









继去年LAION-400M[1]这个史上最大规模多模态图文数据集发布之后,今年又又又有LAION-5B[2]这个超大规模图文数据集发布了。
其包含 58.5 亿个 CLIP [5]过滤的图像-文本对的数据集,比 LAION-400M 大 14 倍,是世界第一大规模、多模态的文本图像数据集,共80T数据,并提供了色情图片过滤、水印图片过滤、高分辨率图片、美学图片等子集和模型,供不同方向研究。
一起来看看。
今年大火的DALL·E 2 再次掀起了多模态图文匹配研究热潮。
在图文匹配领域,CLIP[5]模型使得在ImageNet上的zero-shot分类精度从11.5%提升到76.2%,受此启发,ALIGN[3]、BASIC[4]等大型图文多模态模型进一步改进,除了本身的模型优化之外,目前的进展其实都比较依赖底层的上亿图文对数据,但这些数据集及模型仅有少数公开,所以LAION提出了LAION-5B及在该数据集上训练的模型,并提供web界面提供预先计算的向量和搜索功能。
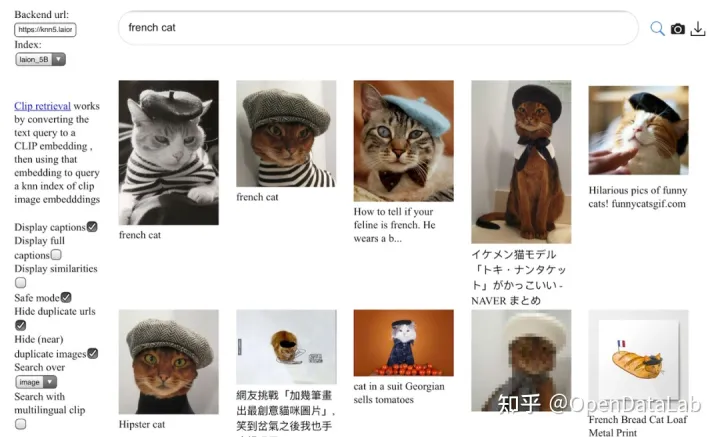
图1: LAION-5B检索样例。数据来源:https://laion.ai/blog/laion-5b/
LAION-5B通过CommonCrawl获取文本和图片,OpenAI的CLIP计算后获取图像和文本的相似性,并删除相似度低于设定阈值的图文对(英文阈值0.28,其余阈值0.26),500亿图片保留了不到60亿,最后形成58.5亿个图文对,包括23.2亿的英语,22.6亿的100+语言及12.7亿的未知语言。
官网:
https://laion.ai/blog/laion-5b/
数据集信息:
https://opendatalab.org.cn/LAION-5B
论文:
https://openreview.net/pdf?id=M3Y74vmsMcY
LAION-400M介绍:
https://mp.weixin.qq.com/s/vzyOF4esJCkBZDMiNScE5A
今天介绍围绕以下几个点展开:
一、数据集背景信息
CLIP[5]、DALLE[6]这些模型证明了大规模多模态数据的重要性,即使不需要手动标注,也能超越很多优秀的有监督模型,经典如CLIP使用400M对网络图文对进行训练,不仅在ImageNet上zero-shot超越在ImageNet 1.2M有监督数据上训练的resnet50性能1.9%,并且能够识别普通视觉模型无法识别的素描图、油画图、艺术图等(图2)。
紧接着发布的ALIGN[3]、GLIDE[12]等证实了这一点,但是这些大型数据集都没有开源,因此这一领域的研究,只集中在少数几个机构中,2021年公布的LAION-400M[1]是当时最大的公开图文数据集,本次发布的LAION-5B[2]是LAION-400M的14倍,足够规模的公开数据使得该领域的研究更多元化,能够让更多的研究者参与到这一领域的研究中。

图2: CLIP能够识别素描图、油画图和艺术图,但ResNet对这些识别较差。数据来源:https://openai.com/blog/clip/
各个机构陆续发布过多模态数据集及图像数据集,但是由于数量不多或并未公开,并不能在多模态预训练模型上取得较好的效果,这里将LAION和以前的部分数据集进行了简单对比。
1.1 图文对数据集
最开始,数据集均通过人工注释生成,如COCO[7]和Visual Genome[8],COCO Captions在COCO图片数据基础上,由人工标注图片描述得到。Visual Genome是李飞飞2016年发布的大规模图片语义理解数据集,含图像和问答数据,标注密集,语义多样。这两个数据集主要用于图像生成描述(Visual Genome也可以用于图像问答),然而由于图片数量较少,仅有330k和5M对,模型发展受到限制。
后来逐渐出现了非人工注释的多模态数据集,如Conceptual Captions 3M[9]和Conceptual Captions 12M[16],对应描述从网站的alt-text属性过滤而来。随着CLIP模型的出现,大规模预训练模型逐渐成为多模态领域趋势,类似的还有ALT200M[10]和ALIGN1.8B[3],数据集规模逐渐扩大到数十亿,虽然没有经过人工注释,但由于数据量大,在NLP、零样本视觉推理、多模态检索等多种下游任务中仍能取得良好甚至SOTA的效果。但可惜的是,CLIP所使用的4亿图文对以及ALIGN等数据集均没有公开。
