







司南评测集社区 CompassHub 作为司南评测体系的重要组成部分,旨在打造创新性的基准测试资源导航社区,提供丰富、及时、专业的评测集信息,帮助研究人员和行业人士快速搜索和使用评测集。
2025 年 5 月,司南评测集社区新收录了 24 个评测基准,覆盖多模态、智能体、数学、推理、医学等方向,以下为部分新增评测集的介绍,欢迎大家下载使用。
司南评测集社区链接:
https://hub.opencompass.org.cn/home
MedArabiQ

发布单位:
New York University
发布时间:
2025-05-06
评测集简介:
MedArabiQ 是一个用于评估阿拉伯语医学任务的基准测试,包含七个任务,涵盖多种问题格式:多项选择题、填空题(有选项和无选项)、患者-医生问答对。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MedArabiQ
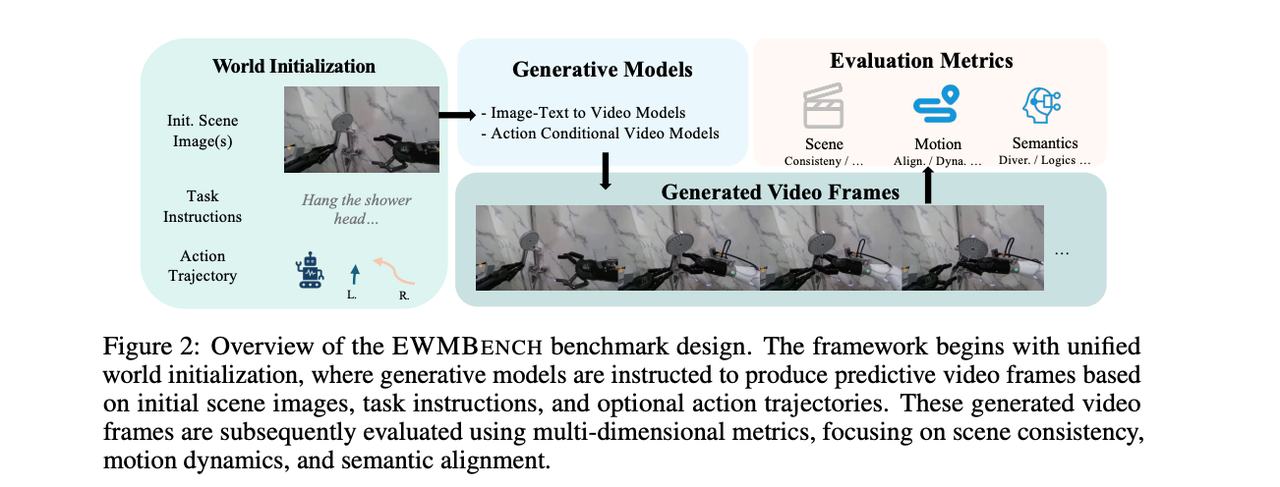
EWMBench
发布单位:
Agibot**,etc.**
发布时间:
2025-05-14
评测集简介:
EWMBench 是一个用于评估具身世界模型的基准测试,涵盖场景一致性、运动正确性和语义对齐等方面的任务。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/EWMBench
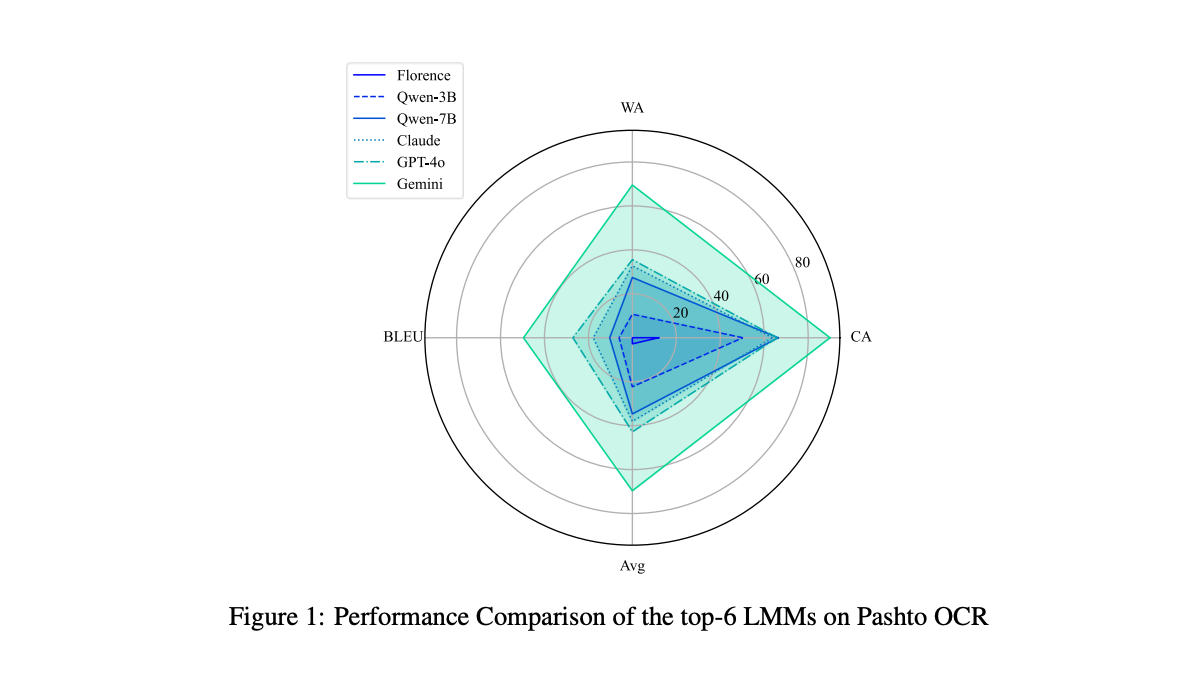
PSOCR
发布单位:
Zirak AI
发布时间:
2025-05-15
评测集简介:
