









系列文章目录
上一节:从零开始的RISCV架构CPU设计(2)-CISC与RISC
文章目录
前言
流水线与状态机是数字电路设计中两种重要的技术,本节将由浅入深对这两种技术作简要介绍,并探讨在该RV CPU软核的实现框架。
一、举个例子
在进行对流水线与状态机的介绍之前,首先为大家引入一个生活实例:
王大妈与李大妈现打算各自开设一家餐饮店,她们俩分别采用了不同的经营模式。
王大妈开设的餐饮店不招收员工,店内所有工作需要王大妈一个人负责完成,这些工作包括接单、需求分析、后厨制作、餐饮配送;假设这些工作每项需要十分钟,我们不难得出,王大妈一个处理订单的速度为这些工作时间的总和共计40分钟;并且假设王大妈在进行其中一项工作时无法同时进行其他工作,因此王大妈只有在处理完当前订单后才能对下一个订单做处理;我们对王大妈的这种模式画一个时间轴,如下所示: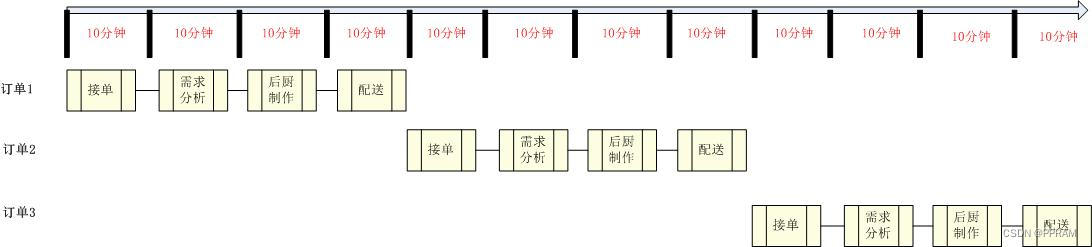 王大妈处理三个订单花费了120分钟,我们可以看出,这种运营方式处理订单的效率并不高。
王大妈处理三个订单花费了120分钟,我们可以看出,这种运营方式处理订单的效率并不高。
我们再来看李大妈,李大妈选择招收一个前台柜员、一个服务员、一个厨师、一个骑手来分别负责接单、需求分析、后厨制作、餐饮配送。在这种情况下,前台柜员将接收到的订单给服务员后,便可以接收下一份订单,同理服务员在
对订单进行分析后,将顾客的需求反应给厨师后,就可以转去处理柜员传递的下一份订单,以此类推,这种工作模式的时间轴如下所示:
 从整体上来看,整个餐厅在处理上一份订单的需求时,可以进行下一份订单的接单任务,在处理上一份订单的后厨制作时,可以进行下一份订单的需求分析;同理在上一份订单配送时,下一份订单处于后厨制作阶段;
从整体上来看,整个餐厅在处理上一份订单的需求时,可以进行下一份订单的接单任务,在处理上一份订单的后厨制作时,可以进行下一份订单的需求分析;同理在上一份订单配送时,下一份订单处于后厨制作阶段;
李大妈的这种模式,虽然单个订单的处理时间仍然是40分钟,但整体上来看,三个订单的处理时间仅花费了60分钟。
我们再来综合看下这两种经营模式,王大妈的经营模式简单来说就是划分好了每个时刻的任务,第一个10分钟干什么,第二个十分钟干什么;李大妈人多力量大,所有工作在每个十分钟都可以同时进行。其实前者的工作模式就是一种状态机,后者就是流水线;
两种模式各有优缺点,王大妈虽然减少了店内员工的开销,但是处理订单的效率不高,适合订单不多的情况;李大妈虽然处理订单的效率提高了,但其在员工上的开销也增大了,适合订单较多的情况;
