









YOLO有S*S的格子,每个格子包含B个边界框,格子对应的预测总的类别数为C种类别。
总结重点:
1、一张图片中有多个object,即一张图片中有多个对象,如下图所示,我们框了很多的真实框,那么S*S*B个bbox的对应的confidence怎么计算出来呢?confidence=p(object)*IOU(truth,pred),那么p(object)和IOU(truth,pred)怎么求解呢?看了一下代码,代码是这样解决的:例如有5个框,对当前的框,计算S*S*B个bbox和当前的IOU,然后判断当前物体的中心落在哪个grid-cell中,然后将该grid cell的值设置为1,其他的采用填充技术,将其设置为[S,S,1]的Tensor(注意该tensor中只有一个1,其他的都为0),然后和[S,S,B]的IOU相乘(点乘multiply而不是matmul),得到[S,S,B]个confidence,然后嘞,不是有5个框吗,我们循环做上面的运算,就可以得到更新后的IOU和confidence了,不就很完美地解决了这个问题了吗?(还是觉得什么东东如果不理解的话,地址就在:源码);

2、送入NMS进行非极大值抑制的时候,送入的是class_specific confidence,而cs_confidence=p(class|object)*p(object)*IOU(pred,truth),这里的p(class|object)就是每个grid_cell的预测类,然后就可以得到每个bbox对应的类别了,然后将其中概率最大的那个赋值给bbox,就作为它的概率啦!!!设置阈值,率除掉值比较小的框之后,然后可以安心地送入NMS进行寻找啦!

3、bbox的confidence不止反应了该bbox有物体的可能性,还反映了概bbox预测的准确率(confidence=p(object)*IOU(truth,pred))!
YOLO将物体检测作为一个回归问题求解,一次求解便可以得到图像中所有物体的位置和其所属类别和相应的置信概率。
而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解(①物体种类(分类问题);②物体位置(回归问题))
YOLO最后一层的输出维度为S*S*(B*5+C),
1)每个格子对应B个边界框,边界框的宽高范围为全图,表示以该格子为中心寻找物体的边界框位置;
2)每个格子对应C个概率值,找出其中最大概率对应的类别p(Class|object),并认为该格子中包含该物体或者该物体的一部分;
3)每个边界框对应一个分值,代表该处是否有物体及定位准确度P(object)*IOU(pred,truth)。
YOLO的处理流程:

1)将图片尺寸放缩到448*448大小;
2)将图片塞给CNN网络,进行处理;
3)进行NMS(非极大值抑制)进行bbox的冗余裁剪,处理掉大批的冗余,得到最后的预测结果。
YOLO的网络结构:
24个卷积层+2个全连接层


卷积层用来提取图像特征,注意用到了多个1*1卷积层,注意1*1卷积层的作用是用来狂通道信息整合(升维/降维,降低维度是因为其中(如56*56*256中的256个通道中有大量的冗余信息)有大量的冗余信息),mAP(mean average precision,平均精度),

全连接层用来预测图像位置(1)+类别概率值(2)。

Bounding box针对位置的输出为5个(x,y,w,h,confidence),其中(x,y)指的是bounding box的中心相对于当前格子的偏移量,归一化到[0,1],然后呢,w,h为相对于当前图片宽,高的比例,同样方便起见归一化到[0,1]之间,这样就可以得到物体的位置,然后呢,
1、confidence=P(object)*IOU(pred,truth),注意这个置信度confidence判断的是该bbox中有object的概率,但是呢?这里呢有说这个bbox属于哪个类了吗?没有吧!,这就比较好玩了,那么怎样判断该bbox属于哪个物体呢?先留个悬念哈!我们后面解决!!!
只是当P(object)=1才求取confidence的原因是为了提高效率,若bounding box包含该物体,P(object)=1,然后进行求bbox的否则P(object)=0,IOU(pred,truth)为预测bounding box和物体真是区域的交集面积,用真是区域的像素面积!
2、然后嘞,我们要这么多的bbox干森么呢?这里我们来解决上面留下的悬念哈!有了这么多的bbox之后,我们就可以计算每个bbox属于每个类的置信度了,即 class_specific_confidence(cs_confidence)=P(class_i|object)*P(object)*IOU(pred,truth)=P(class_i)*IOU(pred,truth),p(class|object)指的是该该物体属于不同类的概率,注意当P(object)为1的时候我们才进行confidence的计算,但是需要注意的是P(class|object)的值都计算出了,即bbox属于每个类的概率都被计算了出来,这样就可以得到每个Bbox的cs_confidence,然后嘞,才将这种类型的数据送入NMS算法中进行求解,注意哈,送入NMS中的数据类型是cs_confidence,即在NMS中进行排序(由上到下)也是对cs_confidence进行排序的!!!
(PS:为什么是S*S*(C+B*5),而不是S*S*(B*(C*5))呢?原因在于每个grid虽然预测B个bbox,但该格子中物体属于每个类的条件概率都是一样的,即格子中的每个bbox的P(class|object)这一项都是一样的,)
损失函数如下:

PS:
YOLO中如何应用NMS去进行最优候选框的生成的呢?
1)版本1:知乎上的大佬的实验验证过的版本:
请参见:5分钟学会AI - How YOLO only look once
2)版本2:(我的理解,不过还未跑过实验,暂时还未曾验证!)

结合代码我们来理解各个对应的部分:
def body1(self, num, object_num, loss, predict, labels, nilboy):
"""
calculate loss
Args:
predict: 3-D tensor [cell_size, cell_size, 5 * boxes_per_cell]
labels : [max_objects, 5] (x_center, y_center, w, h, class)
"""
label = labels[num:num+1, :]
label = tf.reshape(label, [-1])
#calculate objects tensor [CELL_SIZE, CELL_SIZE]
min_x = (label[0] - label[2] / 2) / (self.image_size / self.cell_size)
max_x = (label[0] + label[2] / 2) / (self.image_size / self.cell_size)
min_y = (label[1] - label[3] / 2) / (self.image_size / self.cell_size)
max_y = (label[1] + label[3] / 2) / (self.image_size / self.cell_size)
min_x = tf.floor(min_x)
min_y = tf.floor(min_y)
max_x = tf.ceil(max_x)
max_y = tf.ceil(max_y)
temp = tf.cast(tf.stack([max_y - min_y, max_x - min_x]), dtype=tf.int32)
objects = tf.ones(temp, tf.float32)
temp = tf.cast(tf.stack([min_y, self.cell_size - max_y, min_x, self.cell_size - max_x]), tf.int32)
temp = tf.reshape(temp, (2, 2))
objects = tf.pad(objects, temp, "CONSTANT")
#calculate objects tensor [CELL_SIZE, CELL_SIZE]
#calculate responsible tensor [CELL_SIZE, CELL_SIZE]
center_x = label[0] / (self.image_size / self.cell_size)
center_x = tf.floor(center_x)
center_y = label[1] / (self.image_size / self.cell_size)
center_y = tf.floor(center_y)
response = tf.ones([1, 1], tf.float32)
temp = tf.cast(tf.stack([center_y, self.cell_size - center_y - 1, center_x, self.cell_size -center_x - 1]), tf.int32)
temp = tf.reshape(temp, (2, 2))
response = tf.pad(response, temp, "CONSTANT")
#objects = response
#calculate iou_predict_truth [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
predict_boxes = predict[:, :, self.num_classes + self.boxes_per_cell:]
predict_boxes = tf.reshape(predict_boxes, [self.cell_size, self.cell_size, self.boxes_per_cell, 4])
predict_boxes = predict_boxes * [self.image_size / self.cell_size, self.image_size / self.cell_size, self.image_size, self.image_size]
base_boxes = np.zeros([self.cell_size, self.cell_size, 4])
for y in range(self.cell_size):
for x in range(self.cell_size):
#nilboy
base_boxes[y, x, :] = [self.image_size / self.cell_size * x, self.image_size / self.cell_size * y, 0, 0]
base_boxes = np.tile(np.resize(base_boxes, [self.cell_size, self.cell_size, 1, 4]), [1, 1, self.boxes_per_cell, 1])
predict_boxes = base_boxes + predict_boxes
