






1.简介(ShuffleNetv2原论文一定要看!!!)
这篇文章强烈建议大家自己看一遍,里面有很详细的实验,还有作者提出的高效网络准则等等,非常好的一篇文章。
ShuffleNetv2主要从模型的复杂度不能只看FLOPs,参数量的大小并不能完全反映推理速度的快慢讲起,然后提出了四条设计高效网络的准则,进而提出新的block设计ShuffleNetv2 block。
2.ShuffleNetv2
2.1 影响推理速度的众多因素
1)FLOPs
2)MAC(memory access cost)内存访问成本
3)degree of parallelism并行等级
4)platform。在不同的平台上运行,影响推理速度的因素效果还不一样,比如在GPU中Conv占一半,而在CPU中占了八十多。
5)其他。Although this part consumes most time,the other operations including dataI/O, data shuffle and element-wise operations (AddTensor,ReLU, etc) also oc-cupy considerable amount of time. Therefore, FLOPs is not an accurate enough estimation of actual runtime.
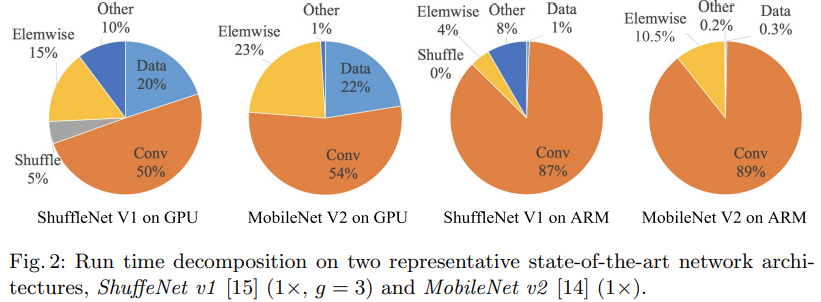
2.2 四条高效网络准则
2.2.1 G1: Equal channel width minimizes memory access cost (MAC)
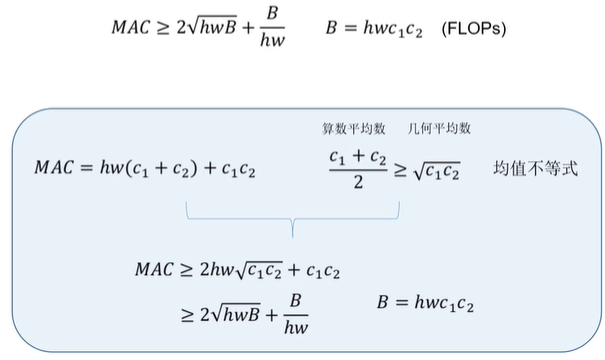
当卷积层的输入特征矩阵与输出特征矩阵channel相等时MAC最小(保持FLOPs不变时)
MAC包括feature map的内存加载hwc1、输出feature map的内存加载hwc2和卷积核的内存加载(这里特指1x1卷积)c1c2。
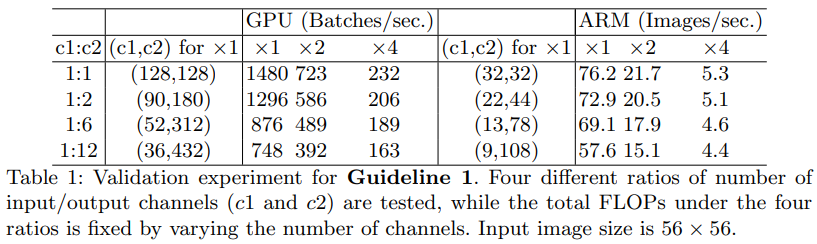
作者也做了一些实验来验证,作者堆叠了一些block,每个block包含两个卷积层,第一个卷积层in_channel=c1,out_channel=c2,第二个卷积层相反in_channel=c2,out_channel=c1,在FLOPs相同的情况下来测试哪一个比例的block推理速度更快。从下图可以看出,比重相差越大,推理速度越慢,并且在不同平台的效果也是不一样的。
2.2.2 G2: Excessive group convolution increases MAC
当GConv的groups增大时(保持FLOPs不变时),MAC也会增大
这结论诱导性太强了:应该改成“当g和c2成比例增大时,mac会增大”,所以归根结底不是因为groups增加了,而是因为c2即output维度增大而导致mac增加!