去年公开的LAION-400M拥有4亿图文对,是当时最大的公开图文数据集,一经公开获取了很好的反响,也有多个模型基于该数据进行训练取得了较好效果,但相较官方CLIP仍有轻微差距,并且LAION-400M中含有大量令人不适的图片,对于模型,尤其是生成模型影响较大。比如stable diffusion模型,很多人会用来生成色情图片,产生了不好的影响,更大更干净的数据集成为需求。
这次公开的LAION-5B除了扩大规模之外,还提供了一些模型进行过滤,LAION训练了色情内容识别模型NSFW过滤绝大部分不适图片,水印检测模型可以过滤水印图片,由于部分隐私或不适内容若删除会影响研究丰富性,所以在总体数据内不会删除,会提供不同的子集用于不同用途。
1.2 图像数据集
大型如Instagram-1B、JFT300M、JFT3B均为私有数据集,暂未公开。
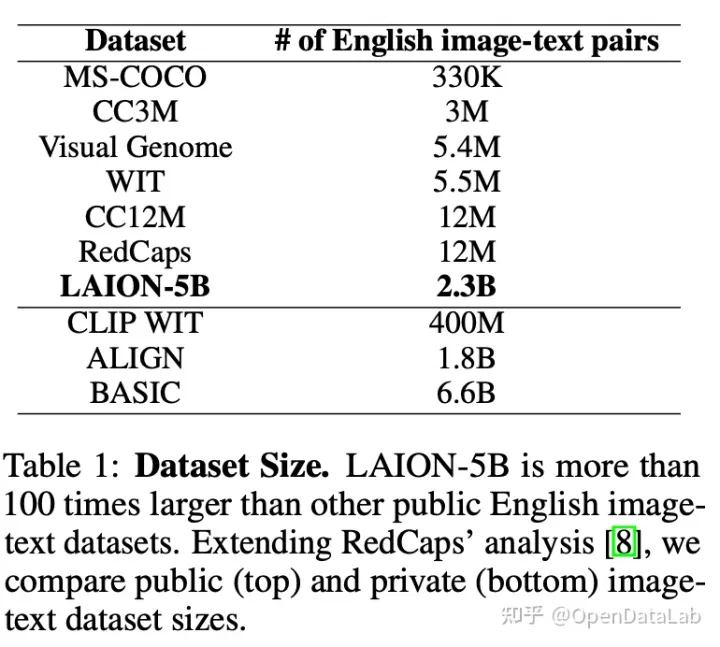
图3: 数据集大小比较,公开数据集(top)和私有数据集(bottom)。LAION-5B比其他公开数据集大100倍,数据来源:[2]
LAION-5B的数据规模目前最大,可以对许多未公开的多模态模型进行训练并获得较好效果,并公开了第一个开源的CLIP模型。并且数据多样,包含各种领域图片,对于后续研究提供了更多的方向,比如数据重叠、图片噪声、不适图片筛选、低资源语言、自然语言对于多模态的作用、模型偏差等等。
但如果将LAION-5B直接应用于工业,需要注意清洗图片,因为LAION-5B中含水印图片及不适图片,模型会因此产生偏差。
二、LAION-5B有什么
在LAION400M发布之后,在接连的研究中发现了未过滤引起的问题,受这些启发,除了50亿图文对之外,LAION还提供了多种子集。之前的研究中,为了限制生成模型不生成种族主义图片,尝试在训练集中删除了与暴力相关的物体、人和面部的图像,然而,这显然限制了模型的通用能力—比如人脸生成。因此,为了研究的多样性,在整体数据集中并没有删除此类内容,而是提供了多种子集。
除此之外,LAION还提供了复现的CLIP等模型,展示了基于LAION训练的模型拥有不输于原模型的能力。和KNN索引、Web界面方便检索合适的图片。
当然,为了大规模数据集方便下载,LAION也提供了img2dataset分布式下载,可以指定图像和文本大小,可以20个小时内单个节点下载1亿张图像(1Gbps速度,32G内存和16个内核的i7 CPU)
2.1 子集
LAION-5B中包括23.2亿的英语,22.6亿的100+语言及12.7亿的未知语言,我们将子集分别标记为:
● laion2B-en
● laion2B-multi
● laion1B-nolang
LAION训练了一个基于CLIP嵌入的色情内容识别模型NSFW,可以过滤3%的不适图片,NSFW准确率约96%,过滤后有子集:
● laion2B-en-safety
● laion2B-multi-safety
● laion1B-nolang-safety
LAION训练了一个水印识别模型,过滤后有子集:
● laion2B-en-watermark
● laion2B-multi-watermark
● laion1B-nolang-watermark
一个170M的超分辨率子集:
● laion-high-resolution
一个120M的美学图片子集,可以用来做图片生成:
● laion-aesthetic
更多可以参考:
2.2 开源模型
对现有未开源的多模态模型,LAION在子集上重新训练或微调,取得了较好的效果。
CLIP:通过openCLIP开源了CLIP模型,分别在LAION-400M和LAION-5B上训练,前者效果略低于OpenAI,后者zero-shot效果高于OpenAI。
BLIP:重新在LAION-400M中115M子集上训练,再使用CLIP对候选描述排序,评测后优于其他模型,用于描述生成和图文匹配。
Glide:在LAION-2B对Glide模型进行微调,获得了不错的效果。
除此之外,还提供了水印识别模型和色情内容识别模型NSFW。
2.3 KNN index/web界面
LAION使用autofaiss工具构建了KNN索引,共800GB。
