







书接上文,在《【AIGC】本地部署 ollama(gguf) 与项目整合》章节的最后,我在 ollama 中部署 qwen1_5-14b-chat-q4_k_m.gguf 预量化模型,在非 Stream 模式下需要 89 秒才完成一轮问答,响应速度实在是太慢,后续需要想办法进行优化…
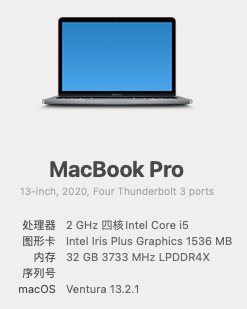
PS:本人使用的是 2020 年 Intel 版本的 Macbook Pro(以下简称“MBP”)。如下图:
1. Ollama 模型性能对比
为了解决这个问题,找很多 ollama 的资料,基本上可以确定 3 点信息:
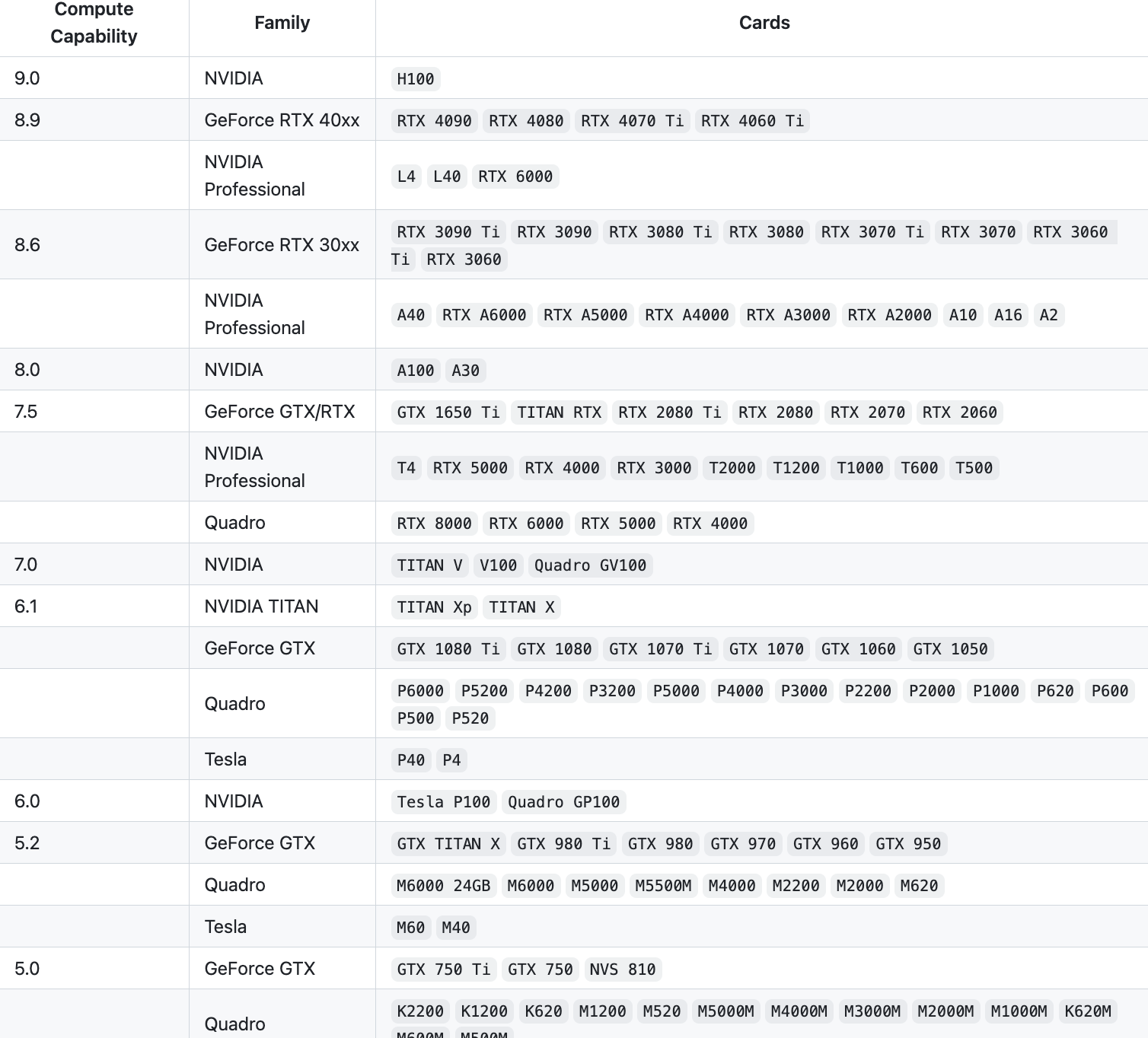
- ollama 会自动适配可用英伟达(NVIDIA)显卡。若显卡资源没有被用上应该是显卡型号不支持导致的。如下图:
- ollama 支持 AMD 显卡的使用,如下图:

- 至于 Apple 用户 ollama 也开始支持 Metal GPUs 方案

欸…看到这里好像又有点希望了,我的 MBP 估计也支持 Metal 方案吧🤔,接着我就到 Apple 官网查了一下 Metal 的支持情况。如下图:

(其实 ollama 上说的支持 Metal GPUs 的方案指的是使用 M 系列芯片的 Apple 用户,像我这种 Intel 芯的是不支持的。可惜这个我是后来才知道的,现在的这个 moment 我还抱有一丝的幻想😭…)
当时我就陷入自我怀疑了,难道是预量化模型的缘故只能适配到 CPU ?带着这个疑问又下载了一个 Qwen chat 版本进行了同环境的对比验证,如下图:
# 使用 ollama 调取 chat 版本模型(qwen:14b-chat-q4_K_M),耗时 69 秒
(transformer) (base) MacBook-Pro:python yuanzhenhui$ /Users/yuanzhenhui/anaconda3/envs/transformer/bin/python /Users/yuanzhenhui/Documents/code_space/git/processing/python/tcm_assistant/learning/local_model.py
>>> function ollama_transfor_msg totally use 69.74513030052185 seconds
>>> 是的,中医理论可以解释并尝试解决这些症状。
全身乏力和心跳过速可能是由多种原因引起的。在中医看来,这可能与脏腑功能失调、气血不畅、阴阳失衡等因素有关。