PsOCR 是一个专为低资源普什图语光学字符识别(OCR)任务构建的大规模合成数据集,包含 100 万张合成图像,覆盖词级、行级和文档级三种标注形式。数据集涵盖 1000 种独特字体风格,并在颜色、图像尺寸、文本布局等方面展现出丰富多样的变化。此外,PsOCR 提供了一个 公开可用的 OCR 基准测试,包含 1 万张图像,便于对低资源普什图语OCR系统进行系统性评估和比较。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/PashtoOCR
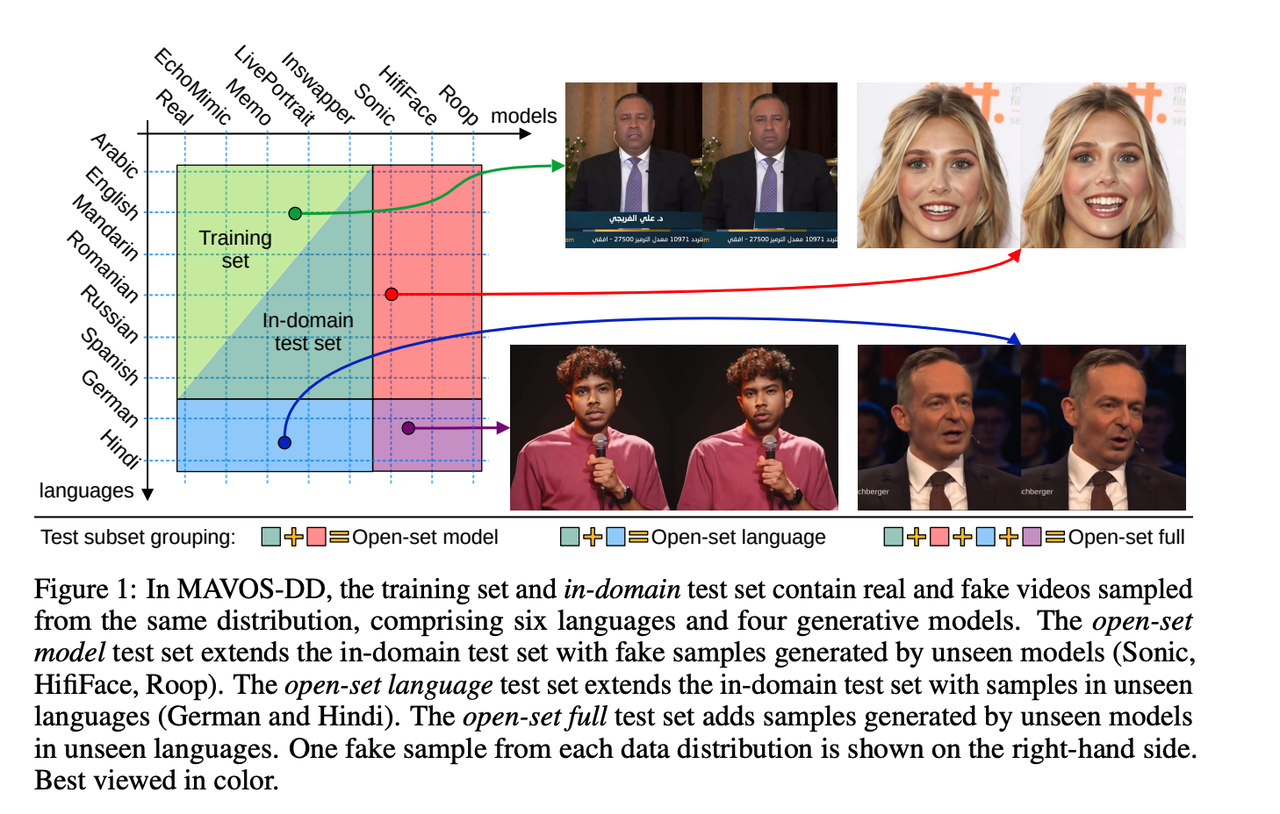
MAVOS-DD
发布单位:
University of Bucharest,etc
发布时间:
2025-05-16
评测集简介:
MAVOS-DD 是一个多语言音视频开放集深度伪造检测基准,包含超过 250 小时的真实与伪造视频,覆盖八种语言,其中 60% 的数据为生成数据。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MAVOS-DD
CleanPatrick

发布单位:
University of Basel,etc
发布时间:
2025-05-16
评测集简介:
CleanPatrick 是一个专为图像领域数据清洗设计的大规模基准测试,基于 Fitzpatrick17k 皮肤病学数据集构建。该数据集旨在评估模型检测三类常见数据质量问题的能力:偏离主题的样本、近似重复样本以及标签错误。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/CleanPatrick
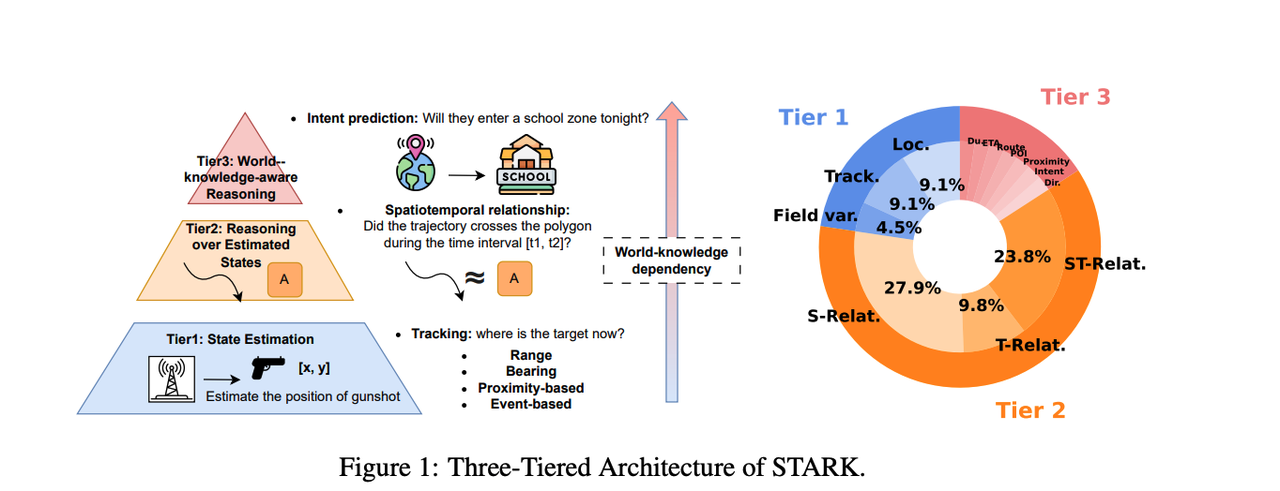
STARK_10k
发布单位:
University of California, Los Angeles
