







感谢知乎@东林钟声撰写了本篇论文解读的底稿,论文一作为22级交大联培博士黄思渊,更正修改后形成本文。
A3VLM基于sphinx模型,通过多轮对话形式,精准理解并执行面向复杂铰链结构的机器人任务。代码和模型均已开源。

论文地址:
https://arxiv.org/abs/2406.07549
代码地址:
https://github.com/changhaonan/A3VLM
模型地址:
https://huggingface.co/SiyuanH/A3VLM7B
![]()
研究背景
在具身智能这个概念下,参考知乎@东林钟声对现在主流具身智能的技术路线分类如下:

按照上述技术流程分类,A3VLM属于利用LLM的问答能力从文本中提取Affordance或者可动属性(转动、平移)的模型。更具体的来说,A3VLM将人类指令理解、具身动作输出、关节理解以及局部知识理解等机器人领域的知识统一建模为VQA多轮对话形式。这种统一的表征模式赋予了A3VLM多方面的能力,使其能够更加精准地理解和执行复杂的任务。
-
人类指令理解:A3VLM能够准确解析自然语言指令。
-
具身动作输出:模型不仅理解指令,还能根据指令规划具体的机器人动作。
-
关节理解:A3VLM能够识别和理解对象的关节结构,为精确操作提供空间结构信息。
-
局部知识理解:通过局部特征的识别,模型能够理解场景中的具体元素,实现更精细的操作。
A3VLM部署后推理流程如下图所示。面对用户提出的“如何剪纸”这一问题,A3VLM首先识别出了剪刀可操作部分在三维空间中的位置,以及动作需要的动作类型。这一步不仅展示了A3VLM对物体功能的理解,也体现了其在真实场景中快速定位的能力。紧接着,A3VLM进一步确定了剪刀腿的关节结构,为执行后续的操控动作提供了必要的空间信息。通过多轮对话,A3VLM能够指导机器人以最合适的方式进行操作。