为了方便使用,将索引集成到网站中。web界面基于查询图像/文本来搜索图像/文本。通过CLIP的embedding来检索语义相似性较高的图像文本,鉴于高分辨率图片的丰富性,可以生成图像子集来训练自定义模型,也可以选择特定训练目的的图像分辨率。
检索网站左侧添加了safe mode,可以筛选不适图片。
检索网站:

图4: web检索demo
三、LAION可以做什么任务
LAION提供了大规模的图文数据,可以用来做大部分多模态及CV工作,多模态方面包括大规模预训练、图文匹配、图像生成(图像生成、图像修复/编辑等)和文本生成(图像生成文本、VQA等)等下游任务,CV方面包含分类等,LAION也提供了使用数据集训练的模型作为参考。
3.1 图文匹配及多模态预训练
包括但不限于任务:多模态预训练、图文匹配、图文检索。
CLIP模型使用对比学习将图像和文本嵌入到相同空间,标志着图像-文本的多模态的进展,用于图文匹配/检索、zero-shot分类等领域。但CLIP并未公开训练数据,因此LAION分别使用LAION-400M和LAION-2B重新训练了CLIP模型,准确率和OpenAI版本不相上下。
3.2 生成任务
● 图像生成
包括但不限于任务:高分辨率图像生成、图像修复/编辑、文本生成图片、条件图像生成。
LAION提供了子集来过滤不适图片和水印图片,为图像生成进一步提供了条件。目前有不少模型可以基于LAION子集来生成,DALLE[6]这种自回归模型或者GLIDE[12]这种扩散模型,以下给出几个例子:
- Stable Diffusion[13]使用LAION-5B的子集,在压缩的空间对图像进行重建,可生成百万像素的高分辨率图片,用于图像修复、图像生成等。
- VQ-Diffusion[14]模型使用矢量量化变异自动编码器,在LAION-400M训练文本生成图像的模型,获得更高的图像质量。
- Imagen[15]在LAION-400M的子集上训练,使用强大的语言模型抽取特征,并指导生成对应文本的高质量图像,击败DALLE-2[20]实现SOTA。
- 也可以挑选其中领域图片进行生成,如人脸生成FARL[17]。
● 文本生成
包括但不限于任务:图像生成文本、VQA、Visual Entailment
- BLIP[18]重新在LAION-400M中115M子集上训练,再使用CLIP对候选描述排序,评测后优于其他模型,用于描述生成和图文匹配。
- MAGMA[19]在LAION子集上训练,基于适配器的微调来增强语言模型的生成,为视觉问题生成答案,仅使用simVLM的0.2%的数据量但生成了较好的结果。
3.3 分类任务
可以做zero-shot、finetune和训练。
通过web搜索子集或官方提供的子集,可以做构建分类识别,水印识别、色情内容识别、面部特征学习等等。也可以通过提供的大规模预训练模型,在下游任务做zero-shot和finetune。
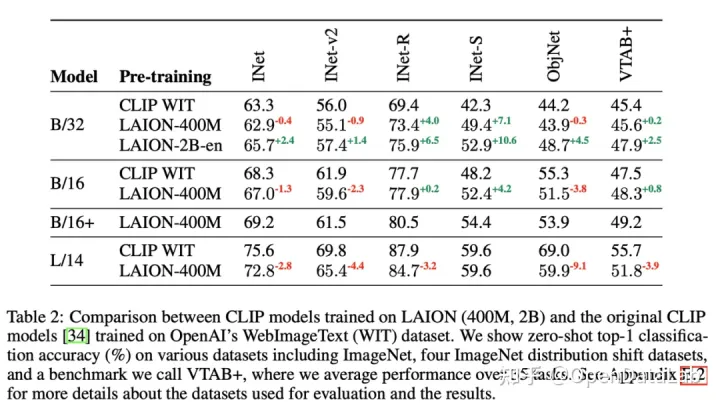
图5: 对比了WIT(官方)、在LAION-400M和LAION-2B-en上训练的CLIP模型在下游数据集的zero-shot性能对比,可以看到LAION训练的模型性能优越。数据来源:[2]
3.4 其他任务
LAION数据丰富,可以筛选需要的数据做其他任务,比如可以在LAION-2B-multi中筛选指定语言数据做低资源语言任务,可以做数据重叠对模型的影响、模型偏见等等。
四、如何使用LAION
对于有丰富GPU资源的同学,在训练任务时,可以使用全集/子集数据进行大规模训练。对于资源相对有限的同学,无法进行大规模训练,依然可以使用LAION预训练模型进行zero-shot、finetune等研究,也可以将其作为图像资源池自行检索所需图像。
4.1 大规模训练
可以使用全集/子集来训练,完成多模态、视觉领域相关任务,往往对资源需求较大。
● 全集为58.5亿图文对,通过CLIP过滤,含有少量噪声和不适数据。
● 子集参考2.1中提供的多种子集,包括但不限于无不适图片子集、无水印子集、超分辨率子集、美学子集等等。
● 如果没有合适的子集,也可以通过web检索页面,到合适的数据下载,可以生成图像子集进行训练,也可以选择适合训练的图像分辨率,该方法的好处是可以根据自定义场景选择图片。
4.2 少量训练
对于资源有限的工程师,可以选择LAION-5B中所需数据和LAION-5B提供的预训练模型,进行训练。