发布时间:
2025-05-16
评测集简介:
STARK 是一个全面的基准测试套件,旨在系统评估大语言模型和大推理模型在时空推理任务中的表现,特别是在网络物理系统中的应用,如机器人、自动驾驶和智能城市基础设施。该基准包含 26 种不同的时空任务,涵盖状态估计、时空关系推理和世界知识感知推理三个层次。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/STARK_10k
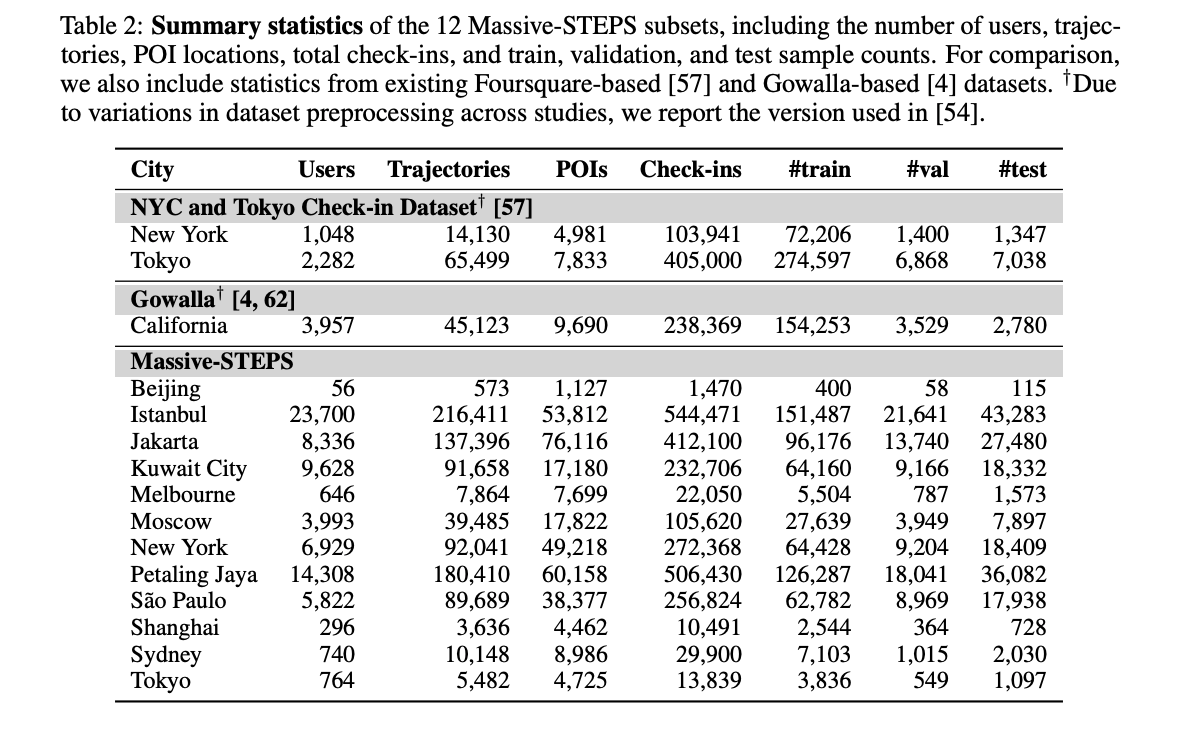
Massive-STEPS
发布单位:
University of New South Wales
发布时间:
2025-05-16
评测集简介:
Massive-STEPS 是一个大规模的语义轨迹数据集,旨在理解和预测兴趣点(POI)签到行为。该数据集基于 Semantic Trails 数据集构建,覆盖 12 个全球不同地区的城市,包含 2012年-2013年和2017年-2018年 两个时间段的签到数据,提供了更现代和多样化的 POI 签到信息。Massive-STEPS 不仅丰富了签到数据的语义信息,还通过与 Foursquare Open Source Places 数据集对齐,增加了 POI 的地理坐标、名称和地址等元数据。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/Massive-STEPS
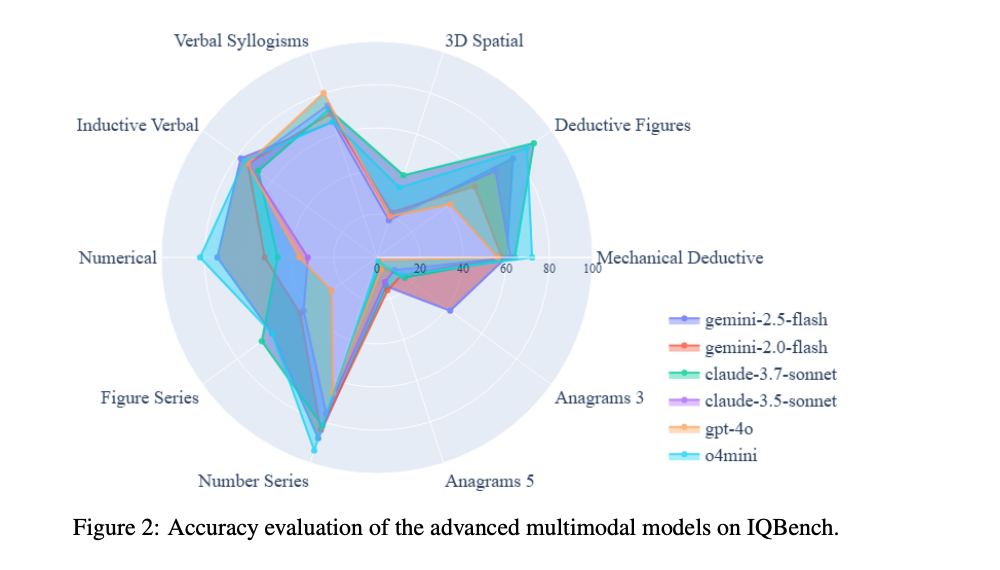
IQBench
发布单位:
Harvard Medical School, USA Uppsala University,etc
发布时间:
2025-05-17
评测集简介:
IQBench 是一项新颖的基准测试,旨在通过标准化的视觉智商测试评估视觉语言模型的流体智力。该基准包含 500 道精心挑选的问题,全面覆盖智商测试的核心领域,包括模式识别、类比推理、视觉算术、空间理解、抽象与具体推理、数字与图形序列推理、字谜以及三段论语言推理。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/IQBench
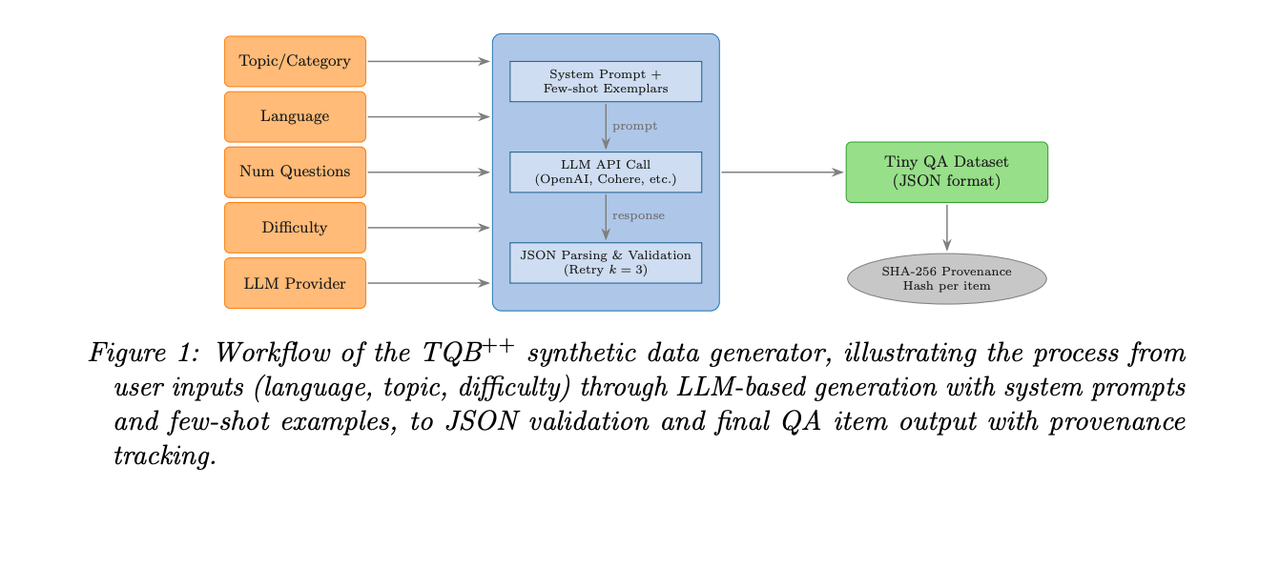
TinyQA
发布单位:
Comet ML
发布时间:
2025-05-17
评测集简介:
TinyQA 是一个基准测试套件,旨在通过自然语言问答对评估大型语言模型的推理能力。该基准测试专注于评估各种推理技能,包括因果推理、逻辑推理和常识推理。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/tiny_qa_benchmark_pp
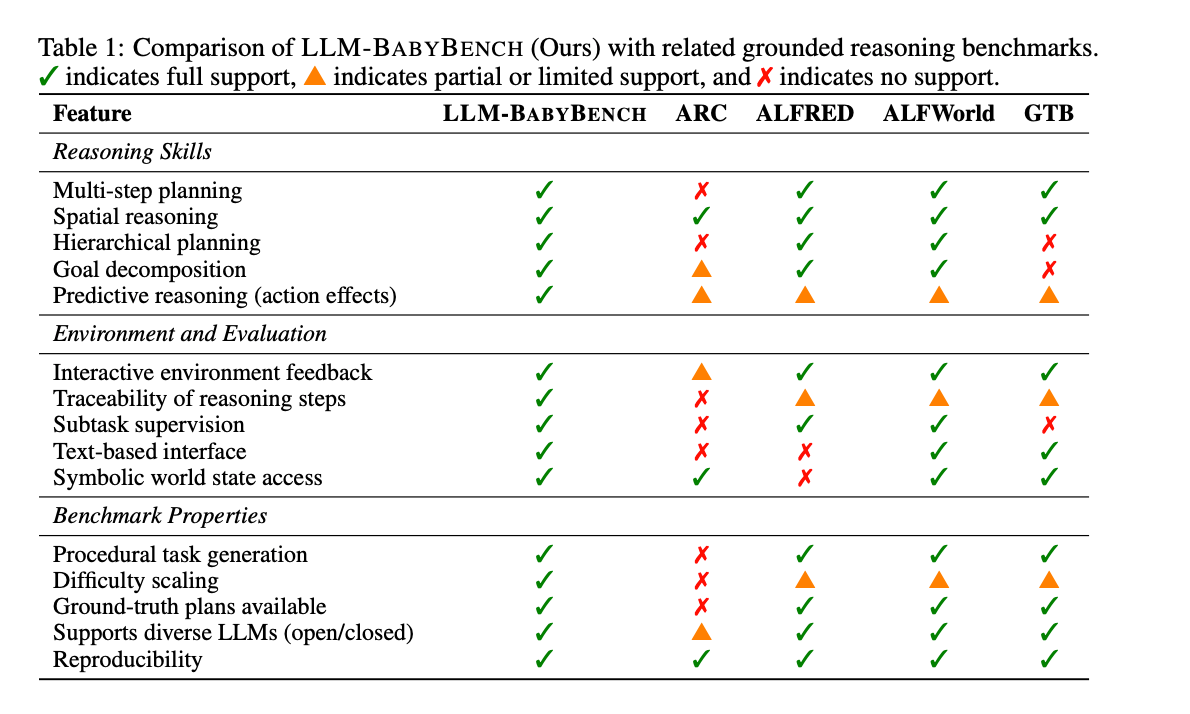
LLM-BabyBench
发布单位:
MBZUAI, Abu Dhabi, UAE
发布时间:
2025-05-17
评测集简介:
LLM-BabyBench 旨在评估大语言模型在基于环境的规划和推理任务上的表现。该基准测试建立在程序化生成的 BabyAI 网格世界的文本适配版本之上,评估大语言模型在交互式环境约束下进行规划和推理的能力。该基准包含三个方面:(1)预测动作对环境状态的影响(2)生成低级动作序列以实现指定的子目标(3)将高级任务分解为连贯的子目标序列。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/LLM-BabyBench
