







 训练集里面的训练图片被标记如下如果YOLO算法需要识别80种物体,那么c可以是1-80之间的任意整数,也可以是80维的向量,识别出的物体为1,其他均为零。YOLO算法模型输入(m,608,608,3)输出是识别出来的物体被边框(pc,bx,by,bw,bh,c),加入c是一个80维的向量,则每个边框有80个代表值示例中将使用5个achors box,因此模型为IMAGE
训练集里面的训练图片被标记如下如果YOLO算法需要识别80种物体,那么c可以是1-80之间的任意整数,也可以是80维的向量,识别出的物体为1,其他均为零。YOLO算法模型输入(m,608,608,3)输出是识别出来的物体被边框(pc,bx,by,bw,bh,c),加入c是一个80维的向量,则每个边框有80个代表值示例中将使用5个achors box,因此模型为IMAGE
训练集里面的训练图片被标记如下

如果YOLO算法需要识别80种物体,那么c可以是1-80之间的任意整数,也可以是80维的向量,识别出的物体为1,其他均为零。
YOLO算法模型
输入(m,608,608,3)
输出是识别出来的物体被边框(pc,bx,by,bw,bh,c),加入c是一个80维的向量,则每个边框有80个代表值
示例中将使用5个achors box,因此模型为IMAGE(吗,608,608,3)->deep CNN->ENCODING(m,19,19,5,85)
ENCODING细节解释
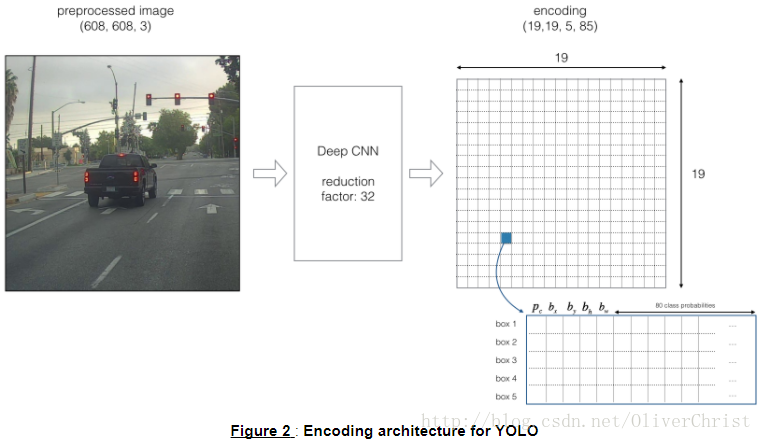
解释:如果识别出的物体落入了一个网格中,那么这个网格将会负责识别该物体
本示例中使用的是5个achors box,因此19*19中的每个网格ENCODING5个boxes,为了方便起见,把(m,19,19,5,85)展开为(m,19,19,425)
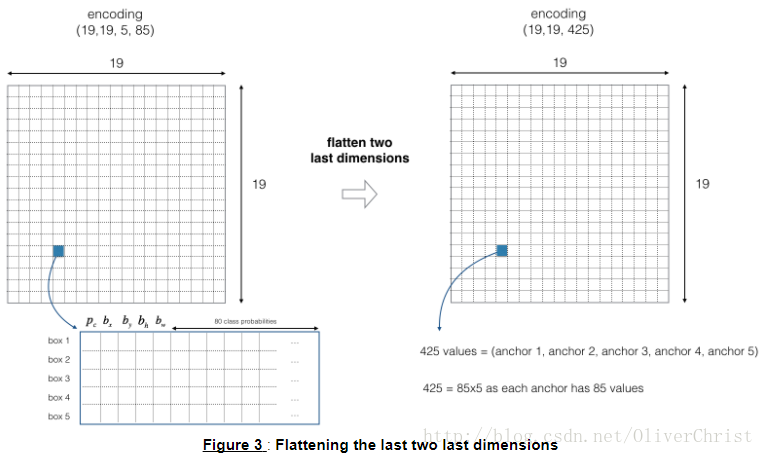
于是,对每个achors box做如下计算

对于19*19个网格中的每个格子,找到每个网格的最大score
给每个最大score的achors box上色
另外一种可视化YOLO输出结果的方式是:把识别物体绑定的方框画出来
通过一次前向传播识别19*19*85个achors box,并用不同样色标记识别出来物体上的方框

但是这种方式输出的结果仍然太多,需要用non-max-suppression方法来过滤掉一部分输出结果:
1.减少输出识别物体的方框数量
2.对于一个识别物体多个方框覆盖的情况,会仅仅保留一个方框
用最大阈值过滤class
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