也就是说,输入feature map的h、w和c1是不变的,所以B(FLOPs)不变时,c2/g也是不变的。那么只有当group增大,同时c2增大时,MAC才会增大。
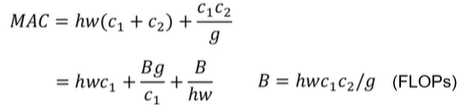
作者也对此进行了实验,实验结果显示,当group和c增大时,推理速度明显变慢。
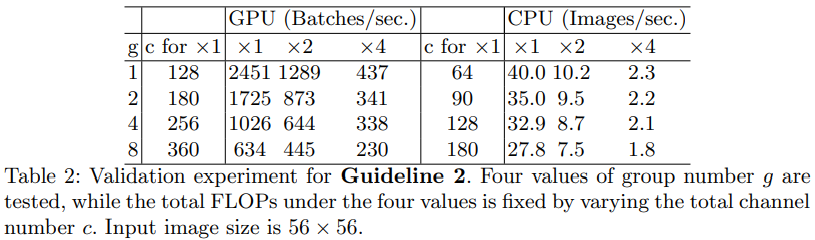
2.2.3 G3: Network fragmentation reduces degree of parallelism
网络设计的碎片化程度越高,速度越慢
我们之前也学习过很多网络,很多都喜欢加入分支或者加大网络的深度等等来提高网络的精度,但是这也同时降低了模型的效率。而且多分支还会包括kernel的启动和同步的时间消耗。
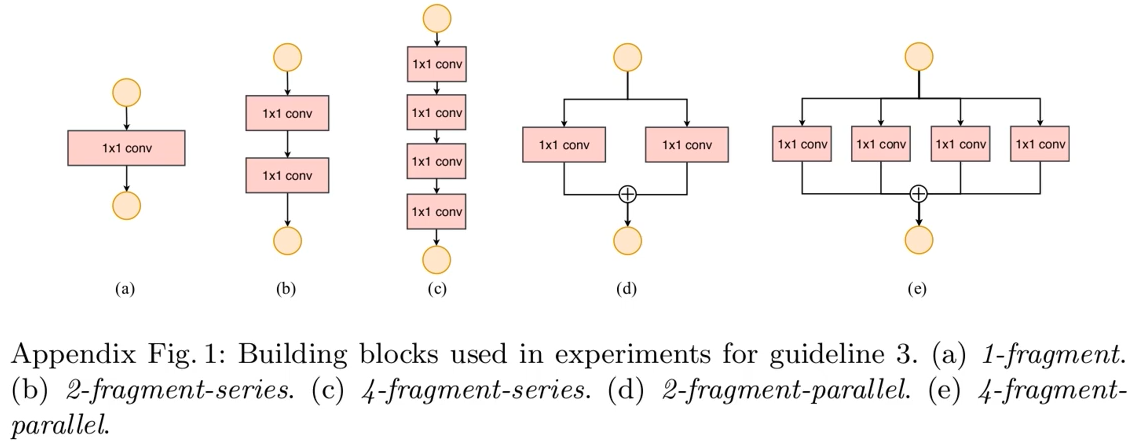
作者也进行了实验,表中对应的五行就对应着上图的五个网络结构。可以看到碎片化程度越高,模型推理速度越慢,而且在GPU和CPU上的表现有差异。
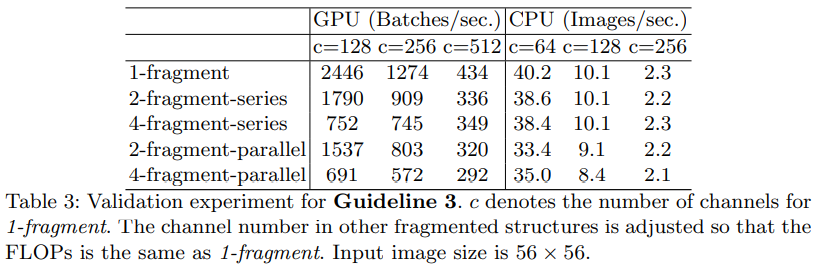
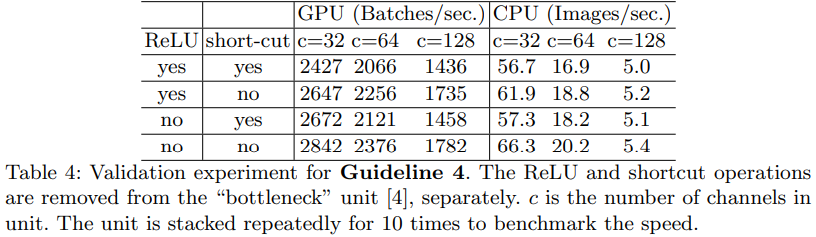
2.2.4 G4: Element-wise operations are non-negligible
Element-wise操作带来的影响是不可忽视的
