







一、NeoCognitron
早在 1906 年,Sherrington1 首次使用“感受野”一词用于描述在狗身上引起搔扒反射实验中的皮肤区域。在 1938 年,Hartline 将“感受野”一词用于单个细胞中(该实验中指青蛙视网膜细胞),此后,该词逐渐扩展到听觉、触觉、视觉等多个领域中。在 20 世纪五六十年代,Hubel 和 Wiesel23 通过研究猫和猴子的视觉感受野提出,在视觉系统某一层细胞的感受野是由视觉系统较低层的细胞的输入而成,并且通过这种层级方式,可以组合小而简单的感受野,形成大而复杂的感受野。在 1968 年的论文3中提出了大脑中两种基本的视觉细胞:简单细胞(simple cells,输出其感受野中具有特定方向最大化的直边) 和复杂细胞(complex cells,具有较大的感受野,它对边缘在感受野中特定位置不敏感)。 ————— 以上内容参照自维基百科45
在 1980 年,Kunihiko Fukushima 提出了一种称为 “neocognitron” 的模式识别机制,几乎就是 Hubel 和 Wiesel 理论的仿生模型,Hubel 和 Wiesel 实验表明,视觉皮层的网络结构形式是:LGB(侧膝体)—> 简单细胞 —> 复杂细胞 —> 低阶超复杂细胞 —> 高阶超复杂细胞。低阶超复杂细胞与高阶超复杂细胞之间的神经网络结构类似于简单细胞与复杂细胞之间的网络结构。而且在这种层次结构中,处于较高阶段的细胞通常更倾向于选择性地对刺激模式的更复杂特征作出反应,同时具有更大的接收场,并且对刺激模式位置的变化更不敏感。
在该仿生系统中,作者拓展了 Hubel 和 Wiesel 的层次结构,并假设在更高层中依然存在这种层次结构,处于最高阶的细胞只对特定的刺激模式做出反应,而不受刺激的位置或大小所影响。这就是现代 CNN 网络中卷积层+池化层的最初范例及灵感来源。