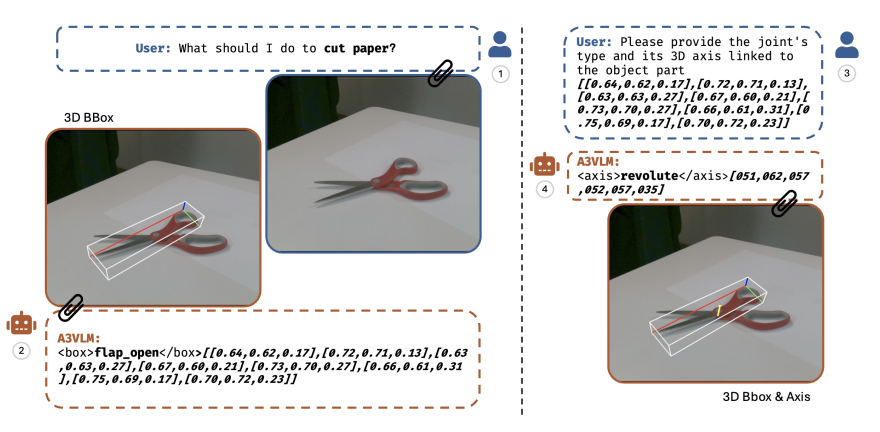
从动作表征角度,A3VLM属于object-centric的robotics多模态大模型。在技术层面,主要的难点在于 1. 数据格式以及构建;2.模型的搭建。
数据格式和构建
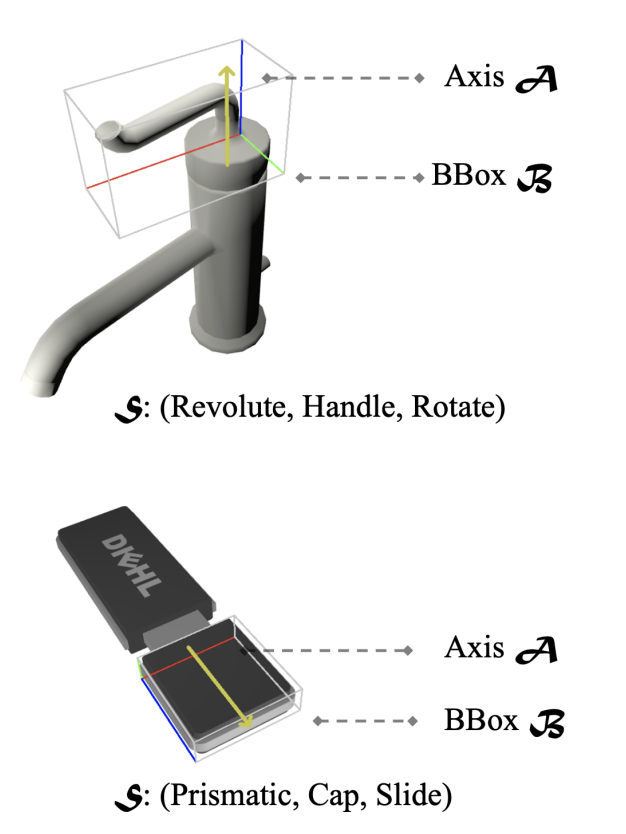
A3VLM将物体的可动性分为两大类(转动revolute以及平动prismatic),为了更加完备的描述,采用了以对象中心的表示法三元组的结构对物体可动region进行描述,<B, A, S>,其中B表示Bbox,A表示轴,S表示类别。B由8个顶点的(x,y,z)进行描述,A由轴的2个端点的(x,y,z)进行描述,由于输入是2d的图片,所以深度进行了0-1归一化。
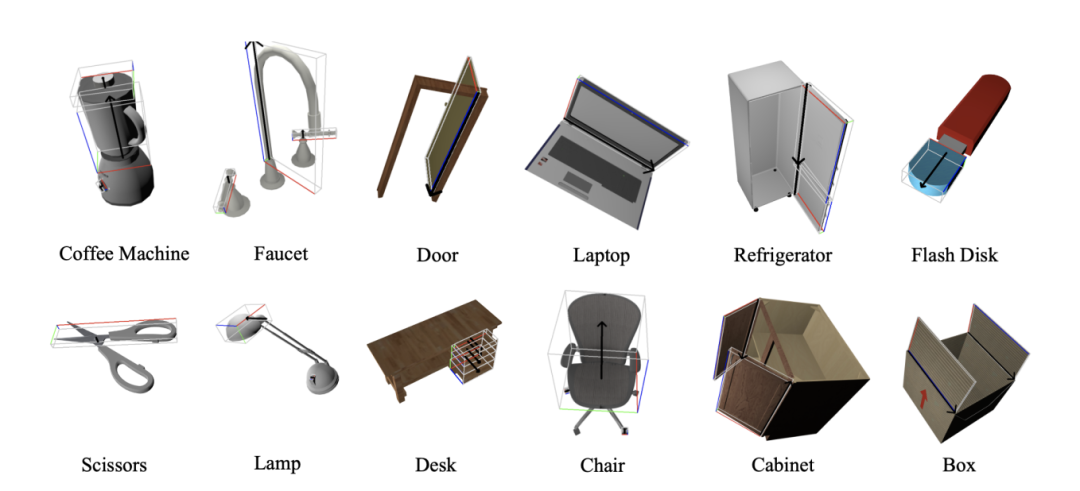
在数据构建使用了PartNet-Mobility提供的URDF,包含46个类别中的2000多个不同铰接对象。使用PyRender得到渲染的RGB图像,包含随机相机位置、照明和关节值,以生成40个不同图像。这一步可以得到<B,A,S>的原始标注,但是为了用来训练VLM,还需要进一步对格式进行处理。标注可视化结果如下图所示。同时,对于动作推理(action grounding)任务数据,作者利用GPT4生成大量物体类别相关的动作及操作描述,丰富了训练集的文本标注。
作者构建了由4个子任务构成的训练数据。在不同的子任务中,通过提示符(prompts)和语言任务描述,A3VLM能够分别定位对象中可操作的部分并提供必要的关节信息以执行操作。其中,4个子任务的Instruction中的BBox B、Axis A和Joint Type S,可以从之前的原始标注中进行处理得到。注意到,原有PartNet-Mobility数据集中的模型多缺少纹理,且数量受限,作者利用ControlNet进行进一步的数据增广。