二、状态机
2.1 状态机概念
正如上述我们举的实例,状态机所做的就是将一个复杂的任务分为若干个阶段,每个阶段去完成其中的一小部分。由于状态机在每个时钟周期到来时处理的任务是唯一的,做事是“一心一意”的,所以各个状态对应逻辑是允许逻辑复用的,所以状态机是一种以性能换面积的手段;
2.2 状态机设计
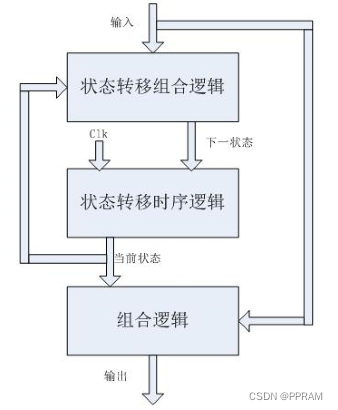
从状态机的类型上来看,状态机可以分为moore型和mealy型;
从状态机的代码实现上来看,状态机可以是一段式、二段式或三段式;
moore型状态机的特点是状态机的输入与输出无关,输出仅与当前状态有关,如下图所示:
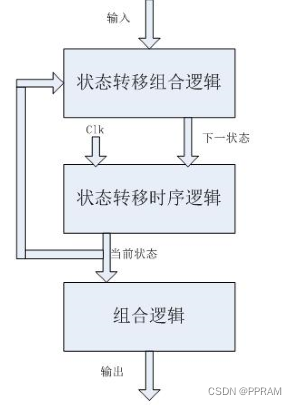
mealy型状态机的特点是状态机的输入会影响输出;
2.3 设计实例
我们这边举一个二段式状态机的设计实例;计算y=12*x + (x - 6) + x / 4;
module state_machine_test(
input wire clk,
input wire nrst,
input wire [15:0] x,
output wire [31:0] y
);
reg [31:0] y_temp;
reg [31:0] y_buff;
reg [1:0] state;
localparam integer MUL0 = 0;
localparam integer SUB0 = 1;
localparam integer DIV0 = 2;
assign y = y_buff;
always@(posedge clk)
begin
if(~nrst)
state <= MUL0;
else
begin
case(state)
MUL0: state <= SUB0;
SUB0: state <= DIV0;
DIV0: state <= MUL0;
default: state <= MUL0;
endcase
end
end
always@(posedge clk)
begin
if(~nrst)
begin
y_temp <= 'b0;
y_buff <= 'b0;
end
else
begin
case(state)
MUL0: y_temp <= y_temp + 12*x;
SUB0: y_temp <= y_temp + x - 6;
DIV0:begin