element-wise operations (包括AddTensor,ReLU, AddBias,etc)
作者也进行了实验,实验结果显示,当FLOPs相同时,element-wise所带来的影响也是非常大的。
2.3 ShuffleNetv2 block
ShuffleNetv2 block是遵循上面的四条准则设计出来的。a、b图是ShuffleNetv1当中的block,c、d图是ShuffleNetv2 block,d图为stride=2时的block。

ShuffleNetv2 block相较于ShuffleNetv1 block有几点不同。
1)将输入feature map先通过一个channel split模块,将feature map从通道维度分成两份。
2)右边分支的三个卷积的输入输出channel相同(满足G1)
3)将1x1的组卷积还原成普通卷积(满足G2)
4)两个分支通过Concat融合(满足G1)
5)将channel shuffle移到了concat后面
6)不使用Add、将concat、shuffle和下一层的split合在一起,都满足了G4
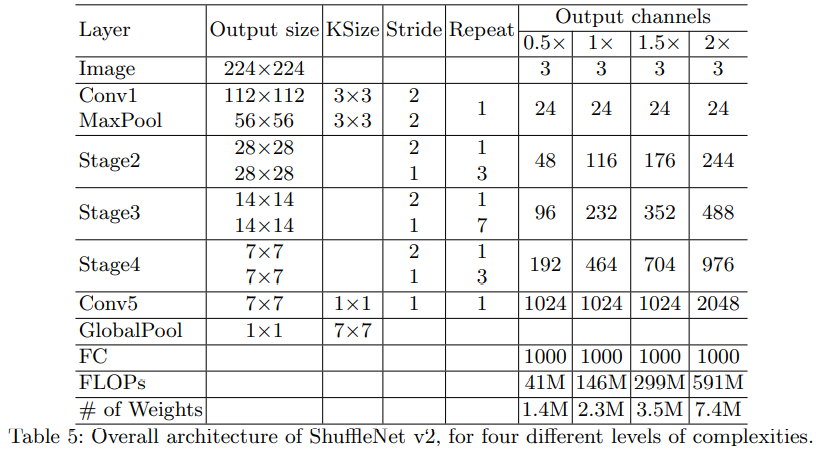
2.4 ShuffleNetv2整体结构
相比于ShuffleNetv1多了一个Conv5。
注意:而且对于stage2的第一个block,它的两个分支中输出的channel并不等于输入的channel,而是直接设置为指定输出channel的一半,比如对于1x版本每分支的channel应该是58,不是24.