iou_predict_truth = self.iou(predict_boxes, label[0:4])
#calculate C [cell_size, cell_size, boxes_per_cell]
C = iou_predict_truth * tf.reshape(response, [self.cell_size, self.cell_size, 1])
#calculate I tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
I = iou_predict_truth * tf.reshape(response, (self.cell_size, self.cell_size, 1))
max_I = tf.reduce_max(I, 2, keep_dims=True)
I = tf.cast((I >= max_I), tf.float32) * tf.reshape(response, (self.cell_size, self.cell_size, 1))
#calculate no_I tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
no_I = tf.ones_like(I, dtype=tf.float32) - I
p_C = predict[:, :, self.num_classes:self.num_classes + self.boxes_per_cell]
#calculate truth x,y,sqrt_w,sqrt_h 0-D
x = label[0]
y = label[1]
sqrt_w = tf.sqrt(tf.abs(label[2]))
sqrt_h = tf.sqrt(tf.abs(label[3]))
#sqrt_w = tf.abs(label[2])
#sqrt_h = tf.abs(label[3])
#calculate predict p_x, p_y, p_sqrt_w, p_sqrt_h 3-D [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
p_x = predict_boxes[:, :, :, 0]
p_y = predict_boxes[:, :, :, 1]
#p_sqrt_w = tf.sqrt(tf.abs(predict_boxes[:, :, :, 2])) * ((tf.cast(predict_boxes[:, :, :, 2] > 0, tf.float32) * 2) - 1)
#p_sqrt_h = tf.sqrt(tf.abs(predict_boxes[:, :, :, 3])) * ((tf.cast(predict_boxes[:, :, :, 3] > 0, tf.float32) * 2) - 1)
#p_sqrt_w = tf.sqrt(tf.maximum(0.0, predict_boxes[:, :, :, 2]))
#p_sqrt_h = tf.sqrt(tf.maximum(0.0, predict_boxes[:, :, :, 3]))
#p_sqrt_w = predict_boxes[:, :, :, 2]
#p_sqrt_h = predict_boxes[:, :, :, 3]
p_sqrt_w = tf.sqrt(tf.minimum(self.image_size * 1.0, tf.maximum(0.0, predict_boxes[:, :, :, 2])))
p_sqrt_h = tf.sqrt(tf.minimum(self.image_size * 1.0, tf.maximum(0.0, predict_boxes[:, :, :, 3])))
#calculate truth p 1-D tensor [NUM_CLASSES]
P = tf.one_hot(tf.cast(label[4], tf.int32), self.num_classes, dtype=tf.float32)
#calculate predict p_P 3-D tensor [CELL_SIZE, CELL_SIZE, NUM_CLASSES]
p_P = predict[:, :, 0:self.num_classes]
#class_loss
class_loss = tf.nn.l2_loss(tf.reshape(objects, (self.cell_size, self.cell_size, 1)) * (p_P - P)) * self.class_scale
#class_loss = tf.nn.l2_loss(tf.reshape(response, (self.cell_size, self.cell_size, 1)) * (p_P - P)) * self.class_scale
#object_loss
object_loss = tf.nn.l2_loss(I * (p_C - C)) * self.object_scale
#object_loss = tf.nn.l2_loss(I * (p_C - (C + 1.0)/2.0)) * self.object_scale
#noobject_loss
#noobject_loss = tf.nn.l2_loss(no_I * (p_C - C)) * self.noobject_scale
noobject_loss = tf.nn.l2_loss(no_I * (p_C)) * self.noobject_scale