y_temp <= 'b0;
y_buff <= y_temp + (x >> 2);
end
default:begin y_temp <= 'b0;y_buff<= 'b0;end
endcase
end
end
endmodule
第一个always块负责状态的转换,第二个always块负责计算。在第一个clk,状态机计算第一个乘法,第二个clk时,状态机计算减法,第三clk状态机计算除法;这三个阶段逻辑是可以共用的。
三、流水线
3.1 流水线概念
正如上述我们举的实例,流水线就是将一个复杂任务分割为若干部分,每个部分由一个模块去负责,各个模块在统一的时钟步调下工作,每来一个时钟,流水线就向前推进一次;
如我们需要实现下面一个大逻辑Logic,运用流水线设计方法,我们就先需要将其分割为各个小逻辑。logic0、logic1,然后各个logic之间插入一个触发器用于信号的传递;

按照流水线,Logci的实现如下图:
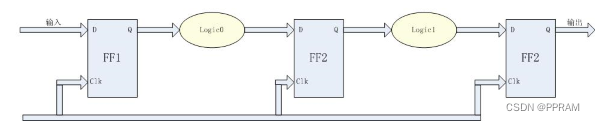
3.2 设计实例
同样以2.3小节的场景,我们来看看状态机是如何设计的:
module pipeline_test(
input wire clk,
input wire nrst,
input wire [15:0] x,
output wire [31:0] y
);
reg [31:0] y0;
reg [31:0] y1;
reg [31:0] y2;
reg [15:0] x0;
reg [15:0] x1;
reg [15:0] x2;
assign y = y2;
always@(posedge clk)
begin
if(~nrst)
begin
y0 <= 'b0;
x0 <= 'b0;
end
else
begin
y0 <= x * 12;
x0 <= x;
end
end
always@(posedge clk)
begin
if(~nrst)
begin
y1 <= 'b0;
x1 <= 'b0;
end
else
begin
y1 <= y0 + x0 - 6;
x1 <= x0;
end
end
always@(posedge clk)
begin
if(~nrst)
begin
y2 <= 'b0;
x2 <= 'b0;
end
else
begin
y2 <= y1 + (x1 >> 2);
x2 <= x1;
end
end
endmodule
3.3 与状态机对比
