






一、简单理解感受野:可以参考神经网络的直观理解:举例及比喻-CSDN博客第四部分
重申: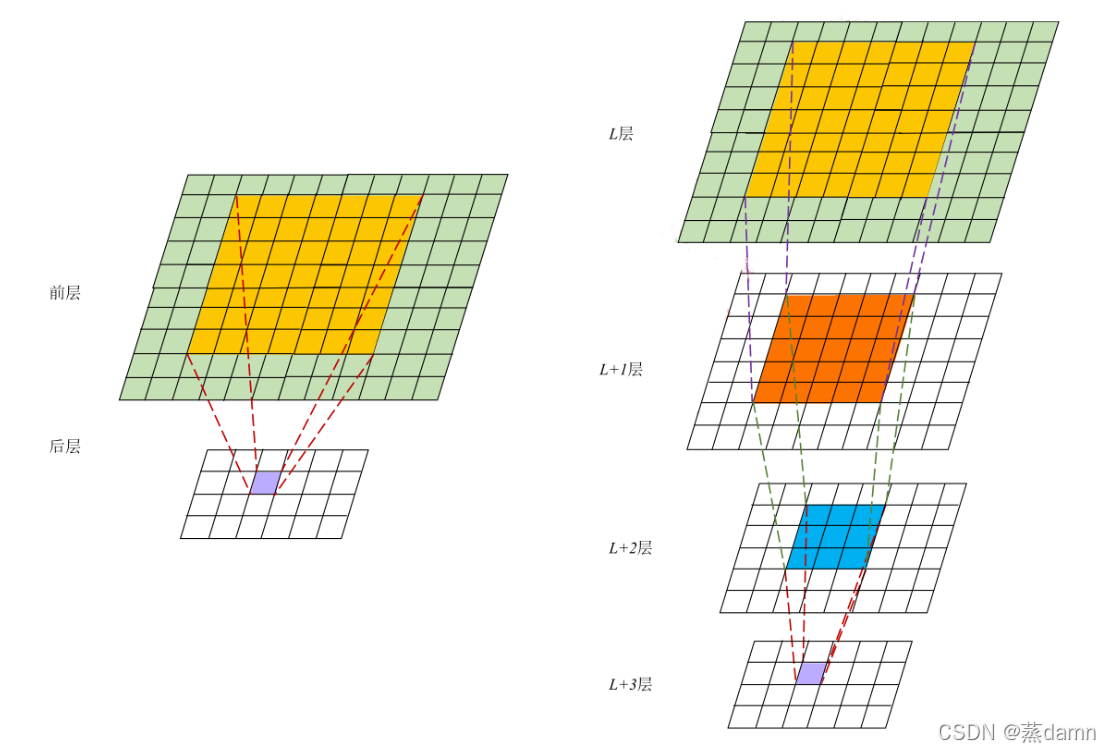

二:感受野溢出:
当某一层的感受野超过输入图像尺寸(如128×128)时,称为感受野溢出。此时,神经元可能覆盖到图像边缘外的填充区域(如零填充)。也就是两个矛盾:
理论需求:希望网络具备全局感知能力,避免局部偏见。
实际影响:引入无效计算(零填充区域无真实信息),增加参数冗余。
仍以手写数字识别为例、如果我们通过堆叠卷积核继续加深网络、我们会发现更大的网络似乎没有意义,也就是说此时加深网络似乎从感受野的角度来说似乎是盲目的?还会引入许多无用的噪声、增加参数量。
 黑色边框为感受野溢出示意
黑色边框为感受野溢出示意
这部分是因为手写数字识别的例子过于简单、在实现上也是通过LeNet这种简单的神经网络实现的。
覆盖原图就够了么?
