









 本文介绍了BLEU,一种双语互译质量评估工具,通过比较机器翻译与人工翻译的n-gram匹配度,快速评估翻译效果。文章详细阐述了BLEU的评估原理、改进方法和其在考虑流畅性与准确性的权衡,以及其优缺点和常见应用场景。
本文介绍了BLEU,一种双语互译质量评估工具,通过比较机器翻译与人工翻译的n-gram匹配度,快速评估翻译效果。文章详细阐述了BLEU的评估原理、改进方法和其在考虑流畅性与准确性的权衡,以及其优缺点和常见应用场景。
参考链接:https://zhuanlan.zhihu.com/p/338488036
文章目录
主要是为了解决如何判断模型翻译语句的质量的问题。
BLEU 可以低成本,快速的实现对模型结果的评估,从而促进模型架构的发展
BLEU的含义
BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。
用于评估机器翻译质量的好坏。
设计思想:
机器翻译结果越接近专业人工翻译的结果,则越好。
BLEU算法实际上就是在判断两个句子的相似程度,即拿这个句子的标准人工翻译与机器翻译的结果作比较。
BLEU 并不是拿一个对应的参考翻译来做比较,而是多参考翻译,最后算出一个综合分数。 其分数值越高越好。
优点:
方便、快速、结果有参考价值
缺点:
- 不考虑语言表达(语法)上的准确性;
- 测评精度会受常用词的干扰;
- 短译句的测评精度有时会较高;
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
BLEU如何进行评估的
BLEU的评估算是也是在不断改进的。
最先提出的算法是这样的:
两个句子,S1和S2,S1里头的词出现在S2里头越多,就说明这两个句子越一致。、
改进之后的是这样的:
考虑了the, on这样的词,所以极易造成翻译结果低劣评分结果却贼高的情况。
改进的第三种方法:BLEU多元精度(n-gram precision)

改进的n-gram精度得分可以用来衡量翻译评估的充分性和流畅性两个指标:一元组属于字符级别,关注的是翻译的充分性,就是衡量你的逐字翻译能力; 多元组上升到了词汇级别的,关注点是翻译的流畅性,词组准了,说话自然相对流畅了。所以我们可以用多组多元精度得分来衡量翻译结果的。
关于n-gram的另一种解释:
根据n-gram可以划分成多种评价指标,常见的指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为n
BLEU-1衡量的是单词级别的准确性,更高阶的bleu可以衡量句子的流畅性。
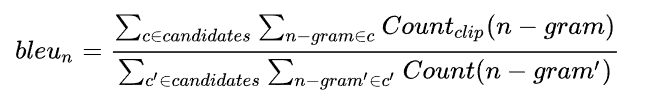


For example:
candidate: the cat sat on the mat
reference: the cat is on the mat
那么各个bleu的值如下:
就 bleu2 ,对 candidate中的5个词,{the cat,cat sat,sat on,on the,the mat} ,查找是否在reference中,发现有3个词在reference中,所以占比就是0.6
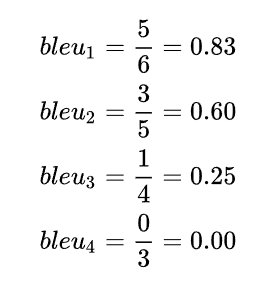
更多详情:
https://zhuanlan.zhihu.com/p/338488036
https://zhuanlan.zhihu.com/p/223048748



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











