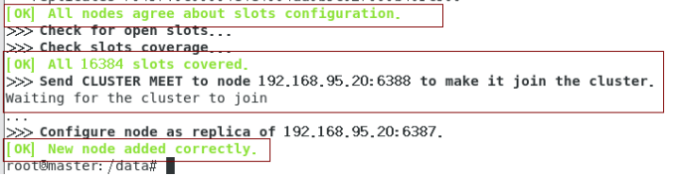 检查集群情况第3次:
检查集群情况第3次:
redis-cli --cluster check 192.168.95.20:6382

开始主从缩容:
缩容原理:
1、如果下线的是slave,那么通知其他节点忘记下线的节点
2、如果下线的是master,那么将此master的slot迁移到其他master之后,通知其他节点忘记此master节点
3、其他节点都忘记了下线的节点之后,此节点就可以正常停止服务了
主从缩容目的:6387和6388下线
检查集群情况获得6388的节点ID:
redis-cli --cluster check 192.168.95.20:6382
从机6388节点ID:eb9c733c48279b5512ea4e7ffc3dbb7f34581e0a
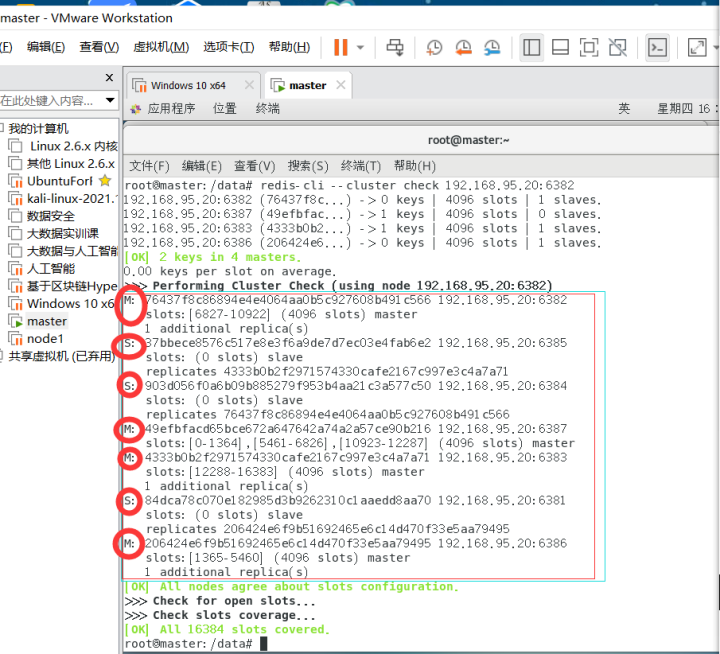
将6388删除 从集群中将4号从节点6388删除

命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID
redis-cli --cluster del-node 192.168.95.20:6388 eb9c733c48279b5512ea4e7ffc3dbb7f34581e0a