1、NeoCognitron 需要解决的问题
在传统的一些模式识别系统上,已经开发了很多类似光学字符识别系统,这些系统的识别速度远远超过人类,但是识别精度却远远不及人类。以普通的多层前馈神经网络为例,尽管也可以提取一些特定模式,但是对于模式的位置及其敏感,需要对输入模式的位置预先进行规范化(例如,对图片进行裁剪,使字符处于图片中心位置等)。然而,如果输入模式中带有一定的噪声或几何失真,则很难对位置进行规范化,因此,该系统的重心就是要解决模式识别中对输入模式的位置变化不敏感问题。
2、NeoCognitron 结构简介
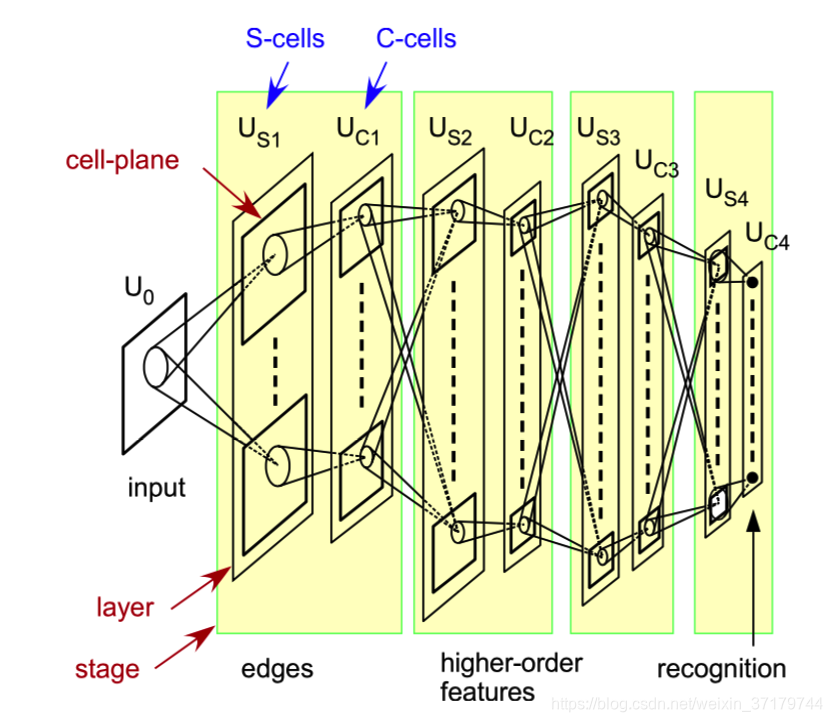
【图1】
Neocognitron 是由一些列小模块级联组成,它的输入层是 U0。U0是一个二维数组,表示感受器细胞。每个模块由分别由 S 层和 C 层组成,分别对应 Hubel 和 Wiesel 理论中的 S 细胞和 C 细胞。如上图所示,图中共有 4 个模块,Usl表示第 l 个模块的 S 层,同理 Ucl 表示第 l个模块的 C 层。
在一个 S 层或 C 层内部,根据它们对感受野内特定的刺激模式的响应,可以把它们组织成一些子块,如图中的一些小矩形框,我们将其称之为细胞平面,在 S 层的称之为 S 平面,在 C 层的称为 C 平面,同一个平面中的细胞输入有相同的空间分布,而只是空间位置上有变化。如下图所示,右侧平面中的每个细胞输入实际都来自前面平面中一个“T”型的空间分布的细胞。
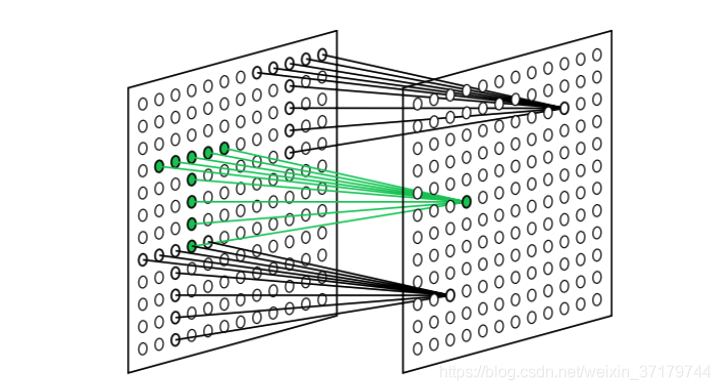
【图2】
这种层级架构模式,在更深层次的层上,每个细胞的感受野都会被放大,所以随着层级的加深,每个细胞平面中的细胞数目也会逐级减少,在最后一个 C 层,每个细胞平面中的一个细胞其感受野已经可以覆盖整个输入空间,实际上,最后一个 C 层,每个细胞平面中也只含有一个细胞。