三、适当更大的感受野可以提高预测准确率、感受野达到输入尺度是基本
| ResNet 网络深度 | 感受野大小 | Top-1 错误率 (1-crop) | Top-5 错误率 (1-crop) |
| 18 | 627 | 30.26 | 10.92 |
| 34 | 1091 | 26.70 | 8.58 |
| 50 | 619 | 23.85 | 7.13 |
| 101 | 1163 | 22.63 | 6.44 |
| 152 | 1643 | 21.69 | 5.94 |
*相同情况下更深的网络感受野更大。
*ResNet50采用了不一样的网络架构:瓶颈结构(bottleneck structure),这种结构在增加网络深度的同时,对感受野的扩张有一定影响。
适当更大的感受野可以提高预测准确率的原因:
1、有效感受野(ERF):
传统感受野计算仅考虑理论覆盖范围,而有效感受野强调实际影响神经元激活的输入区域权重分布。研究表明:
-
高斯衰减现象:中心像素对激活的贡献远大于边缘像素。
-
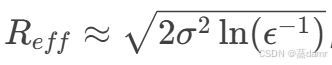
有效感受野半径 Reff :σ为卷积层累积标准差,ε为贡献阈值(如0.01)。
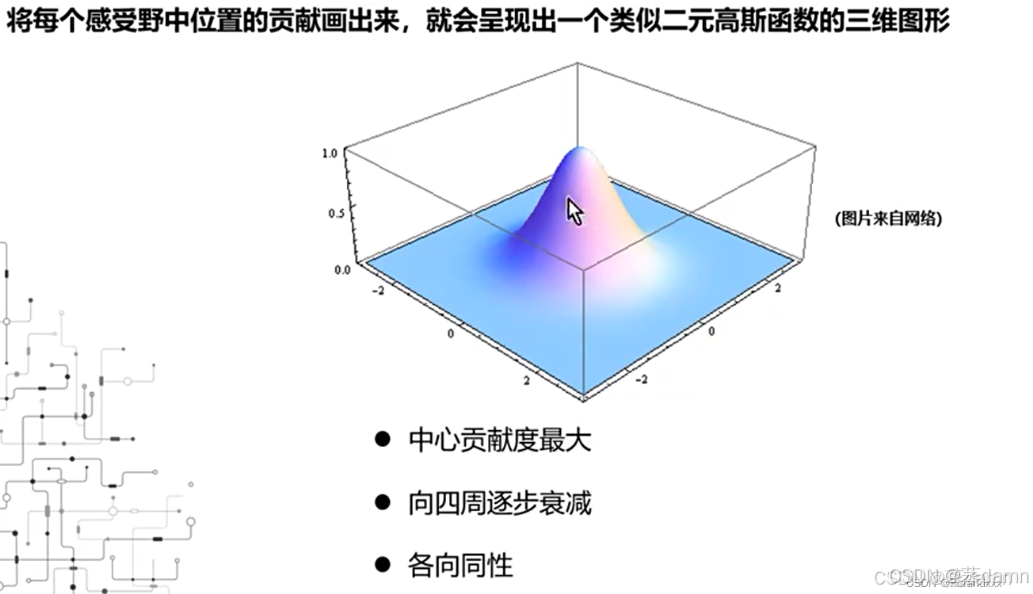 图源网络
图源网络
简单理解这是因为
-
权重分布不均:卷积核中心区域的权重通常对输出影响更大(类似高斯衰减)。
-
激活函数过滤:ReLU等非线性函数会抑制部分输入,导致边缘区域贡献归零。
如图:图像边框为我们计算的理论感受野theoretical RF 图源@CSDN Joney Feng
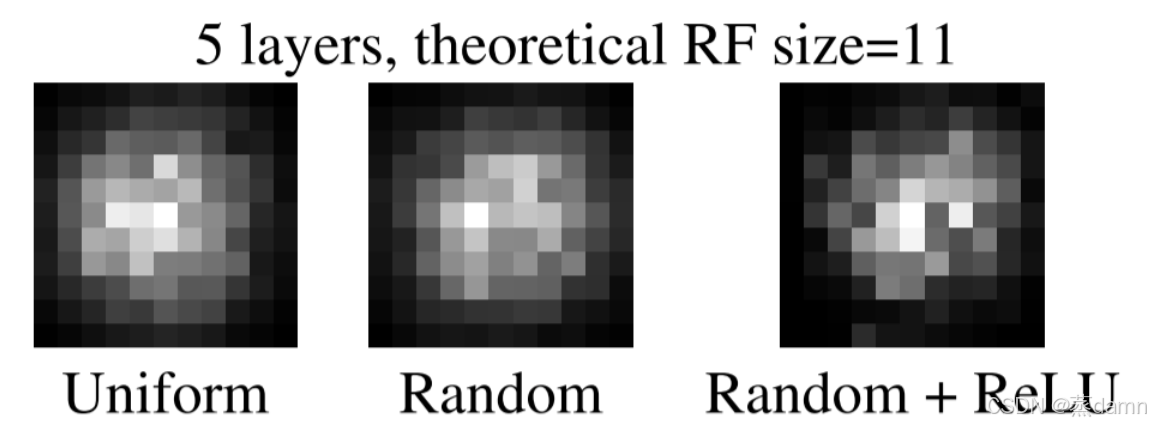



不同初始化方法和激活函数对越来越深的网络和有效感受野的影响不同、但都无法达不到理论感受野
结论:有效感受野的存在告诉我们:仅仅达到输入尺度的感受野是无法将全部输入作为有效输入的。
2、更大的感受野提供了特征组合机制
示例:在人脸检测中,浅层检测边缘,中层组合成眼睛、鼻子等部件,深层识别完整人脸。这种层级组合依赖逐渐扩大的感受野,以融合上下文信息。
随着网络深度增加,特征从局部到全局逐步组合:
