






SpatialLM: 让AI秒懂3D世界的空间理解模型
随着人工智能的不断发展,机器人和智能设备在实际环境中的应用越来越广泛,然而,如何让AI理解和适应现实世界的三维空间,始终是一个技术难题。传统的2D图像识别能力有限,难以处理复杂的空间布局与物体交互。而如今,群核科技(ManyCore Tech)发布的SpatialLM模型,正是为了解决这一难题,为机器人和智能设备赋能,让它们能够像人类一样“看懂”三维空间。

什么是SpatialLM?
SpatialLM
(Spatial Language Model)是一个革命性的3D大型语言模型,专门设计用来处理点云数据并进行空间理解。该模型通过分析来自不同来源的数据(如手机视频、RGBD图像、LiDAR传感器等),重建和理解三维环境。它能够将杂乱无章的3D点云转化为结构化的空间描述,包括房间布局、物体位置和尺寸、墙壁、窗户、门等关键信息。这种能力对于机器人在现实环境中的导航、避障、物品搬运等任务至关重要。
关键特点
- 三维视觉重建
SpatialLM可以从普通手机视频中,甚至没有专门的设备,仅凭一部手机拍摄的视频,重建出完整的3D场景。这使得空间数据采集的成本大大降低,极大地提升了3D场景重建的效率。
- 空间翻译
模型将点云数据转化为结构化的空间描述。比如,它能够明确指出“这是一个5.3米×4.2米的房间,北墙有两扇窗户,东墙中央有一扇门通往厨房”等详细信息。
- 精确测量
SpatialLM不仅可以理解空间,还能准确地提供墙壁、门窗和家具等物体的精确尺寸。例如,它能够告诉机器人:沙发离墙1.2米,茶几的高度是45厘米。
- 兼容性和标准化输出
SpatialLM的输出符合建筑行业的标准格式(如IFC格式),便于与其他设计和建筑软件进行集成,确保在实际应用中的广泛兼容性。
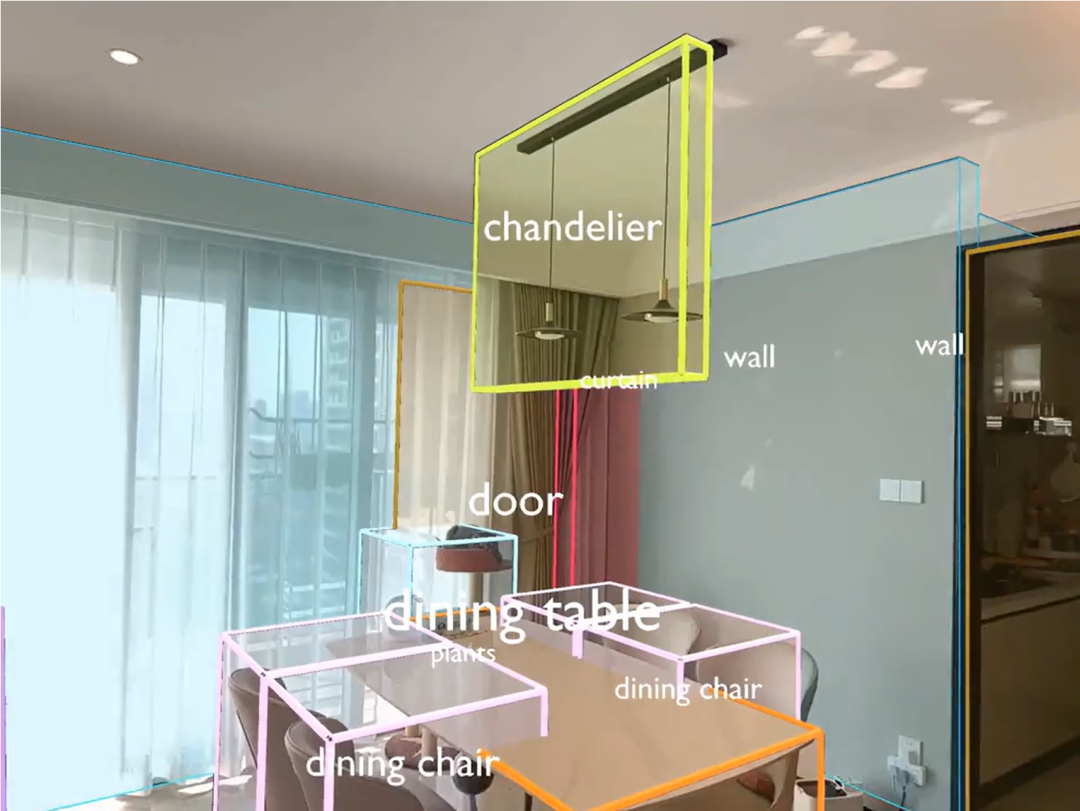
技术核心
SpatialLM
是一种基于大型语言模型(LLM)的3D空间理解技术,专为处理和分析点云数据而设计。该模型能够将从不同来源(如普通手机视频、RGBD图像或LiDAR传感器)收集到的点云数据,转化为结构化的空间描述,帮助机器人、虚拟助手等理解并与真实世界的三维空间互动。以下是其技术核心:
- 点云数据处理与重建
SpatialLM通过使用MASt3R-SLAM算法,从RGB视频中提取每一帧的空间特征,进而构建一个完整的三维点云模型。点云中的每一个小点都包含空间的深度信息和位置,通过这些数据,SpatialLM能够重建出一个物理上合理且符合真实世界几何特征的场景。