很显然,流水线设计中,每一级的逻辑都是不能复用的,相较于状态机,流水线消耗的资源较多,且随着流水线级数的增加越来越多;由此看来,流水线的深度必须合理规划,不是一味的深度越深越好。
博主层实现过16级流水线的Cordic算法,16级流水线消耗的FPGA资源可达一半;
但相较状态机,流水线确实增加了数据的吞吐率,也能增加clk的时钟频率,这是由于流水线将一个复杂的组合逻辑拆分成了若干个小逻辑,因此时钟经过组合逻辑所产生的时钟偏移和时钟抖动都会得到很好的改善,每部分小逻辑的输入输出延迟相较于大逻辑来说,也会大大降低(信号路径变短)。
但流水线在划分模块,各模块存在相关性的时候会产生一些麻烦,而状态机是严格控制每一时刻的处理逻辑的,因此不会产生这些问题。流水线涉及的问题将会在CPU的流水线设计中讲到。
综上所述,状态机是以时间换面积的手段,流水线是以面积换时间的手段,应当根据不同的需求来使用。
四、CPU设计框架
在上一章我们确定了CPU的指令集架构-RISCV。这一章我们来确定CPU的具体实现框架;
4.1 指令的执行
我们先来探讨一下实现一个CPU需要哪些部件,或者说一条指令的执行需要通过哪些步骤;
首先我们需要去到存储指令的ROM中取出我们需要执行的指令,这一阶段称为取指;
其次我们需要分析这条指令,这一阶段称为译码;
然后我们需要根据译码后的结果来进行相应的操作,这一阶段称为执行;
然后我们需要进行存储器的访问(存取数据),这一阶段称为访存;
最后我们需要将指令执行的结果写入通用寄存器,这一阶段称为写回;
所以一条指令的执行过程为 取指->译码->执行->访存->写回。
4.2 单周期CPU
单周期CPU即在一个指令周期内仅执行一条指令(如第一节中的王大妈店)。其具体实现便是依靠状态机。
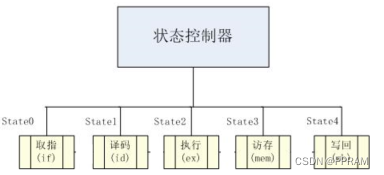
如上图所示,状态控制器由时钟信号驱动,产生当前时刻的状态state,来控制组合逻辑完成各个操作;
由于状态控制器的状态扫描是从state0~state4的,所以每5个clk才能回到state0去取下一条指令,所以每个指令周期执行的指令只有一条。
 我们可以看到,这种情况下执行两条指令总共需要10个clk时钟周期;
我们可以看到,这种情况下执行两条指令总共需要10个clk时钟周期;
4.2 多周期CPU
多周期CPU即在一个指令周期内同时处理多条指令(如第一节中的李大妈店)。其具体实现便是依靠流水线。