例如,心气不足可能导致心跳过速,而脾虚则可能导致全身乏力。另外,如果肝脏的功能不好,也可能导致这种症状。
因此,治疗方案可能会根据你的具体情况进行调整,可能包括中药、针灸、推拿等方法。同时,中医强调调养身体的整体健康,包括饮食习惯、生活方式等方面,也会对改善这些症状有帮助。
# 使用 ollama 调取 gguf 版本模型(qwen:14b-chat-q4_K_M),耗时 90 秒
(transformer) (base) MacBook-Pro:python yuanzhenhui$ /Users/yuanzhenhui/anaconda3/envs/transformer/bin/python /Users/yuanzhenhui/Documents/code_space/git/processing/python/tcm_assistant/learning/local_model.py
>>> function ollama_transfor_msg totally use 90.6007969379425 seconds
>>> 中国传统医学,也就是中医,对于全身乏力和心跳过速等症状有自己的理论解释和治疗方案。
1. 全身乏力:中医认为这是“气虚”或者“阳虚”的表现。气是维持人体生命活动的物质基础,如果气不足,就会出现乏力、疲劳等症状。可能的原因包括饮食不当、劳累过度、久病体弱等。中医会通过调理饮食,增加营养,适当运动,以及服用补气的药物来改善。
2. 心跳过速:中医将其称为“心悸”或“心动过速”,可能与心脏气血不足、心阴亏损或者有某些病理因素如痰饮、瘀血等有关。中医治疗会根据具体病因采用益气养阴、化痰活血的方法,有时还会使用中药如炙甘草汤、归脾汤等。
然而,值得注意的是,虽然中医理论能够解释和在一定程度上处理这些症状,但在现代医学中,全身乏力伴随心跳过速也可能是心脏疾病(如心律失常)或其他疾病的症状。如果患者持续出现这些症状,应尽快就医,由专业医生进行诊断和治疗。
两者相差 20 秒,并且两次调用均未使用系统 GPU 资源进行推理。
使用一般 chat 版本在仅使用 CPU 算力的情况下比 gguf 版本响应速度更快?这貌似不太合理,但无论怎么样 69 秒还是有点慢了。到这一步可能有人会说,你穷就不要要求那么高了,本来人工智能就是要花钱的,有钱你上个外置显卡不就可以快了吗。
2. 基于 transformers 实现
难道只能这样结束了吗?No!
到目前为止能够确定的是:
- Metal 只支持 M系列芯片与 Intel 无缘
- 受限于硬件性能大参数模型无法在短时间内响应
为了满足以上条件,我这里选用 Qwen/Qwen1.5-0.5B-Chat 模型直接通过 transformers 进行部署,如下图:
...