- 点云编码与空间理解
生成的点云数据经过点云编码器处理,转化为紧凑的特征表示。然后,SpatialLM采用其大语言模型(LLM)将这些特征进一步转化为高层次的场景代码。这些场景代码不仅描述了空间中的几何形态(如物体的位置、尺寸等),还包括物体的语义分类(如沙发、床、门等)。

- 物理规则与精确测量
SpatialLM还能够依据物理规则提供精确的测量信息,例如物体之间的距离、尺寸及空间布局的合理性。这对于机器人在进行空间导航、任务规划时至关重要。例如,机器人可以通过“沙发与墙壁的距离是1.2米”这样的信息来避免碰撞。
- 兼容性与标准化输出
SpatialLM能够将输出结果转化为行业标准格式(如IFC格式),这一点使得它能够与各种设计软件及建筑管理工具兼容。这样,空间理解的结果不仅能够直接应用于机器人导航、自动化任务,还能方便地导入到建筑设计或仿真环境中进行进一步应用。
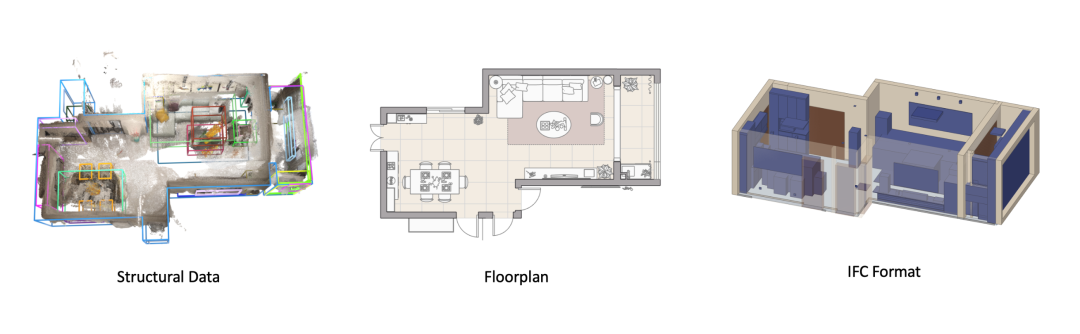
性能基准测试
为了评估SpatialLM
在处理真实世界场景时的表现,群核科技进行了系统的基准测试,主要基于SpatialLM-Testset
,这个数据集包含了107个经过MASt3R-SLAM重建的点云数据样本,涵盖了复杂且具挑战性的室内环境。以下是基准测试的主要结果和性能表现:
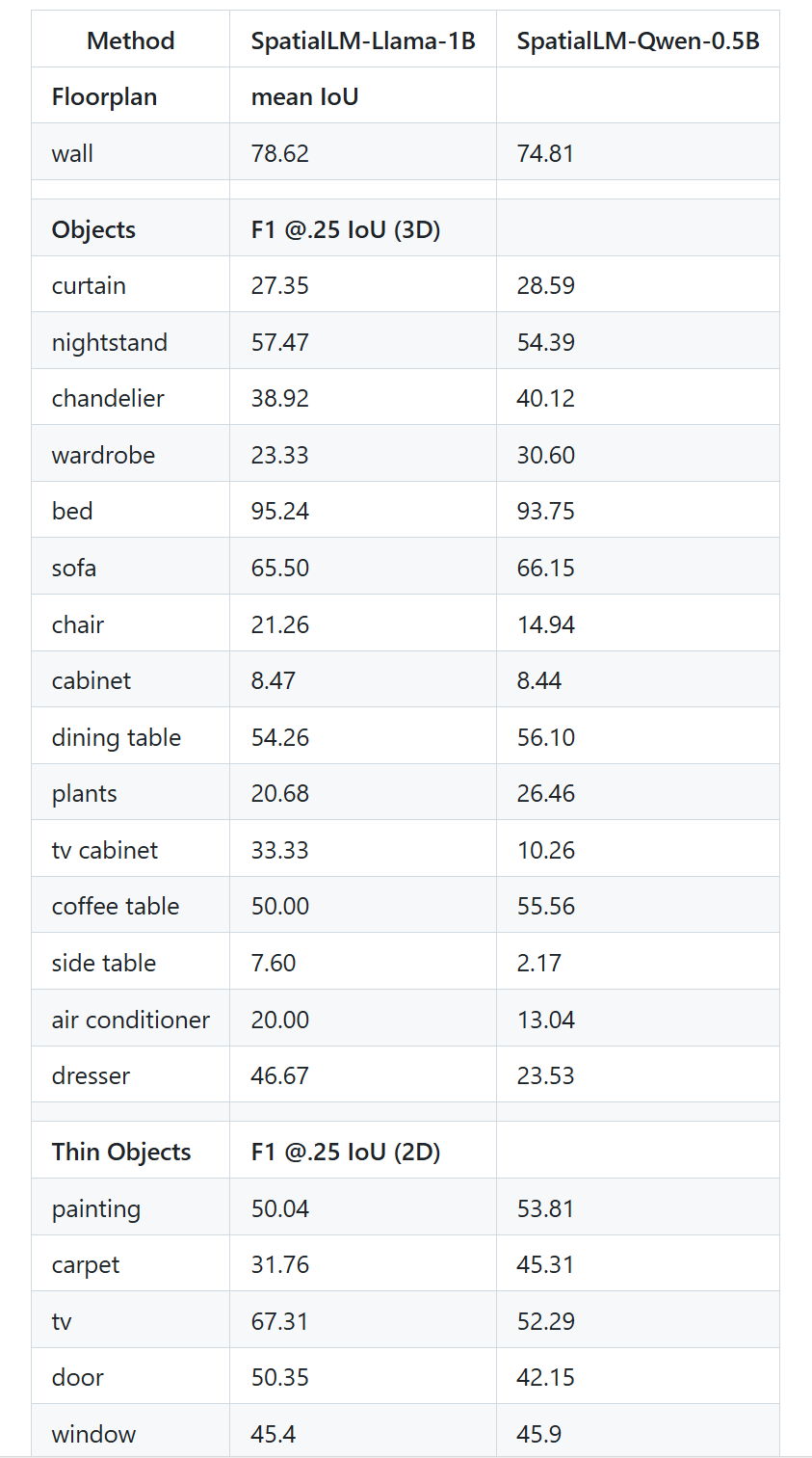
在对房间布局的理解上,SpatialLM-Llama-1B表现优异,达到了78.62%的平均IoU(Intersection over Union,交并比)。相比之下,较小的SpatialLM-Qwen-0.5B
