







"OpenLoong" 是全球领先的人形机器人开源社区,秉承技术驱动与开放透明的价值观,致力于汇聚全球开发者推动人形机器人产业发展。由国家地方共建人形机器人创新中心发起的 OpenLoong 项目,是业内首个全栈、全尺寸的开源人形机器人项目,有着人人都可以打造属于自己的机器人的美好愿景,旨在推动人形机器人全场景应用、助力具身智能时代的到来。
若您有更多想法或问题,欢迎 加入 OpenLoong 开源社区,在论坛发起讨论,与国地中心的技术专家深入交流,碰撞出更多技术灵感与实践火花!社区内将随时更新活动信息,上传技术文档,在这里,我们一起探索人形机器人技术,共享创新成果;在这里,我们一起见证开源的力量!
在人形机器人和具身智能快速演进的今天,“数据”成为能否构建强大智能体的关键资源之一。然而,具身智能的数据采集与处理,远非传统 CV/NLP 任务中“抓图下文”那般简单,尤其在人形机器人这一高度耦合的系统中,数据的采集方式、组织结构、跨平台复用能力乃至行业标准均面临一系列棘手挑战。
本文结合国家与地方共建人形机器人创新中心(以下简称“国地中心”)在构建人形机器人数据集过程中的一线经验,总结了三大核心问题及技术应对思路,期望对从事具身智能、机器人研发的工程师和研究人员提供启发与参考。
问题一:数据采集效率低、成本高
高质量具身数据,仍离不开人机协同的“重体力活”
尽管仿真环境(如 Isaac Gym 、MuJoCo 、Habitat 等)已广泛用于机器人策略训练,但当前阶段仿真合成数据与真实世界数据存在非小的 domain gap 。特别是在力觉、摩擦、多接触点动态变化等方面,真实机器人操作数据仍是无法替代的关键资源。
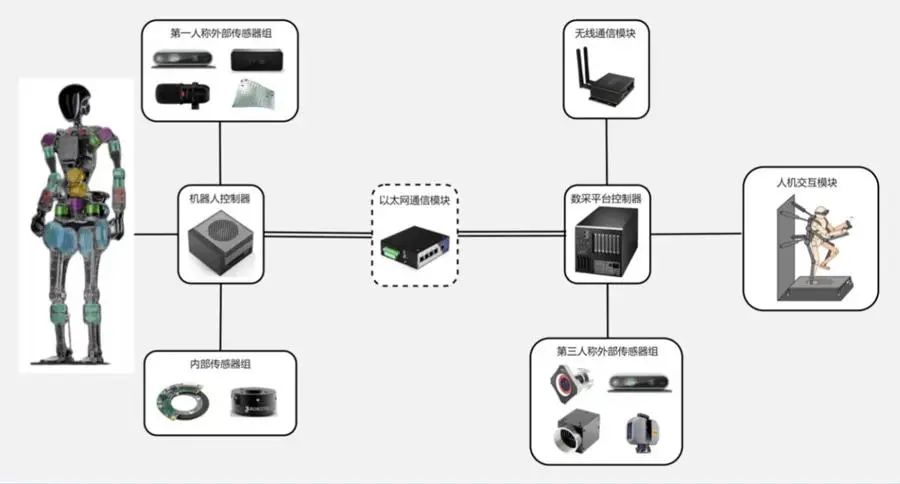
在国地中心的实际工作中,为保证数据质量,完成任务仍然需要通过人类遥控真实人形机器人。一个典型的采集场景如下:
操作人员数:每套采集设备需 1–2 人协同作业
任务时长:每条作业数据约为 15 秒
日产数据量:300~500 条(在持续运行一整天的理想条件下)
对于大模型训练所需的海量样本规模而言,这种“人驱动数据生产”的方式,效率过低、成本过高,严重制约了具身模型能力的上限。

