







一、需求
假设我目前有很多PDF文件,我需要找到含有某些关键词的PDF,并把哪些PDF含有关键字导出。(这些PDF里有的PDF含有我需要的关键词,有些PDF不含有)虽然 ctrl+F 可以完成搜索功能,但当pdf非常多的时候,手动搜索会很麻烦。本文提供的代码可以解决该问题。
二、代码
# CSDN 混沌的矩阵 2022.9.7
# 参考了网上的部分代码
import pdfplumber
import PyPDF2
import re
import os
import csv
import json
# 定义函数,得到pdf页数
def get_pages(filename):
with open(filename, 'rb' ) as fb:
pages = PyPDF2.PdfFileReader(fb).getNumPages()
return pages
# 利用正则表达式查找关键词,并提取
def get_text(filename, pages, strobj):
flag = False
find = []
ele_len = 0
with pdfplumber.open(filename) as pdf:
for i in range(0, pages):
print('正在搜索'+filename+'的第'+str(i)+'页')
find.append(re.findall(strobj, pdf.pages[i].extract_text()))
ele_len += len(find[i])
print(filename + '搜索完毕')
if ele_len != 0:
flag = True
return flag
# 保存表格
def save(pdf_name, judge):
# 可以在这里更改保存csv的路径
with open('C:\\csv\\report.csv', 'a', newline="", encoding='utf-8') as f_csv:
writer = csv.writer(f_csv)
writer.writerow([pdf_name, judge])
print([pdf_name, judge])
# 运行代码
if __name__ == '__main__':
# 可以在这里更改保存pdf的路径
path = 'C:\\pdf'
file_list = os.listdir(path)
file_list_copy = file_list[::]
objstr = []
while True:
objstr_input = input('请输入您所需要查找的关键字:')
objstr.append(objstr_input)
choice = input('请问您还要继续输入关键词吗?输入y继续输入关键字,输入其他结束')
if choice == 'Y' or choice == 'y':
continue
else:
break
for keyword in objstr:
print('正在搜索关键词:'+keyword)
for file in file_list_copy:
path_filename = path + '\\'+file
pages_num = get_pages(path_filename)
if get_text(path_filename, pages_num, keyword):
try:
save(file, keyword)
except Exception as e:
print(e)
with open('rest.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(file_list, ensure_ascii=False))
'''
说明
1、文件寻找路径可以更改,如果使用默认路径,请阅读下文2和3
2、请将目标pdf文件放入c:\pdf文件夹,如果您的电脑上没有该文件夹,请自建,然后将所有pdf放入。
3、生成结果见c:\csv文件夹,如果您的电脑上没有该文件夹,请先建立该文件夹。
4、Python开发版本是3.9
5、csv出现乱码的处理方法
这是正常现象,因为默认excel打开的时候是不带BOM的,解决方法:
(step1)用记事本打开csv文件
(step2)另存为,存的时候名字不用改,然后把编码格式改为带BOM的UTF-8
(step3)重新打开csv文件即可看到正常
'''
三、测试
3.1 测试用PDF
- 2018下半年软考初级程序员下午真题.pdf(试题非原试卷,资源来自“希赛网”,以下简称《软考》)
- 计算机专用英语词汇1500词.pdf(以下简称《词汇》)
- 数据结构电子版pdf(严蔚敏版).pdf(以下简称《数据结构》)
3.2 测试关键词
| 关键词 | 《软考》是否含有 | 《词汇》是否含有 | 《数据结构》是否含有 |
|---|---|---|---|
| 程序 | 含有 | 含有 | 含有 |
| 答题纸 | 含有 | 不含有 | 不含有 |
| 选择 | 不含有 | 含有 | 含有 |
| 数据元素是数据的基本单位 | 不含有 | 不含有 | 含有 |
3.3 测试结果
首先输入关键词:
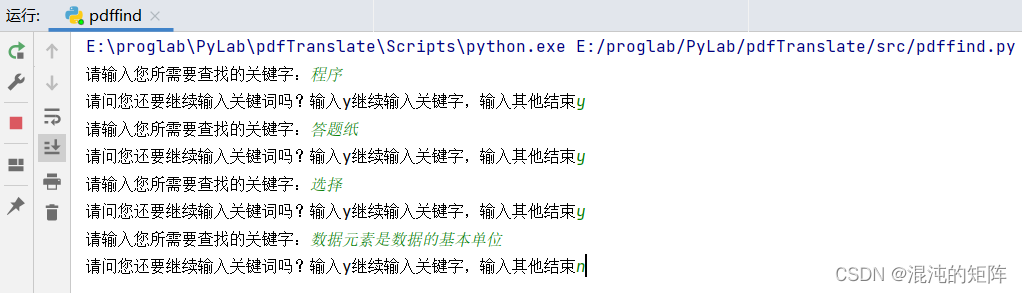
运行中:

运行结果:
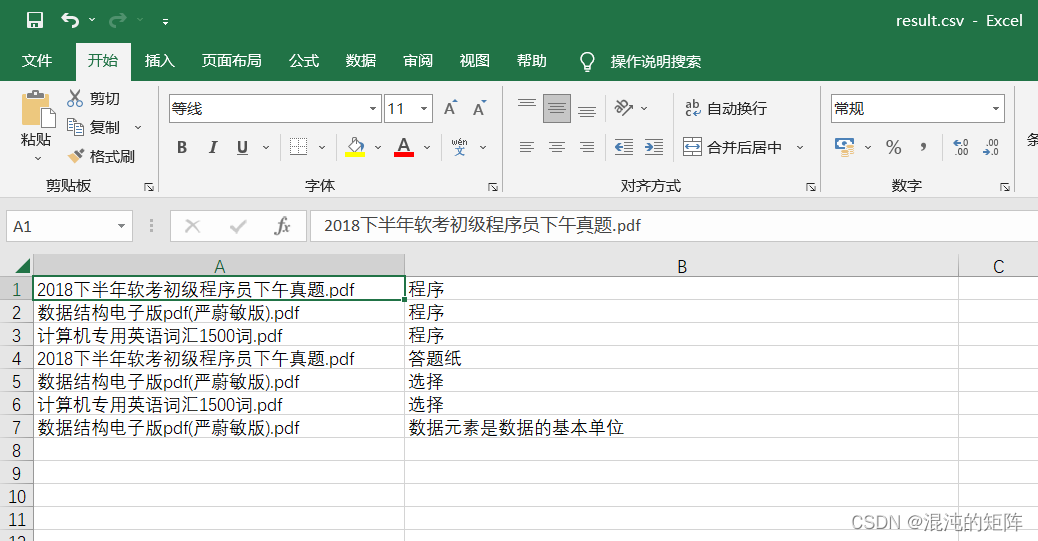
可以看到,这张表格展示了哪些文件中含有指定的关键词。其中, “程序”关键词在三个测试文件中都存在, “答题纸”关键词仅在《软考》pdf中存在, “选择” 关键词在《数据结构》和《词汇》中存在, “数据元素是数据的基本单位” 仅在《数据结构》pdf中存在,与真实情况一致。


















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