使用流水线进行指令处理,其执行情况如下: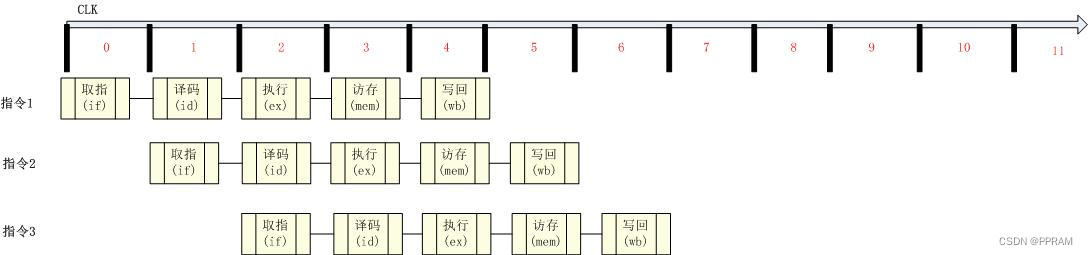 指令是按照指令流的方式处理,同一时刻允许多条指令同时处理。这样大大提高了指令的处理效率;我们可以看到,执行两条指令总共的时钟周期为6个CLK,单从消耗的时钟周期上来看,效率提高了百分之40多,实际情况下,流水线能带来更多的效益,效率提升应远大于理想情况下的40%。
指令是按照指令流的方式处理,同一时刻允许多条指令同时处理。这样大大提高了指令的处理效率;我们可以看到,执行两条指令总共的时钟周期为6个CLK,单从消耗的时钟周期上来看,效率提高了百分之40多,实际情况下,流水线能带来更多的效益,效率提升应远大于理想情况下的40%。
4.3 流水线冒险
如3.3小节所讲,流水线会带来一些逻辑上的问题,由于指令的执行过程中,指令之间往往存在相关性,如前一个指令的目的操作数是下一条指令的源操作数,诸如此类的相关性会引入各种问题,统称为流水线冒险;
4.3.1 结构冒险
结构冒险主要由硬件的控制产生,如在同一时刻需要对Memory进行写入和读出操作,而Memory读写共用了一组端口,此时就存储器的端口控制,产生了冲突。
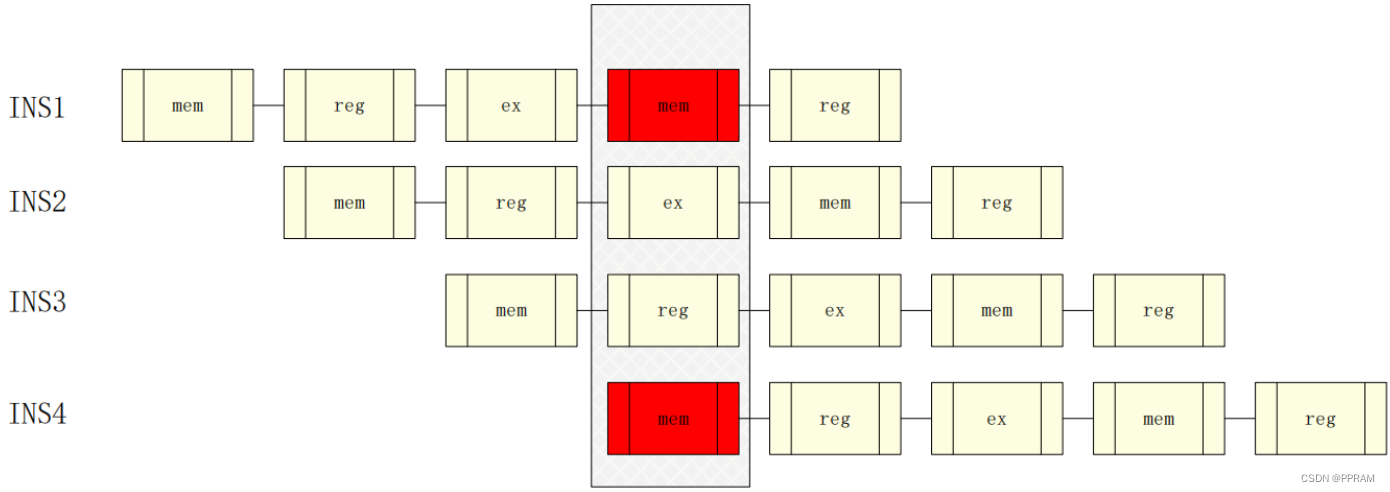 如上图中,第一条指令和第四条指令的mem阶段出现冲突。
如上图中,第一条指令和第四条指令的mem阶段出现冲突。
解决这个问题的方法之一为在发生冲突时,加入一个流水线气泡,这个气泡可以由硬件产生或软件产生。
无论是硬件方案还是软件方案,都会增加一个周期的延迟。
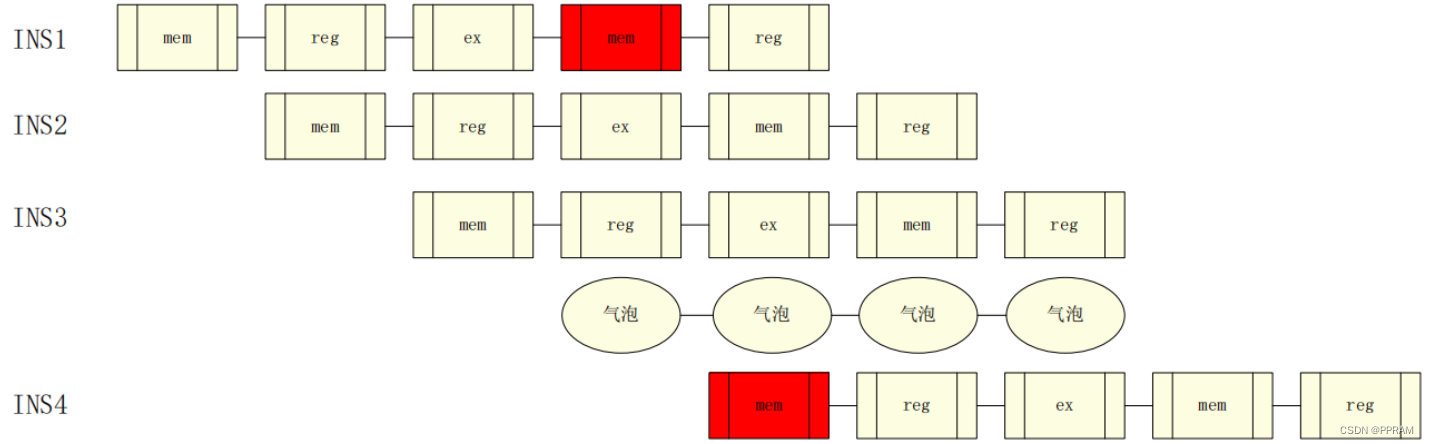 另一种方案则是在if和mem阶段中避免使用同一个存储器。
另一种方案则是在if和mem阶段中避免使用同一个存储器。
在飞V的设计中,将RAM的读写操作统一放到了MEM阶段,同一时刻只允许执行写或读操作,因此不会出现控制冒险。
但这样设计会引入加载指令的数据冒险问题。
4.3.2 数据冒险
• 读后写(RAW):
当第一条指令需要对目的寄存器进行写操作时,第二条指令需要读取上一条指令的目的寄存器作为操作数时,就会发生写后读,寄存器数据还未 更新的情况。
这是由于通用寄存器的写回操作在wb阶段,而读取操作在ex阶段。
下列代码段将用于无法得到正确的结果
0x14: addi rs1,rs1,10; 00000000101000001000000010010011
0x18: addi rs2,rs1,2; 00000000001000001000000100010011