模型则为74.81%
。这表明更大的模型能够在空间布局的识别上提供更高的准确性。
对象识别与定位
- F1@0.25 IoU(3D)
对物体识别的测试中,SpatialLM-Llama-1B表现出了卓越的能力,尤其是在大型物品如“床”和“沙发”的识别中。对于“床”这一物体,SpatialLM-Llama-1B的F1得分为95.24%
,而对于“沙发”,则为65.50%
。相比之下,SpatialLM-Qwen-0.5B
的性能稍弱,尤其是在对“电视柜”和“小型物品”如“书架”与“夜灯”等的识别上,它的F1得分较低。
细物体的识别表现
对细小物体的识别表现相对较弱,如“画”与“地毯”等物体的F1得分分别为50.04%与31.76%
。这一差距展示了在复杂物体(如薄物体)检测时模型仍有待优化的空间。
通过这些基准测试结果,可以看出SpatialLM-Llama-1B
模型在空间理解和三维物体识别任务中的强大能力。尽管仍然存在某些细物体识别上的局限性,但其在较大物体和空间布局的理解上已经达到了非常高的精度,这使得它在实际应用中具有很大的潜力,尤其是在机器人导航、建筑设计、虚拟现实等领域。
下载链接
OpenCSG社区:
https://opencsg.com/models/AIWizards/SpatialLM-Llama-1B
HF社区:
https://huggingface.co/manycore-research/SpatialLM-Llama-1B

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