-
浅层网络(前几层):提取低级特征,如边缘、颜色、纹理。
-
中层网络:组合低级特征为复杂模式(如几何形状、部件)。
-
深层网络:捕获高级语义信息(如物体类别、整体结构)。
结论:大感受野使模型理解图像整体结构,而非局限于局部细节。
四、如何平衡理论感受野(RF)和有效感受野(ERF)?
那是不是说,只有更复杂的、具有更高维特征的任务才需要相应加深网络深度、不断扩大感受野呢?是不是要设计相应深度的网络来匹配相应复杂度的特征学习任务呢? 那是不是RF越大才能保证ERF越大?
层深不变时扩大理论感受野:
-
小卷积核堆叠(如VGG的3×3卷积):深层叠加小核可模拟大核效果,参数更少。
-
空洞卷积:通过间隔采样扩大感受野,不增加参数量。
-
深度可分离卷积:分离空间与通道卷积,大幅减少计算成本。
-
池化与步长调整:通过下采样快速扩大感受野,但需避免信息丢失。
从“盲目扩大”到“精准覆盖 、提升ERF的关键方法
| 方法 | 原理说明 | 适用场景 |
|---|---|---|
| 残差连接 | 跨层传递原始输入,避免边缘信息被非线性过滤 | 所有深度网络 |
| 可变形卷积 | 动态调整采样位置,使ERF向信息丰富区域扩展 | 目标检测/分割 |
| 高斯初始化增强 | 刻意增大卷积核边缘权重初始化值 | 浅层网络 |
| 注意力机制 | 通过空间注意力图显式强化边缘区域贡献 | 分类/生成任务 |
指导分类、检测、分割网络的设计:
网络深度与感受野的设计本质是在任务需求、计算成本、信息完整性之间寻找平衡点。
也就是说如果我们在设计网络架构时可以考虑按照:理论感受野—>有效感受野—>动态感受野调整(如注意力机制)
比如:
-
分类任务:最后一层感受野应略大于输入尺寸。
-
密集预测(如分割):需保持中等感受野以保留局部细节。
感受野是CNN理解图像语义的基础,其大小直接影响模型的全局感知能力。通过合理设计网络深度、卷积核和池化策略,可在控制参数量的前提下实现最优感受野覆盖。动态感受野调整(如注意力机制)和更高效的扩张方法。

















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