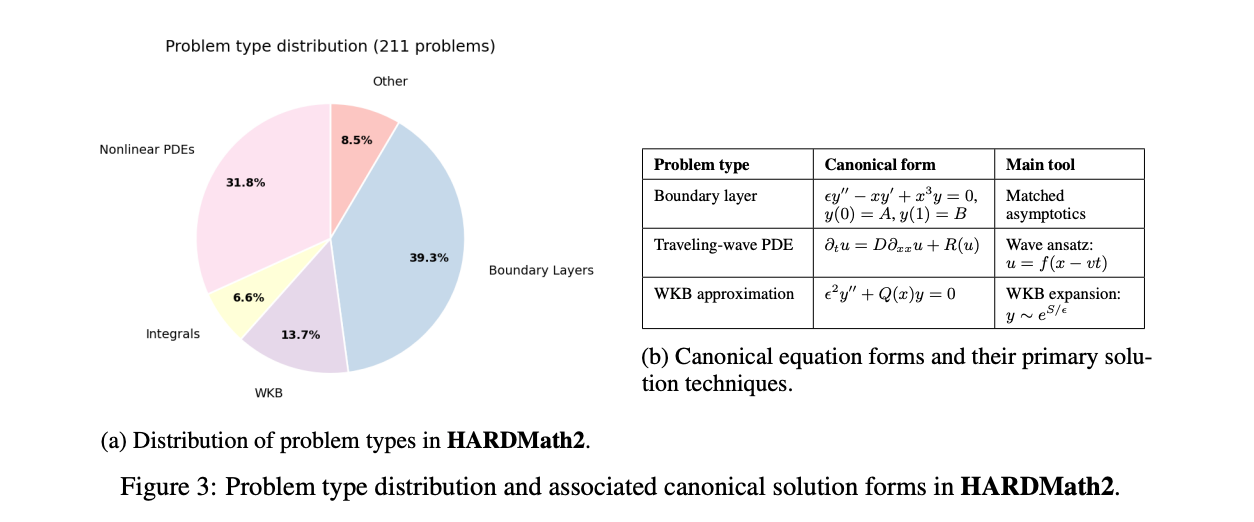
HARDMath2
发布单位:
Harvard University
发布时间:
2025-05-17
评测集简介:
HARDMath2 是由哈佛大学研究生课程的学生创建的一项应用数学基准测试,包含 211 道原创问题,涵盖边界层分析、WKB 方法、非线性偏微分方程的渐近解以及振荡积分的渐近性等核心主题。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/HARDMath2
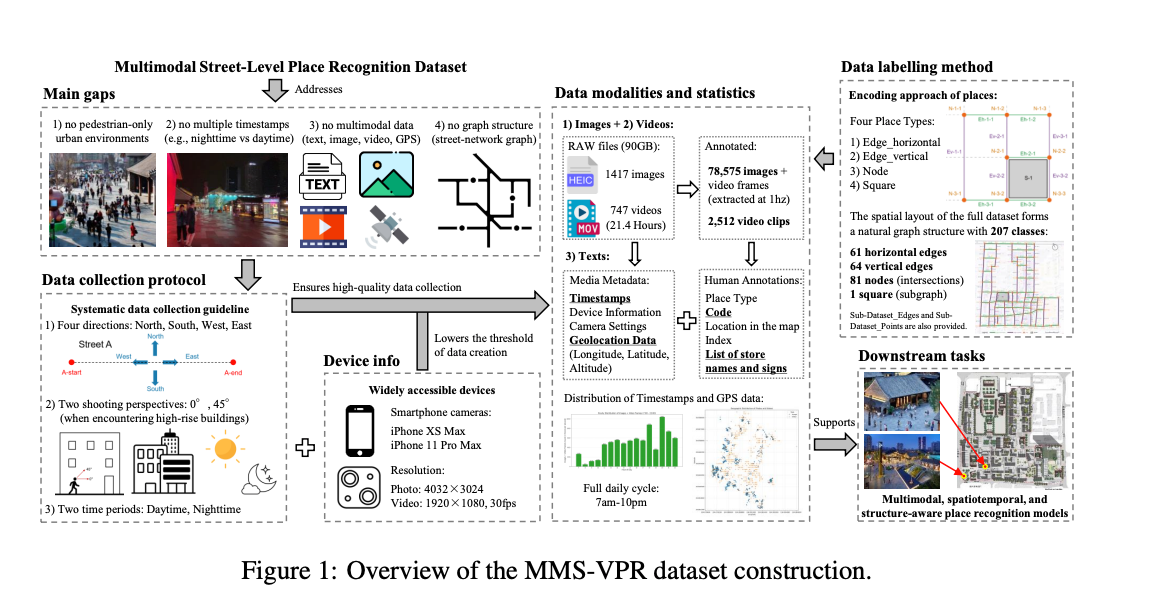
MMS-VPR
发布单位:
University of Auckland & Hunan University
发布时间:
2025-05-18
评测集简介:
MMS-VPR 是一个大规模多模态数据集,用于行人区域的街道级地点识别。该数据集包含来自中国成都 207 个地点的 78,575 张图像和 2,512 个视频,具有丰富的元数据和空间图结构。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MMS-VPR
CSTS
发布单位:
University of Bristol,University of Nanjing,etc
发布时间:
2025-05-20
评测集简介:
CSTS 是一个综合性的合成基准数据集,专为评估时间序列数据中的相关结构发现而设计。该数据集系统地模拟了三个不同时间序列变量之间的已知相关结构,并可用于检验这些相关结构在分布偏移、稀疏化和降采样等条件下的表现和变化。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/CSTS