● 数据方面
可以选取LAION-5B的部分数据进行训练,比如通过web检索界面检索自定义场景图片,或者使用有/无水印图片、高分辨率图片、美学分数较高图片等等,进行小规模训练。
● 模型方面
可以使用LAION提供的预训练模型对下游进行zero-shot、few-shot或finetune。
- zero-shot/few-shot:官方提供了大规模预训练的开源模型,CLIP、BLIP等,效果显著,基于LAION训练的CLIP性能与原模型不相上下。基于LAION-400M训练的CLIP性能可以参考图6。
- finetune:官方提供了微调方式供参考:https://github.com/mlfoundations/wise-ft,也可以采取常规的finetune方式进行训练。
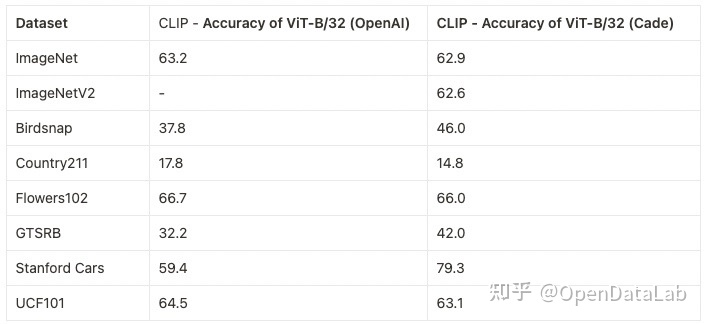
图6: CLIP基于LAION-400M对ImageNet、ImageNetV2、Birdsnap、Country211、Flowers102、GTSRB、Standford Cars、UCR101等数据集进行测试,和OpenAI的CLIP性能不相上下。数据来源:https://github.com/mlfoundations/open_clip
五、总结
LAION-5B,这个包含超过50亿图像文本对的数据集,进一步扩展了语言视觉模型的开放数据集规模,使得更多研究者能够参与到多模态领域中。并且为了推动研究,提供了多个子集用于训练各种规模的模型,也可以通过web界面检索构建子集训练。已有多个模型和论文证明了基于LAION子集训练的模型能够取得良好甚至SOTA的效果。
参考文献
[1] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
[2]Christoph Schuhmann, Romain Beaumont, Cade W Gordon, Ross Wightman, mehdi cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, Richard Vencu, Ludwig Schmidt, Robert Kaczmarczyk, Jenia Jitsev. LAION-5B: An open large-scale dataset for training next generation image-text models,2022.URL https://openreview.net/pdf?id=M3Y74vmsMcY
[3]Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yun- Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. CoRR, abs/2102.05918, 2021. URL https://arxiv. org/abs/2102.05918.
[4]Hieu Pham, Zihang Dai, Golnaz Ghiasi, Hanxiao Liu, Adams Wei Yu, Minh-Thang Luong, Mingxing Tan, and Quoc V Le. Combined scaling for zero-shot transfer learning. arXiv preprint arXiv:2111.10050, 2021.
[5]Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
[6]Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. CoRR, abs/2102.12092, 2021. URL https://arxiv.org/abs/2102.12092.
[7]Tsung-YiLin,MichaelMaire,SergeBelongie,JamesHays,PietroPerona,DevaRamanan,Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
[8]Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123(1):32–73, 2017.
