






阿里巴巴近日正式发布新一代通义千问 Qwen3 系列,凭借强悍性能跃居全球开源大模型阵营前列。
这是一款革命性的“混合推理模型”,将高效“快思考”与严谨“慢思考”合二为一,大幅优化模型表现与计算资源利用。
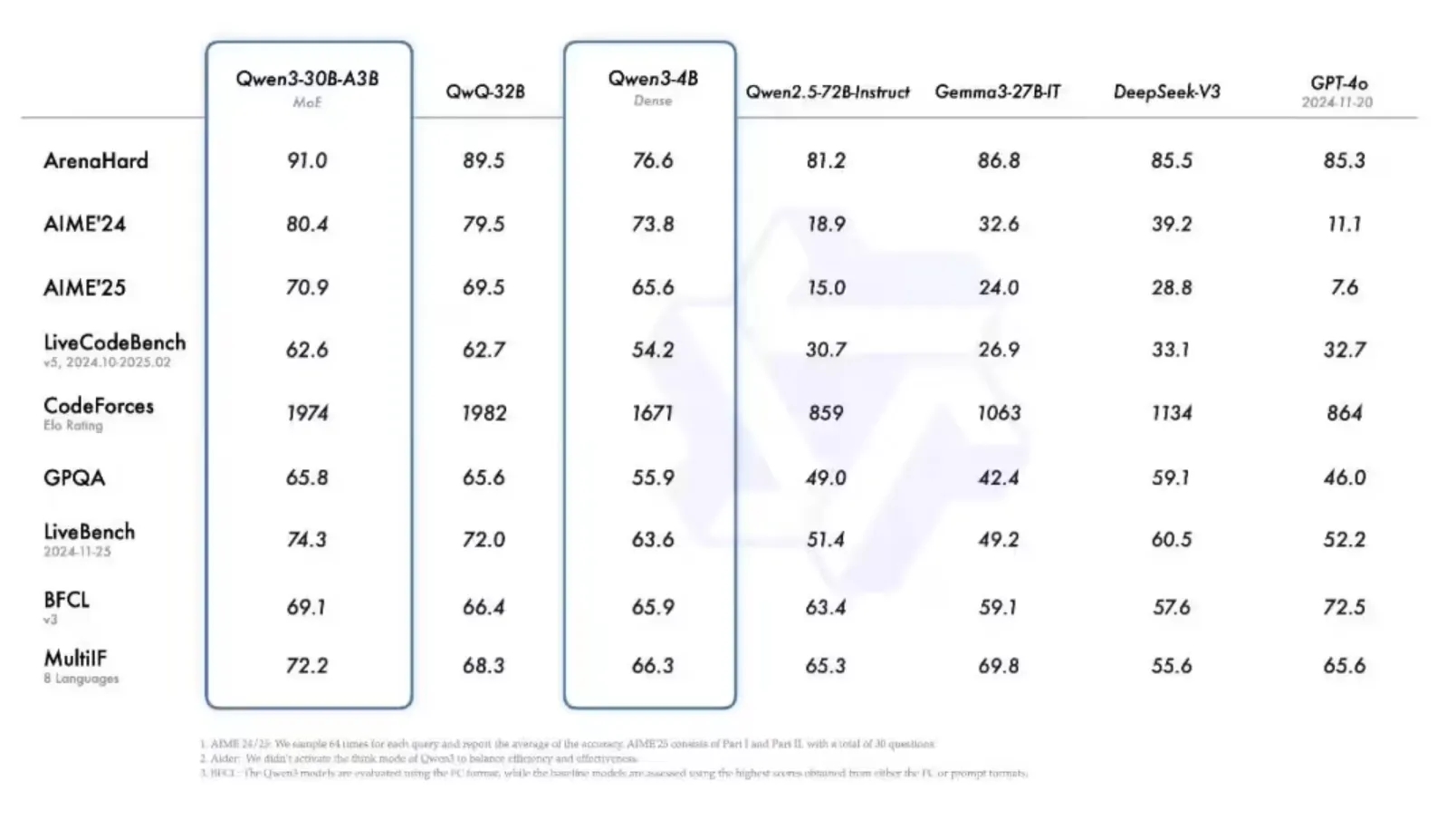
Qwen3-235B-A22B 在多个关键指标如代码生成、数学推理、通用智能等维度,超越 DeepSeek-R1、Grok-3、Gemini-2.5-Pro 等一线模型,实力瞩目。
核心模式特色包括:
-
慢思考: 针对复杂问题展开多层逻辑推演,提升答案的精准性与逻辑连贯性。
-
快思考: 快速响应已知问题,满足用户对高效反馈的即时需求。
通过按需调配两种推理深度,Qwen3 支持灵活的“思维资源”分配机制,在算力与结果质量之间实现最佳平衡。

















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