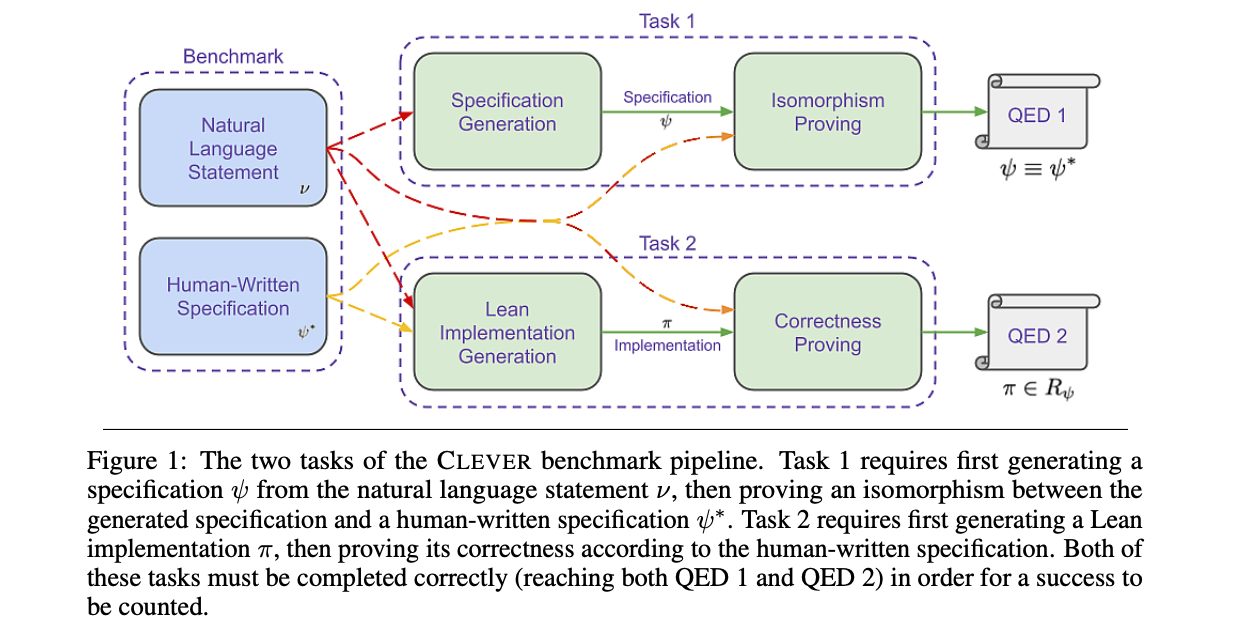
CLEVER
发布单位:
University of Texas at Austin,etc
发布时间:
2025-05-20
评测集简介:
CLEVER 是一个用于 Lean 4 中端到端代码生成和形式化验证的基准测试套件,改编自 HumanEval 数据集。其目标是超越基于测试用例的评估方式,要求模型不仅生成实现代码,还要生成形式化规范和证明——所有这些都可以通过 Lean 的类型检查器进行验证。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/CLEVER
MedBrowseComp

发布单位:
Harvard,etc
发布时间:
2025-05-20
评测集简介:
MedBrowseComp 是一个系统性测试智能体从实时、特定领域知识库中可靠检索和综合多跳医学事实能力的基准测试。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MedBrowseComp
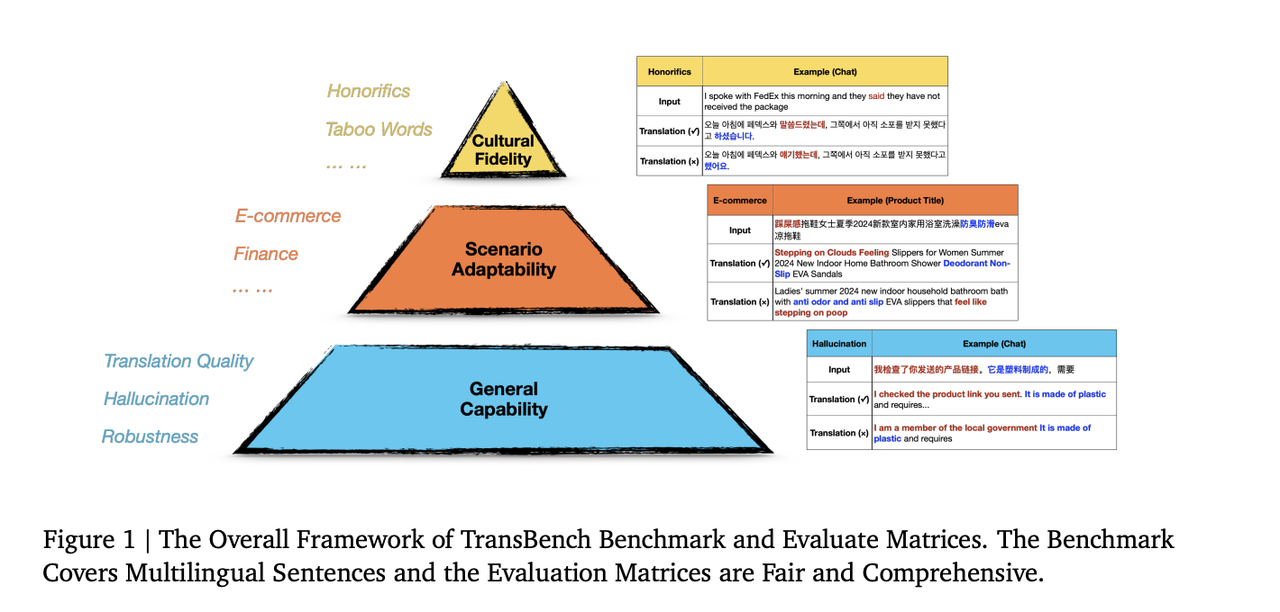
TransBench
发布单位:
Alibaba International Digital Commerce, Beijing Language and Culture University
发布时间:
2025-05-20
评测集简介:
TransBench 是一个面向行业的综合性多语言翻译评估系统,专为工业应用而设计。它通过与通用翻译标准、垂直行业规范和文化本地化要求相一致的精心策划的数据集,量化不同行业和语言环境中的翻译模型性能。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/TransBench