[9]Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1238. URL https://aclanthology.org/P18-1238.
[10]Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Li- juan Wang. Scaling up vision-language pre-training for image captioning. arXiv preprint arXiv:2111.12233, 2021.
[11]Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015. doi: 10.1007/s11263-015-0816-y.
[12]Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models, 2021. URL https://arxiv.org/abs/2112.10741.
[13]Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. CoRR, abs/2112.10752, 2021. URL https://arxiv.org/abs/2112.10752.
[14]Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. CoRR, abs/2111.14822, 2021. URL https://arxiv.org/abs/2111.14822.
[15]Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022. URL https://arxiv.org/abs/ 2205.11487.
[16]Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3558–3568, 2021.
[17]YinglinZheng,HaoYang,TingZhang,JianminBao,DongdongChen,YangyuHuang,LuYuan, Dong Chen, Ming Zeng, and Fang Wen. General facial representation learning in a visual- linguistic manner. CoRR, abs/2112.03109, 2021. URL https://arxiv.org/abs/2112. 03109.
[18]Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation, 2022. URL https://arxiv.org/abs/2201.12086.
[19]Constantin Eichenberg, Sidney Black, Samuel Weinbach, Letitia Parcalabescu, and Anette Frank. MAGMA - multimodal augmentation of generative models through adapter-based finetuning. CoRR, abs/2112.05253, 2021. URL https://arxiv.org/abs/2112.05253.
[20]Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents, 2022. URL https://arxiv.org/abs/ 2204.06125.
作者丨Jorie 希望世界和平无bug
- End -
以上就是本次分享,更多精彩的数据集干货,不容错过。还有哪些想看的内容,快来告诉小助手吧。更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying加入OpenDataLab官方交流群。

















 2022
2022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