#coord_loss
coord_loss = (tf.nn.l2_loss(I * (p_x - x)/(self.image_size/self.cell_size)) +
tf.nn.l2_loss(I * (p_y - y)/(self.image_size/self.cell_size)) +
tf.nn.l2_loss(I * (p_sqrt_w - sqrt_w))/ self.image_size +
tf.nn.l2_loss(I * (p_sqrt_h - sqrt_h))/self.image_size) * self.coord_scale
nilboy = I
return num + 1, object_num, [loss[0] + class_loss, loss[1] + object_loss, loss[2] + noobject_loss, loss[3] + coord_loss], predict, labels, nilboy这里只截取了一些代码,这里详细介绍一下代码中出现的C,I,response,p_C,P和p_P等变量:
1)response对应的是图像中对应的待检测的某个目标的中心落在那个grid_cell内,对应一个S*S的一个数组(默认的为7),我设置center_x=1,center_y=1,将response运行,之后输出的结果如下:
 ,所以其对应的为图像中的某个物体的中心落在grid_cell中的矩阵表示;
,所以其对应的为图像中的某个物体的中心落在grid_cell中的矩阵表示;
2)现在我们来求解I,I表示的是最终的中心落在grid_cell中的ground truth矩阵,即损失函数中的Cij;
I = iou_predict_truth * tf.reshape(response, (self.cell_size, self.cell_size, 1))
max_I = tf.reduce_max(I, 2, keep_dims=True)
I = tf.cast((I >= max_I), tf.float32) * tf.reshape(response, (self.cell_size, self.cell_size, 1))3))现在我们来计算C,C其实表示的是损失函数中的~Ci,即实际的预测框的置信度,需要将预测框和实际的框计算iou,这样就可以得到最终的~Ci,个人感觉这儿~Ci写成~Cij更清晰一些(得到的实际为S*S*B的置信度矩阵)。
C = iou_predict_truth * tf.reshape(response, [self.cell_size, self.cell_size, 1])4)P对应的是实际的类别标签,对应的损失函数中的^p(i),看看它的代码:
P = tf.one_hot(tf.cast(label[4], tf.int32), self.num_classes, dtype=tf.float32)5)p_P对应的是预估出来的类别概率:
p_P = predict[:, :, 0:self.num_classes]6)现在我们来看p_C,可以看到就是网络预测的置信度,然后通过设置损失函数,我们可以最终让置信度实现预估的和实际的相等,而且预测的框和实际的框相等,而且实现类别相等,达到最后很好的检测效果。
PS:
这儿需要注意的是,对于目标中心点没有落在其中的预测anchors,代码中的损失函数和论文中给的损失函数只有一点点出入,这儿代码选择不管是否目标中心点的坐标落入预测出来的anchors内,直接用预测的置信度进行统计,即对于noobj的部分Ci-(~Ci)变化为Ci,而论文中的部分则要求对于目标落在grid_cell中的B-1个预测anchors选择Ci-(~Ci),以保证对应的置信度,论文中的更贴切一些,但这儿修改后的部分差距不大,所以也还是可以接受的。
NMS抑制算法
1)将所有的bbox都设置为没有被抑制,然后将bbox按照score从大到小进行排列;
2)从第0个框(score最高的bbox)开始进行遍历,如果该框没有被抑制,便将所有与该框IOU大于threshold(阈值)的框都设置为抑制;
3)返回没有被抑制的bbox(bbox的集合)。
(这里有一个问题哈,就是经过nms算法处理后的返回的是:①有n个物体返回n个bbox,n个bbox对应n个物体的score最大的bbox;②有n个物体返回大于n个bbox,即1个物体对应多余1个bbox的bbox),这两个问题所对应的实际问题其实是:对每个物体而言,其对应的除score最高(第0个)的bbox之外,其他的bbox与第0个bbox是否都会大于threshold,即是否都会被抑制,如果对与图片中的一个物体的相关的bbox来说,并不是除第0个bbox之外的其他bbox都会被抑制,那么针对一个物体将返回多余1个的bbox,这多个bbox怎么来共同预测这个物体呢???对应一个物体,其相关的bbox在经过nms处理之后,返回1个相关的bbox还是返回1个以上相关的bbox,这是一个问题!!!)
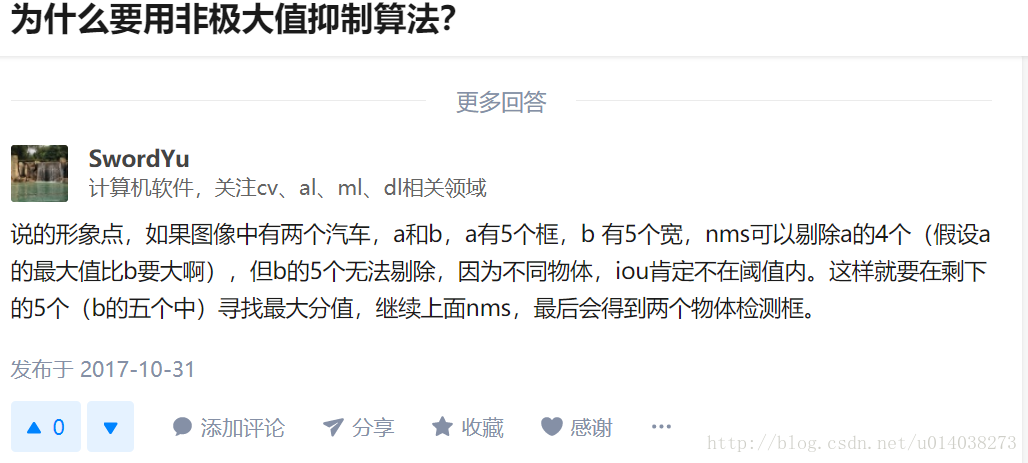
这是知乎上的答案,大家可以参考一下啊!为什么要用非极大值抑制算法?

参考:
图解YOLO
物体检测-回归方法(YOLO+SSD)
YOLO目标检测原理与实践
YOLO详解
[目标检测]YOLO原理
YOLO,YOLO2学习(搬运)
代码















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