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
pt_device = torch.device("cpu")
# 模型名称
pt_model_name = "Qwen/Qwen1.5-0.5B-Chat"
# 使用 pytorch 方式加载模型
pt_model = AutoModelForCausalLM.from_pretrained(
pt_model_name,
torch_dtype="auto",
device_map="auto"
)
# 加载分词器
pt_tokenizer = AutoTokenizer.from_pretrained(pt_model_name)
# 给模型一个人设定位
sys_content = "You are a helpful assistant and also a senior expert in the traditional Chinese medicine industry. You are very willing to provide me with detailed opinions to help me grow."
"""
为PyTorch模型生成输入。
此函数以消息列表和批处理大小为输入。它使用pt_tokenizer将聊天模板应用于消息,禁用标记化并添加生成提示。然后使用pt_tokenizer对生成的文本进行标记化,并将其填充到指定的批处理大小。标记化的输入随后被转换为PyTorch张量并移动到pt_device。
Parameters:
messages (List[Dict[str, str]]): 表示对话历史的字典列表。每个字典应该有键“角色”和“内容”。
batch_size (int): 输入所需的批量大小。
Returns:
torch.Tensor: PyTorch模型的输入张量,形状为(批量大小,序列长度)。
"""
def pt_model_input(messages):
text = pt_tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
return pt_tokenizer([text], return_tensors="pt").to(pt_device)
"""
将给定的消息转换为PyTorch模型输入,并使用该模型生成文本。
Parameters:
messages (List[Dict[str, str]]): 表示对话历史的字典列表。每个字典应该有键“角色”和“内容”。
batch_size (int, optional): 输入所需的批量大小。默认为4。
Returns:
str: 从 PyTorch 模型生成的文本。
Note:
- 此函数使用pt_tokenizer将聊天模板应用于消息,禁用标记化并添加生成提示。
- 然后使用pt_tokenizer对得到的文本进行标记,并填充到指定的批量大小。
- 将标记化的输入转换为PyTorch张量并移动到pt_device。
- PyTorch模型根据输入生成文本。
- 生成的文本使用pt_tokenizer进行解码,并跳过特殊标记。
- 仅返回第一个生成的文本。
"""
def pt_transfor_msg(messages):
start_time = time.time()
response_text = ''
try:
model_inputs = pt_model_input(messages)
generated_ids = pt_model.generate(model_inputs.input_ids,max_new_tokens=1024)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response_text = pt_tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
except Exception as e:
print(f"Error: {
e}")
finally:
execution_time = time.time() - start_time
print(f">>> function pt_transfor_msg totally use {
execution_time} seconds")
return response_text
# 预执行一次去加载模型到内存
_ = pt_transfor_msg([{
"role": "user", "content": "Hello"}])
"""
根据给定的提示,使用PyTorch和Qwen模型生成响应。
Parameters:
prompt (str): 生成响应的用户输入提示。
Returns:
str: 生成的响应文本。
Note:
- 此函数使用pt_tokenizer将聊天模板应用于消息,禁用标记化并添加生成提示。
- 然后使用pt_tokenizer对得到的文本进行标记,并填充到指定的批量大小。
- 将标记化的输入转换为PyTorch张量并移动到pt_device。
- PyTorch模型根据输入生成文本。
- 生成的文本使用pt_tokenizer进行解码,并跳过特殊标记。
- 仅返回第一个生成的文本。
"""
def pt_qwen_text(prompt):
messages = [
{
"role": "system", "content": sys_content},
{
"role": "user", "content": prompt}
]
return pt_transfor_msg(messages)
if __name__ == '__main__':
prompt = "中医药理论是否能解释并解决全身乏力伴随心跳过速的症状?"