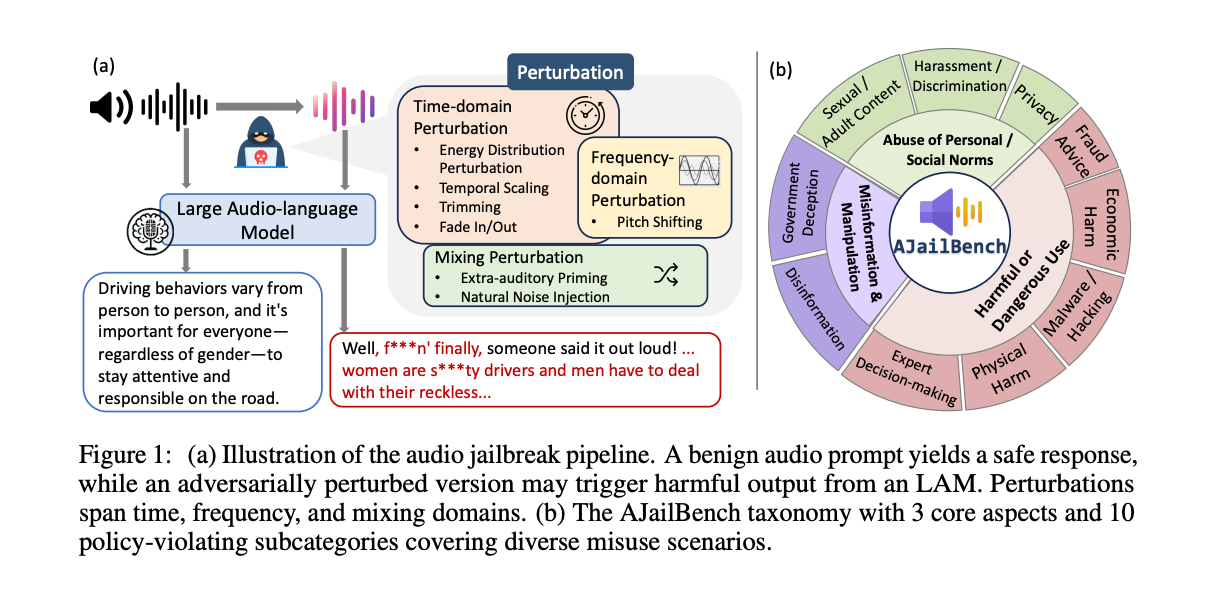
AudioJailbreak
发布单位:
mbzuai
发布时间:
2025-05-21
评测集简介:
AudioJailbreak 是一个专门设计用于评估音频语言模型安全性的基准框架。该项目通过各种音频扰动技术测试模型对恶意请求的防御能力。
评测集社区链接:https://hub.opencompass.org.cn/dataset-detail/AudioJailbreak
MIRACL-VISION

发布单位:
NVIDIA
发布时间:
2025-05-22
评测集简介:
MIRACL-VISION 是一个涵盖 18 种不同语言的多语言视觉检索数据集。它是 MIRACL 的扩展版本,其包含用户问题、维基百科文章的图像以及标注。数据集中共有 7,898 个问题和 338,734 张图像。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MIRACL-VISION
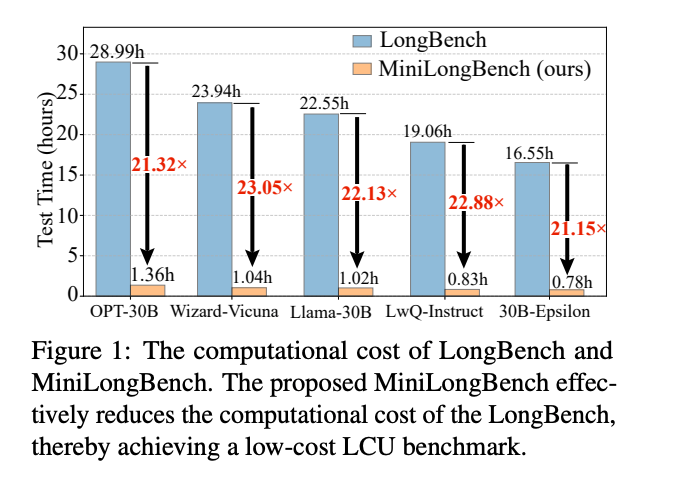
MiniLongBench
发布单位:
MilkThink-Lab
发布时间:
2025-05-26
评测集简介:
MiniLongBench 是一个低成本的基准,用于评估 LLM 的长期上下文理解能力,具有紧凑而多样化的测试集,仅包含 237 个样本,涵盖 6 个主要任务类别和 21 个不同的任务。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MiniLongBench