检查一下发现,6388被删除了,只剩下7台机器了:
redis-cli --cluster check 192.168.95.20:6382
将6387的槽号清空,重新分配,本例将清出来的槽号都给6382:
redis-cli --cluster reshard 192.168.95.20:6382
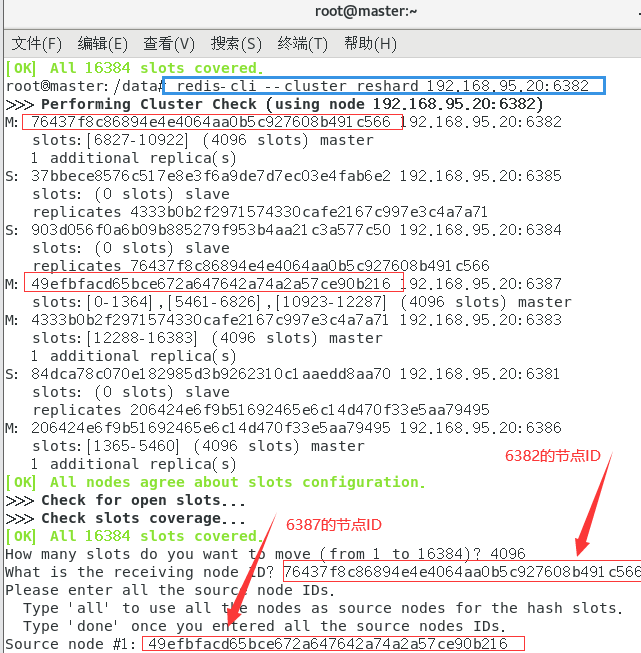
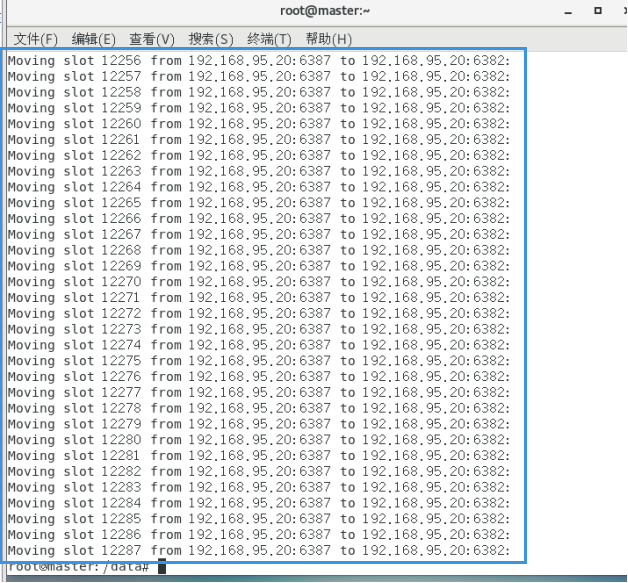
检查集群情况第二次:
redis-cli --cluster check 192.168.95.20:6382
4096个槽位都指给6382,它变成了8192个槽位,相当于全部都给6382了。
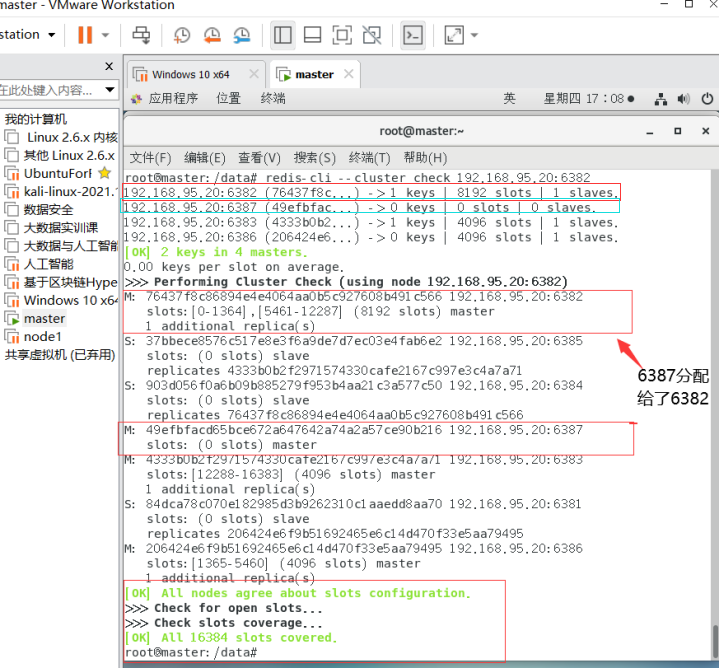
将6387删除:
命令:redis-cli --cluster del-node ip:端口 6387节点ID
redis-cli --cluster del-node 192.168.95.20:6387 49efbfacd65bce672a647642a74a2a57ce90b216

检查集群情况第三次:
redis-cli --cluster 192.168.95.20:6381
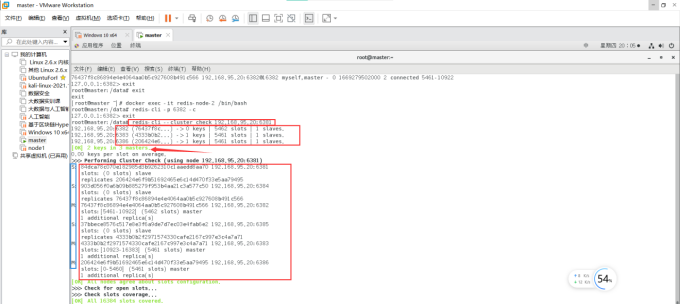
由图中可以看出Redis集群主从缩容完成!
至此Redis集群主从扩容与缩容都已经完成。
这里关于部署Redis集群的总结:
1、为了在节点数目发生改变时尽可能少的迁移数据
2、将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
3、而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
一致性哈希算法优点:
1、一致性哈希算法的容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
2、一致性哈希算法的扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
一致性哈希算法缺点:
1、一致性哈希算法的数据倾斜问题
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。
哈希槽分区:
1、哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
2、解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
3、槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
4、哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
虽然最近很忙,但我还是会抽时间给大家写一些关于大数据方面的内容,同时我也会学习其它领域的相关知识。
追风赶月莫停留,平芜尽处是春山















 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