2.1、S 细胞与 C 细胞的作用
S 细胞的作用相当于一个特征提取细胞,用于从输入空间中提取特定的模式。由于一个 S 平面中的 S 细胞的输入空间分布相同,而只是位置发生变化,如图 2 所示。所以对于一个特定的模式,无论在空间中的什么位置都将会检测到,从而解决了输入模式的位置变化问题。而不同的 S 平面中的 S 细胞将检测不同模式的特征,这是很直观的。而且位于低层的细胞通常提取一些简单的模式,而高层的细胞则可以组合简单的模式形式较为复杂的模式。
由于 S 细胞与 C 细胞之间的连接不可改变,而且当连接区域中只要有一个 S 细胞产生较大的输出,C 细胞就会做出强烈的响应,因此这种模式可以容忍一些特征的轻微形变或大小缩放。
3、NeoCognitron 工作原理图
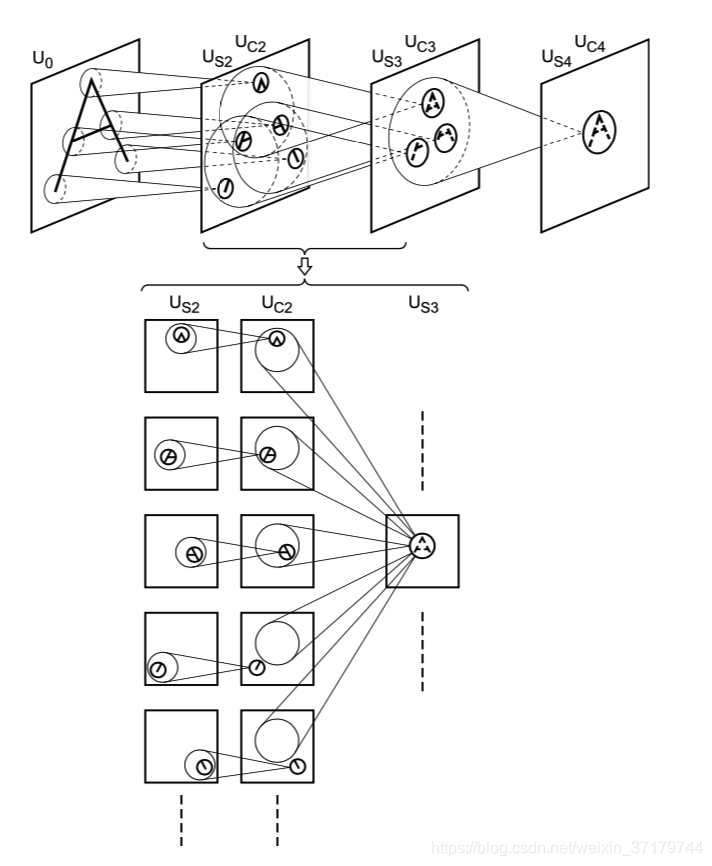
【图3】
上图中,网络欲识别字母 “A”,因为字母 “A” 顶部有 “^” 形状,则 S 平面中靠近中间上部的细胞有较大的输出,如图下部分放大图例所示。后面的 C 层则连接到 S 平面中的一组细胞,第 4、5 两个 S 平面提取的“/” 和 “\”没有出现在感受野中,故而相应的 C 平面没有响应。Us2 通过组合"^"、"/-" 和 “-\” 实际以及得到形似 “A” 的特征。需要注意的是,当这三个特征的空间位置超出可允许范围内,则停止响应。也就是说,网络可以容忍轻微的形变或缩放,但不能无限度形变或缩放。如下图所示: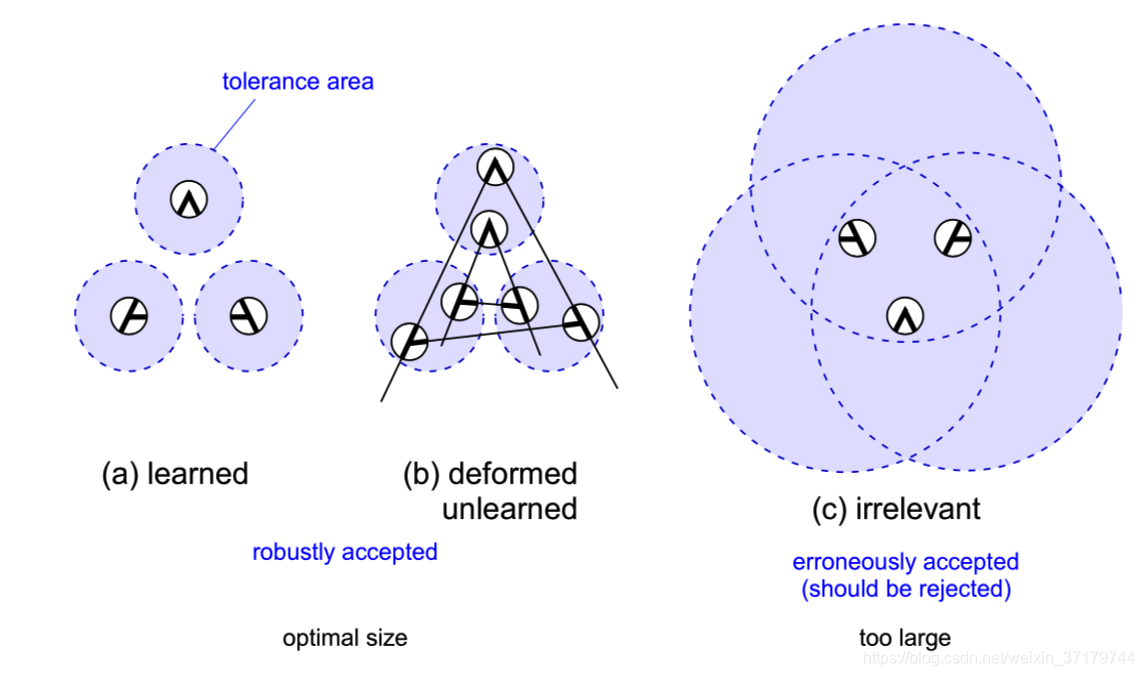
在上图中,圆形区域内为可容忍区域,如 (a) 所示,这是最一般的形式,在容忍区域内,我们可以接受一些模式的位移或变形(如旋转),这可以使我们的模型更加鲁棒,如 (b)。然而一旦容忍区域增大,我们则可能响应错误的模式,如 (c) 所示。