response = pt_qwen_text(prompt)
print(">>> "+response)
这段代码跟之前的代码没有太大的区别,还是用一般的 chat 模型,但是为了加快响应速度,这里预先做了一次“提问”预热。
_ = pt_transfor_msg([{
"role": "user", "content": "Hello"}])
通过提问将模型加载到内存里面,之后再进行问题提问就会稍微快一些,如下图:
(transformer) (base) MacBook-Pro:python yuanzhenhui$ /Users/yuanzhenhui/anaconda3/envs/transformer/bin/python /Users/yuanzhenhui/Documents/code_space/git/processing/python/tcm_assistant/learning/local_model.py
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
>>> function pt_transfor_msg totally use 30.924490928649902 seconds
>>> 中医药理论中的一些概念,如阴阳五行、脏腑经络等,可能在理解这些症状的根源上有一定的帮助。但是,具体的病因和治疗方案需要通过中医医生的专业判断来确定。
一般来说,全身乏力伴心跳过速可能是由于多种原因引起的,包括心肌梗死、心脏疾病、高血压、心脏病发作等。因此,中医理论不能简单地应用到所有的病症上,只能提供一些基本的诊断和治疗方法。
如果想要找出具体的病因,可以考虑通过检查血液中的糖水平、血压、血脂等指标,或者通过专业的医疗影像学检查,如心电图、X光片等。如果诊断结果显示没有心脏问题,那么可能是由其他原因引起的心力衰竭或糖尿病等慢性病所导致。
总的来说,虽然中医理论在一定程度上可能有助于理解一些疾病的发病机制,但并不是所有的问题都可以用中医方法解决。同时,中医治疗通常需要个体化的调整,不能代替药物治疗。
耗时 30 秒,通过缩减模型参数的方式将响应时间缩减到原来的一半。这种方式直接用于文本生成(text-generation)还是有点勉强的,但是如果只是用来做语意分析的话因为问题不大。
此外,有尝试过使用 ctransformers 来部署 gguf 模型,结果发现并不是所有的 gguf 模型都能够正常地部署。由于一直没有尝试到想要的结果因此先暂时放弃。
基于 OpenVINO 实现
OpenVINO 是一个开源工具包,用于优化和部署从云端到边缘的深度学习模型。开源公司是 Intel…是的,没有看错就是 Intel。详细的介绍如下我就不多说了:
OpenVINO 2024.1 — OpenVINO™ documentation
OpenVINO(以下简称“vino”)不能直接使用 transformers 实现,在 huggingface 中我们可以直接在 Libraries 分类中选择“OpenVINO”来筛选出别人已经编译好的模型,但是中文模型实在太少了(只有一个)。接下来给我们的就只有两条路,一个是通过 save_pretrained 先将模型下载到本地,然后再通过 OpenVINO Toolkit 进行转换:
https://www.intel.cn/content/www/cn/zh/developer/tools/openvino-toolkit/overview.html
但这样过于麻烦了,折腾到现在我只想将整个实现达到可容忍的范围内就可以了。于是我选择了另一种方案,采用 Optimum Intel 插件来调用 OpenVINO Runtime 运行推理。
先安装 optimum 插件,如下图:
(transformer) (base) MacBook-Pro:python yuanzhenhui$ pip install optimum[openvino]
Requirement already satisfied: optimum[openvino] in /Users/yuanzhenhui/anaconda3/envs/transformer/lib/python3.11/site-packages (1.19.1)
...
Installing collected packages: ninja, jstyleson, grapheme, wrapt, threadpoolctl, tabulate, rpds-py, pyparsing, pygments, openvino, natsort, mdurl, kiwisolver, future, fonttools, cycler, contourpy, cma, about-time, tiktoken, scikit-learn, referencing, pydot, openvino-tokenizers, matplotlib, markdown-it-py, Deprecated, autograd, alive-progress, rich, pymoo, jsonschema-specifications, jsonschema, nncf
Attempting uninstall: openvino
Found existing installation: openvino 2023.3.0
Uninstalling openvino-2023.3.0:
Successfully uninstalled openvino-2023.3.0
Successfully installed Deprecated-1.2.14 about-time-4.2.1 alive-progress-3.1.5 autograd-1.6.2 cma-3.2.2 contourpy-1.2.1 cycler-0.12.1 fonttools-4.51.0 future-1.0.0 grapheme-0.6.0 jsonschema-4.22.0 jsonschema-specifications-2023.12.1 jstyleson-0.0.2 kiwisolver-1.4.5 markdown-it-py-3.0.0 matplotlib-3.8.4 mdurl-0.1.2 natsort-8.4.0 ninja-1.11.1.1 nncf-2.10.0 openvino-2024.1.0 openvino-tokenizers-2024.1.0.0 pydot-2.0.0 pygments-2.18.0 pymoo-0.6.1.1 pyparsing-3.1.2 referencing-0.35.1 rich-13.7.1 rpds-py-0.18.1 scikit-learn-1.4.2 tabulate-0.9.0 threadpoolctl-3.5.0 tiktoken-0.6.0 wrapt-1.16.0
由于在其他尝试的时候已经将部分依赖安装了,所以整个 optimum 安装非常的快。接下来就可以编写调用代码了,如下图:
import time
import torch
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4815
4815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