0x22: sub rs3,rs1,rs2; 01000000000100010000000110110011
0x26: slt rs4,rs1,rs3; 00000000000100011010001000110011
对于该问题可以采用数据转移方法来解决。
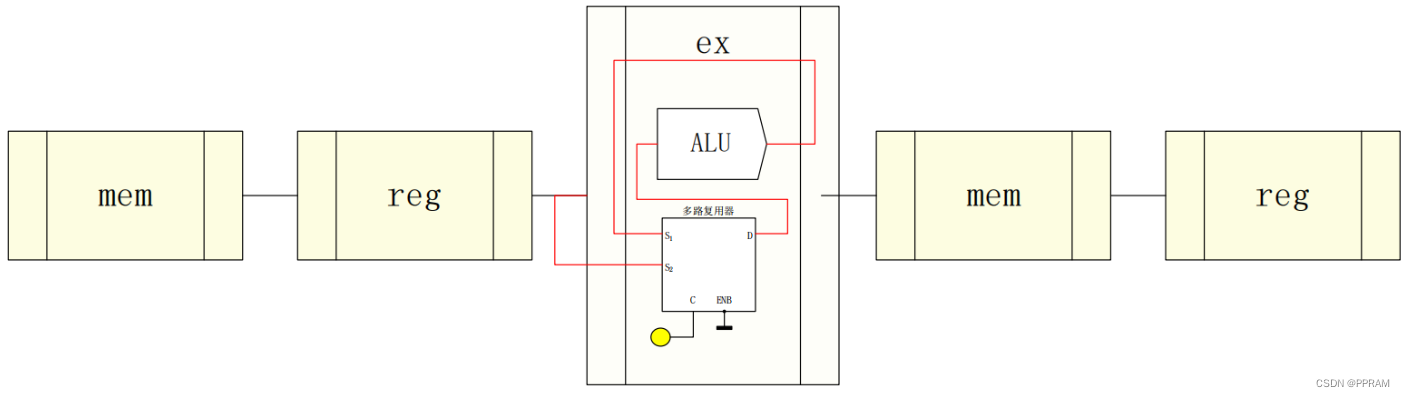 其主要方法是在ex模块中增加一MUX,其选择信号由ex产生,当判断当前操作数存储地址与上一次的目的 操作数寄存器地址相同时,则直接将ALU的输出作为本次运算ALU的输入。
其主要方法是在ex模块中增加一MUX,其选择信号由ex产生,当判断当前操作数存储地址与上一次的目的 操作数寄存器地址相同时,则直接将ALU的输出作为本次运算ALU的输入。
• 写后写(WAW):
两条指令连续写同一个寄存器,但写的次序颠倒。这种情况在飞V的架构中不会出现
• 写后读(WAR):
前一条指令在读出寄存器的值后,下一条指令才写入该寄存器。
如下面代码段:
lw x1,0(x0)
addi x4,x1,x5
第一条加载指令发lw在mem阶段才将在存储器中存储的数据取出,再经过WB写回到寄存器组。
而第二条指令在ex阶段执行。
这也就造成了,addi在执行阶段时,lw在访存阶段。
这种情况下可以引入流水线纵向气泡解决。
纵向气泡的引入可以通过软件或硬件来实现。软件方法可参考RAW,硬件方法则是在addi执行到EX阶段时,将流水线停止一个时钟周期。
在飞V的设计方法中,为了使得程序流获得更高的执行效率,将这种情况的判断提前到了if取指阶段。
在if模块中,采用了双口ROM来对下一条指令进行预测,若本次执行的加载指令的目的寄存器为下次执行指令的源操作数,则将PC暂停一个时钟周期。

4.3 总结
虽然流水线会带来诸多问题,但从总体上来看,流水线对实现处理器的性能带来的收益还是很可观的。所以飞 V 开源软核的设计采用了典型的五级流水线架构。
总结
在本章中主要对流水线和状态机技术进行了说明,最终确定以流水线的方法来实现RISC-V指令集。流水线的引入同样会带来很多问题,本章只对流水线的控制冒险和数据冒险问题进行了介绍,在实际CPU设计的过程中,遇到问题往往比阐述的这些复杂。一些其他技术如流水线冲刷,执行中断时的跳转冲突,指令预测等等,将会在该系列文章的实战部分详细说到。
参考资料:
《硬件架构的艺术》


















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