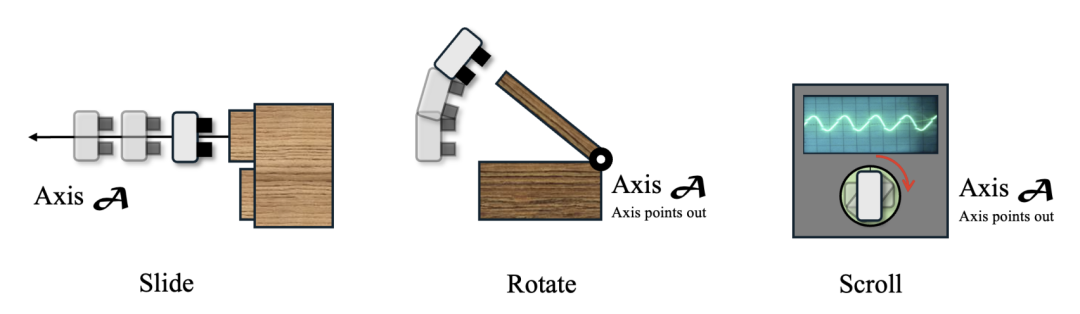
在连接动作执行方面,A3VLM根据链接的关节类型选择相应的原子动作(action primitive),确保动作与机器人的功能性完美对接。对于直线运动关节,执行滑动;对于旋转关节,执行旋转,除非目标链接被标记为特殊部件,如瓶盖或扭动按钮,此时执行扭动动作。选定行动类型后,A3VLM确保抓取姿态与旋转轴对齐或在边界框内选择接触点,生成精确的运动轨迹,指导机器人执行复杂动作。
模型搭建与训练
在连接动作执行方面,A3VLM根据链接的关节类型选择相应的原子动作(action primitive),确保动作与机器人的功能性完美对接。对于直线运动关节,执行滑动;对于旋转关节,执行旋转,除非目标链接被标记为特殊部件,如瓶盖或扭动按钮,此时执行扭动动作。选定行动类型后,A3VLM确保抓取姿态与旋转轴对齐或在边界框内选择接触点,生成精确的运动轨迹,指导机器人执行复杂动作。

![]()
实验效果
1 仿真器测试
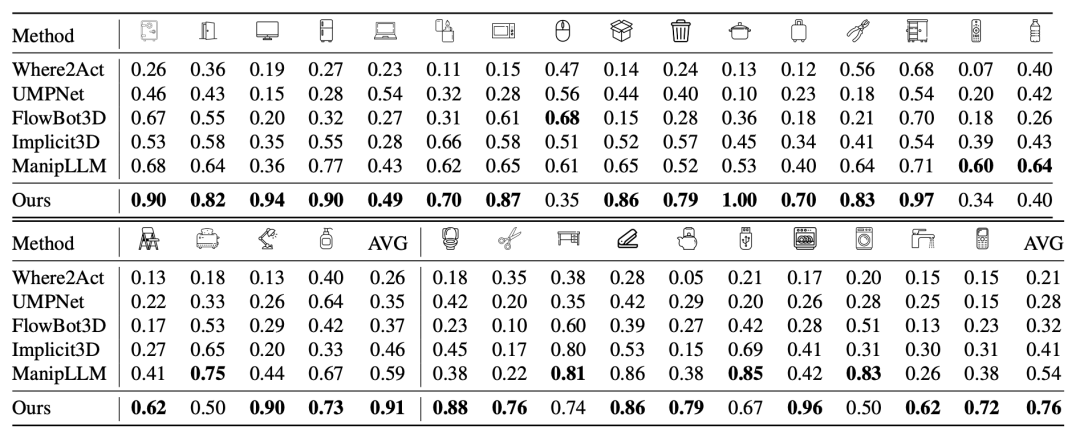
下表展示了A3VLM在操作可动物体方面的卓越性能,相较于其他五个基线方法,A3VLM在大多数物体类别上均以显著的优势胜出。这一结果充分证明了A3VLM在操纵可动铰链/关节物体方面的有效性。
2 真实场景测试
即便A3VLM仅在仿真数据集上进行训练,但得益于大语言模型和大视觉模型的强大泛化能力,A3VLM在真实图像可动性Grounding中实现了很好的效果。特别值得注意的是,A3VLM能够在具有反射性或透明表面的物体上正确执行推理,例如微波炉、锅盖和可乐瓶。这些物体对于基于点云的方法来说极具挑战性,因为这些物体的不准确深度信息常常导致识别错误。

3 真机实验
如下图所示,在真实世界中,A3VLM可以使用简单的原子动作(action primitive)来成功对铰链物体进行操作。

关注OpenGVLab 获取通用视觉团队最新资讯

🔗开源链接:https://github.com/OpenGVLab
📮官方邮箱:opengvlab@pjlab.org.cn
😊转载,加群,咨询博士招生等,私信GV小助手(二维码见上方)















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