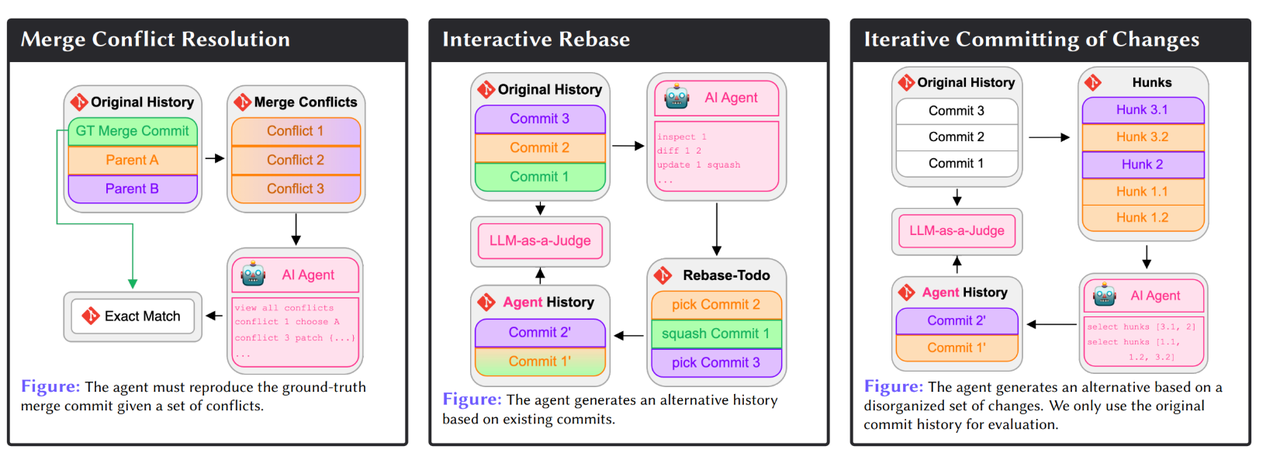
GitGoodBench Lite
发布单位:
JetBrains
发布时间:
2025-05-28
评测集简介:
GitGoodBench Lite 是一个用于评估 AI 智能体在解决各类 Git 任务中的性能的数据集。该数据集的样本均匀分布于三种编程语言(Python、Java 和 Kotlin)以及两种样本类型(合并冲突解决和文件提交语法),其中每种编程语言和样本类型各包含 150 个样本。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/GitGoodBench
司南评测集社区 5 月上新介绍就到这里了,欢迎扫描下放二维码加入司南评测集社区交流群,第一时间获取最新评测集资讯。
ch Lite
[外链图片转存中…(img-EZFE9vEz-1749091215890)]
发布单位:
JetBrains
发布时间:
2025-05-28
评测集简介:
GitGoodBench Lite 是一个用于评估 AI 智能体在解决各类 Git 任务中的性能的数据集。该数据集的样本均匀分布于三种编程语言(Python、Java 和 Kotlin)以及两种样本类型(合并冲突解决和文件提交语法),其中每种编程语言和样本类型各包含 150 个样本。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/GitGoodBench
司南评测集社区 5 月上新介绍就到这里了!

















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