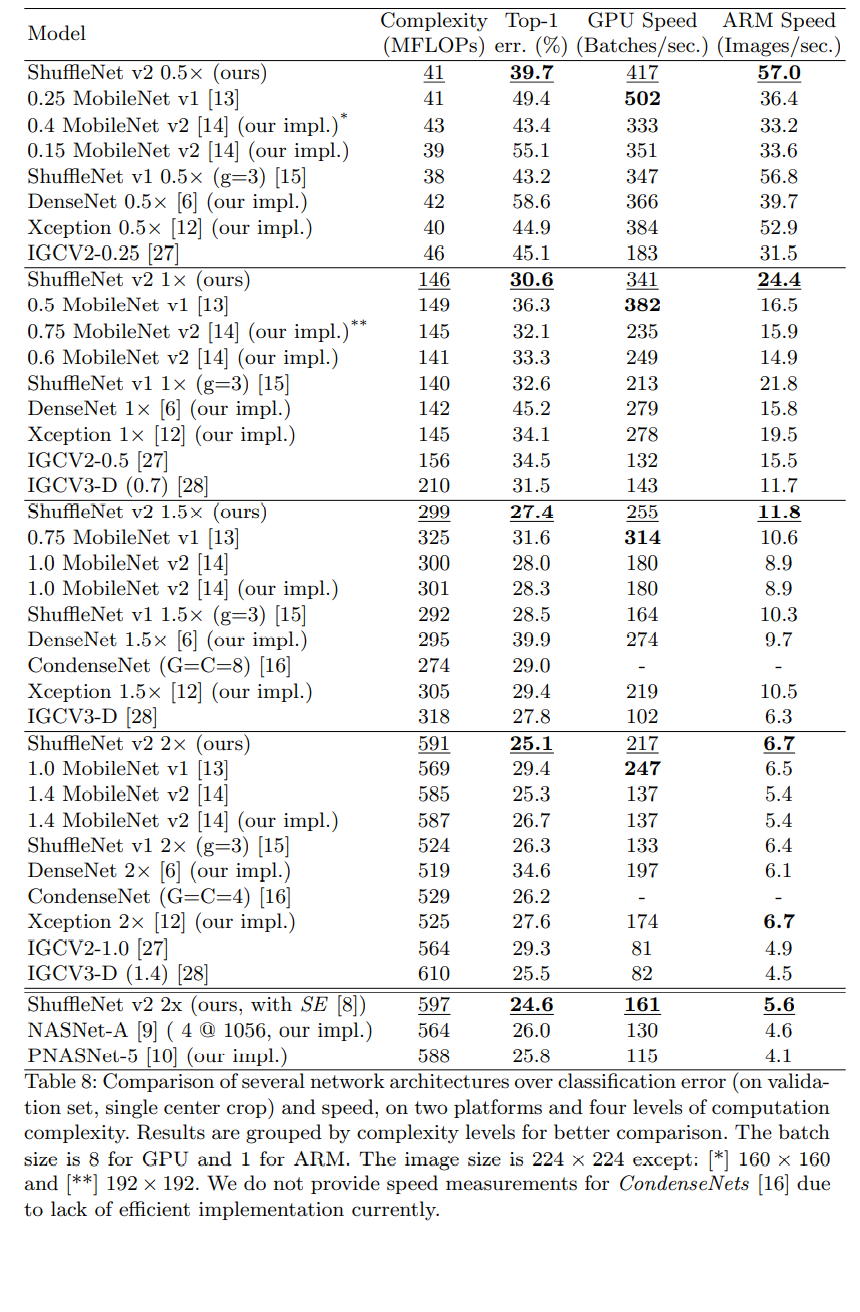
2.5 ShuffleNetv2性能指标
3.ShuffleNetv2模型代码
整个ShuffleNetv2模型的代码其实并不难,这里我就说一下几个要点。
第一,shuffle模块的实现方式其实就是先将feature map的channel维度拆成group,channel_per_group两部分,然后再通过Transpose的方式将group,channel_per_group变为channel_per_group,group,这样就实现了channel shuffle。比如,特征图维度为[B, C, H, W]-->[16, 100, 56, 56],当group=2时通过view函数变为[16, 2, 50, 56, 56],在通过Transpose变为[16, 50, 2, 56, 56],再还原为[16, 100, 56, 56],这就完成了channel shuffle。可以想象为,把100个东西分为了两份,每份50个,然后将两组中相同位置的拿出来放在一起,这样就形成了50份,每份2个,这就完成了shuffle。
第二就是,每个stage都是在第一个卷积处进行升维操作,其他的卷积层输入输出channel相同。
第三,split操作是通过chunk函数实现的,在channel维度拆成两份。
最后,有不懂得部分欢迎评论或私信我,希望这篇文章对你有帮助!
from typing import List, Callable
import torch
from torch import Tensor
import torch.nn as nn
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
# split操作,这里通过chunk函数实现,在dim=1(channel维度)将feature map分为两部分
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model














 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









