







 激活函数在神经网络中引入非线性,对比了Sigmoid、tanh、ReLU和Leaky ReLU的优缺点。Sigmoid因饱和导致梯度消失,非零均值影响收敛;tanh解决部分问题但仍有饱和;ReLU速度快但有Dead ReLU问题;Leaky ReLU通过微小负梯度缓解Dead ReLU。
激活函数在神经网络中引入非线性,对比了Sigmoid、tanh、ReLU和Leaky ReLU的优缺点。Sigmoid因饱和导致梯度消失,非零均值影响收敛;tanh解决部分问题但仍有饱和;ReLU速度快但有Dead ReLU问题;Leaky ReLU通过微小负梯度缓解Dead ReLU。
激活函数的作用:
为了增加神经网络模型的非线性,将一个很大范围的实数,映射到一个很小的范围之内。
为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与 没有隐藏层效果相当,这种情况就是 最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。
激活函数的比较:
Sigmod函数:
公式:
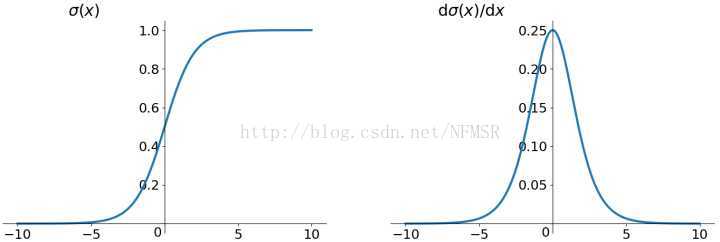
图像:
优劣:
Sigmoid 非线性激活函数,sigmoid函数输入一个实值的数,然后将其压缩到0~1的范围内。特别地,大的负数被映射成0,大的正数被映射成1。
而现在sigmoid已经不怎么常用了,主要是因为它有两个缺点:
- Sigmoids saturate and kill gradients. (Sigmoid饱和and 梯度消失情况)Sigmoid容易饱和,并且当输入非常大或者非常小的时候,神经元的梯度就接近于0了,从图中可以看出梯度的趋势。这就使得我们在反向传播算法中反向传播接近于0的梯度,导致最终权重基本没什么更新,我们就无法递归地学习到输入数据了。另外,你需要尤其注意参数的初始值来尽量避免saturation(饱和)的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉(导数为0,梯度消失,梯度下降非常慢),这会导致网络变的很难学习。
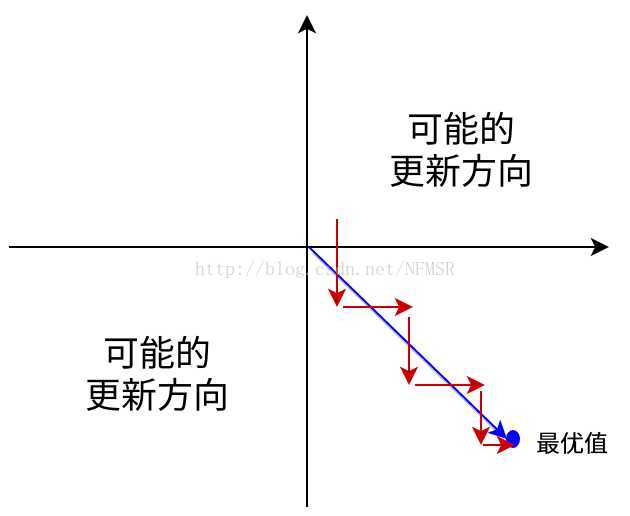
- Sigmoid outputs are not zero-centered. Sigmoid 的输出不是0均值的(不是以0为中心),这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in f=wTx+b ),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。 (这里有点不太理解)
这会导致如下图红色箭头所示的阶梯式更新,这显然并非一个好的优化路径。深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。
当然了,如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