图片来自互联网
解决路径一:构建集成化数据作业平台
为了从根本上提升效率,国地中心提出“工程自动化”路径,通过构建集任务管理、动作配置、采集控制、数据处理与上传等于一体的集成数据平台,实现:
多任务批量下发、自动化采集控制
数据实时打标签、自动整理上传
与视觉同步系统、遥操作终端无缝对接
这种方式可类比“数据采集工厂”的流水线式设计,大幅降低人力干预比例。
解决路径二:降低硬件层成本门槛
此外,硬件设备本身的高成本也是瓶颈之一。国地中心通过:
自研或改造人形机器人平台,减少冗余部件
优化遥操作系统(如使用低成本力反馈外骨骼手套
提高数据采集稳定性,降低故障维护成本
从软硬件两端共同降低单位样本采集成本,是实现大规模数据生产的关键。
解决路径三:仿真平台数据增广
数据增广旨在通过多种手段扩充已有数据集规模与多样性,高效、低成本地实现规模化数据集构建。主要方法包括改变环境参数和改变机器人动作轨迹:
1. 基于环境参数改变的数据扩增:不同参数、不同条件的改变都可用于生成多样化的数据样本。结合仿真引擎自动化生成的大量可控的训练样本,极大降低真实场景数据采集的成本与难度。例如通过调整光源的强度、方向、颜色等参数,模拟不同时间段(如白天强光、傍晚弱光)和天气(晴天、阴天、雨天阴影效果)下的光照条件;对场景中的物体表面纹理进行修改,如将光滑桌面纹理变为磨砂质感,或者改变墙壁的壁纸图案等。
2. 基于动作轨迹的数据扩增:为机器人规划不同的动作轨迹,包括机械臂运动轨迹、速度、转弯角度以及手臂操作时的伸展范围、抓取角度等。通过在不同环境和布局下执行这些新的动作轨迹,实现数据N*M倍的扩增。

图片来源互联网
问题二:数据难以跨平台复用
各机器人“方言”不同,数据难以迁移复用
当前的人形机器人数据采集方法多数集中在关节层数据,如各自由度的角度、速度、力矩等。然而由于机器人关节结构差异极大(例如腿部使用串联/并联结构、DOF数不同),同样的任务数据在不同机器人平台上无法直接复用。
这种平台依赖性带来严重后果:
数据孤岛化,无法复用已有采集成果
每增加一个机器人平台,需重新构建采集工作流
无法实现“数据网络效应”,难以通过规模化降低成本
解法一:采集通用层次的数据
一种思路是从“平台无关”的层面入手,脱离关节结构依赖,直接采集人体运动数据或机器人末端数据,后期通过绑定人形机器人模型与逆运动解算实现不同构型机器人的通用,如:
使用人体动捕系统采集人类行为轨迹(如 Mocap 数据)
记录机器人末端执行器的笛卡尔轨迹 + 操作语义
便携式夹爪(UMI)采集末端轨迹,脱离机器人本体
这种方式可与“人形骨架 → 动作驱动模型”理念结合,形成具备普适性的行为-控制解耦结构。
解法二:构建适配不同结构的具身大模型
另一条路径更具挑战性但也更具前景:通过大模型结构设计,在模型内部构建对不同机器人拓扑结构的适配机制。思路包括:
输入层:
对不同构型进行归一化编码(如基于机器人URDF自编码器)
中间层:
训练具身模型对多个机器人行为的迁移能力(如Skill Generalization)
输出层:
根据机器人平台结构动态生成低层控制目标
类似思路已在Meta’s RoboSet、Google RT-X、RoboHive中有所实践。
图片来源互联网
问题三:缺乏统一的数据标准规范
数据共享难、协同低、模型训练不通用
当前具身智能相关数据还处于“诸侯割据”状态。不同机构、平台、项目采集的数据结构、字段定义、时间戳对齐方式、标注语义等均存在差异,造成:
很多高质量数据无法直接为他人所用
模型复现难度大,通用性训练数据集稀缺
开源模型与开源数据之间缺乏接口标准
技术建议:推动具身数据的标准化制定
国地中心提出推动具身智能数据的标准化流程,主要包括:
统一数据格式(如支持 ROS bag、JSON、HDF5等结构)
明确关键字段(如时间戳、动作类型、末端位置、语义标签)
建立数据质量评估体系(如对齐误差、感知同步准确度)
制定平台间数据映射接口(如通过通用骨架/中间语义桥接不同平台)
这不仅能提升数据在多模型、跨任务间的适配能力,也为构建“开源具身数据生态”打下技术基础。
构建可持续的数据生态,具身智能才能走得更远
构建具身智能所需的数据体系,远比我们在 CV/NLP 时代面对的数据要复杂得多。它牵涉到:
感知与控制的多模态实时同步
多平台机器人间的结构不一致
硬件成本与操作人力的长期投
标准制定与生态协同的复杂协调
但也正是因为挑战巨大,才更需要行业机构如国地中心这样的“工程中枢”率先投入、探索路径,为行业走向规模化具身智能铺平道路。
未来,我们期望看到一个数据可复用、模型能泛化、标准被共享的新范式真正落地。在此之前,每一次采集、每一条轨迹、每一个数据字段的定义,都是值得深思与设计的关键一步。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