4、自组织学习机制
NeoCognitron 采用的是一种自组织学习机制,它是一种无监督学习机制。其核心原理就是在输入层重复的输入一系列特定的刺激模式,迫使 S 平面内响应最为强烈的细胞加强其输入连接,逐渐使得该细胞只对该模式有所响应,并以此作为特定模式的学习过程。
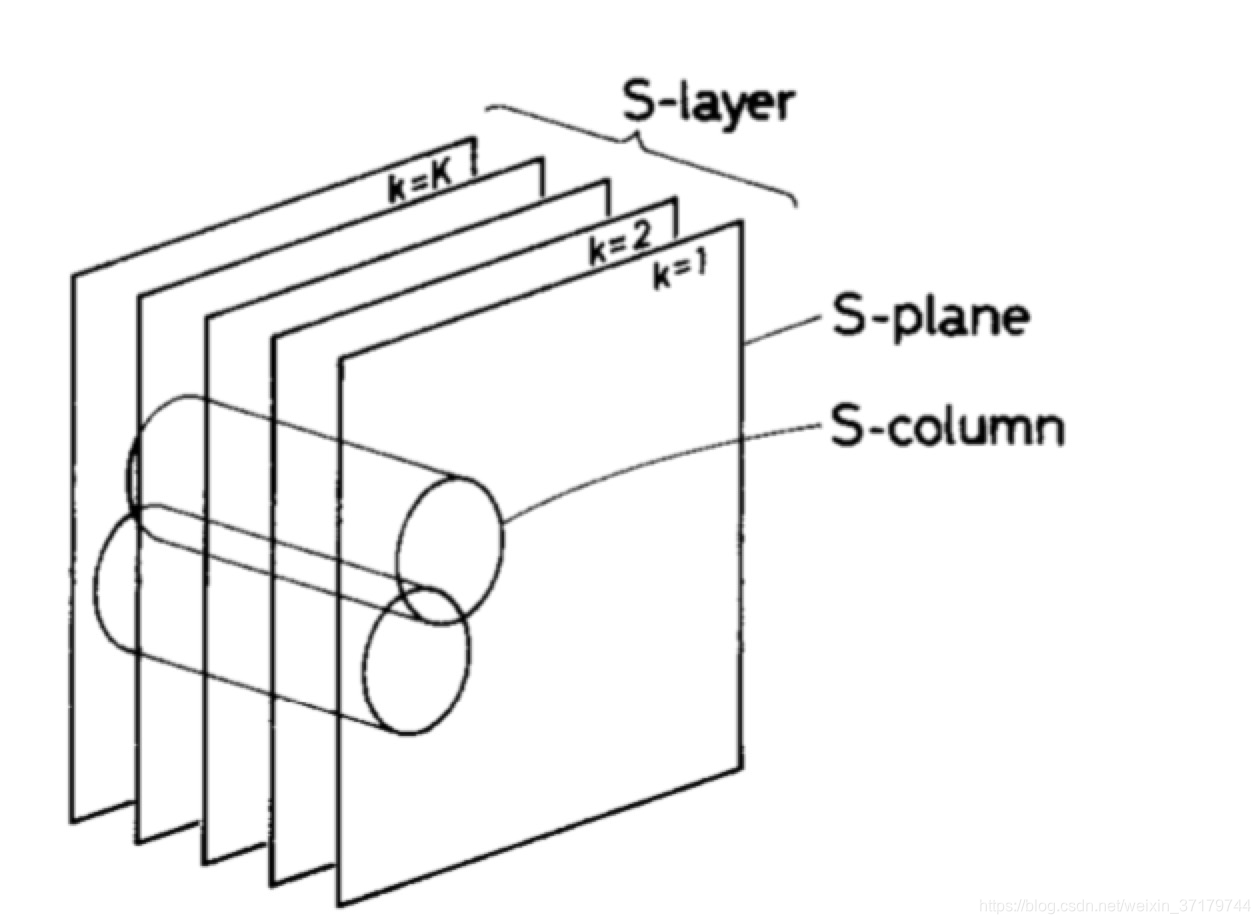
【图 5】
图上图所示,在 S 层中,如果我们把 S 平面堆叠起来,则同一位置的不同 S 平面区域组成一个柱状体,我们称为 S 柱。一个 S 柱内同一位置的细胞具有相同的感受野。因此对于特定的刺激模式,对任意一个平面我们将挑出该平面内具有最大响应值的细胞作为该平面的代表,并从中再选择少数几个平面最为最终的细胞代表。例如图4(a),对于给定的字母“A”,S 层的 5 个平面内均有一个细胞具有最大响应值,而我们只选择 1、2、3 平面作为代表。其三个细胞分别检测“^”、“/-” 和 “-\”。而其他平面可用于响应其他模式。如果一个平面对多种模式均具有较大响应,则只选择为具有最大响应的模式的代表。这样可以保证,一个平面只对一种特定模式具有响应,对两种及以上的组合模式不具有响应。被选择为代表的细胞,其输入连接会被增强,而该层的所有细胞的连接强度都会复制代表细胞的连接强度,而仅仅是空间位置上的位移。
这样,在对某一特定模式,重复给出多次,并试图改变刺激模式的位移、轻微扭曲、缩放以及添加噪音等干扰,都会强化网络对这特定模式的响应,以提高网络识别的鲁棒性。
转载于:https://blog.csdn.net/weixin_37179744/article/details/99647033

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









