







 该博客介绍了如何将PASCALVOC数据集转换为YOLO格式,包括解析XML标注文件,生成YOLO格式的txt文件,以及按比例划分训练集和验证集的txt文件。提供了Python脚本实现这一过程,涉及的主要步骤包括读取xml文件、转换坐标、写入txt文件和创建训练集、验证集列表。
该博客介绍了如何将PASCALVOC数据集转换为YOLO格式,包括解析XML标注文件,生成YOLO格式的txt文件,以及按比例划分训练集和验证集的txt文件。提供了Python脚本实现这一过程,涉及的主要步骤包括读取xml文件、转换坐标、写入txt文件和创建训练集、验证集列表。
一、参考来源
PASCAL VOC 数据集转化为yolo数据集格式_CV-deeplearning的博客-CSDN博客_voc转yolo
二、背景
数据集主目录
class.txt文件的类别信息

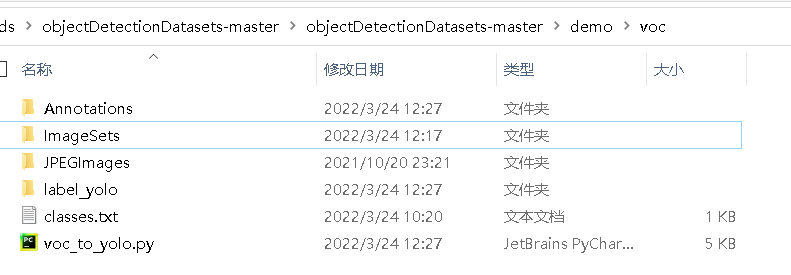
Annotations文件夹下的xml标注文件
图片文件目录
三、转换用到的py文件代码
# coding:utf-8
"""
自动化脚本使用指南:
1.创建和重命名文件夹
将本py文件放在图片数据集主目录内
把图片数据集放在JPEGImages文件夹,xml文件全放在Annotations文件夹
如果没有class.txt文件(每一行代表一个类别),就要手动创建,放在主目录
如果没有Imagesets或label_yolo文件夹,就要手动创建
2.执行本py文件
在数据集路径下打开cmd窗口,执行python voc_to_yolo.py
或者在pycharm中选定一个虚拟环境后run起来
3.程序执行的效果
程序会自动转换Annotations文件夹下的xml文件为label_yolo文件夹下的txt文件
程序会自动生成图片链接划分txt文件(train.txt,val.txt,trainval.txt)在Imageset文件夹下
4.其他注意事项
由下面描述路径的方式可知,如果以命令行方式执行,想要修改文件夹名称,可在voc_to_yolo.py后指定相关参数
当然也可以修改py文件,把各个路径参数的default值改成自己的目标值
如果不想按2:8的比例划分数据集,也可以自己在本py文件中的imglist2file函数定义部分修改代码
"""
from __future__ import print_function
import argparse
import os
import random
import glob
import xml.etree.ElementTree as ET
def xml_reader(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
size = tree.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return width, height, objects
def voc2yolo(filename):
classes_dict = {}
with open("classes.txt") as f:
for idx, line in enumerate(f.readlines()):
class_name = line.strip()
classes_dict[class_name] = idx
width, height, objects = xml_reader(filename)
lines = []
for obj in objects:
x, y, x2, y2 = obj['bbox']
class_name = obj['name']
label = classes_dict[class_name]
cx = (x2 + x) * 0.5 / width
cy = (y2 + y) * 0.5 / height
w = (x2 - x) * 1. / width
h = (y2 - y) * 1. / height
line = "%s %.6f %.6f %.6f %.6f\n" % (label, cx, cy, w, h)
lines.append(line)
txt_name = filename.replace(".xml", ".txt").replace("Annotations", "label_yolo")
with open(txt_name, "w") as f:
f.writelines(lines)
def get_image_list(image_dir, suffix=['jpg', 'jpeg', 'JPG', 'JPEG', 'png']):
'''get all image path ends with suffix'''
if not os.path.exists(image_dir):
print("PATH:%s not exists" % image_dir)
return []
imglist = []
for root, sdirs, files in os.walk(image_dir):
if not files:
continue
for filename in files:
filepath = os.path.join(root, filename) + "\n"
if filename.split('.')[-1] in suffix:
imglist.append(filepath)
return imglist
def imglist2file(imglist):
random.shuffle(imglist) # 文件路径打乱
trainval_list = imglist[:] # 取所有图片为训练-测试集(总集合)
train_list = imglist[int(len(imglist)/5):] # 取后80%的图片为训练集
valid_list = imglist[:int(len(imglist)/5)] # 取前20%的图片为测试集
with open(args.Imagesetpath + "//trainval_list.txt", "w") as f:
f.writelines(trainval_list)
with open(args.Imagesetpath + "//train.txt", "w") as f:
f.writelines(train_list)
with open(args.Imagesetpath + "//valid.txt", "w") as f:
f.writelines(valid_list)
if __name__ == "__main__":
# 定义路径
parser = argparse.ArgumentParser()
parser.add_argument('-xml', '--xmlpath', type=str, default="Annotations", help="voc数据集的Annotations文件夹路径")
parser.add_argument('-image', '--Imagepath', type=str, default="JPEGImages", help="voc数据集的图片文件夹路径")
parser.add_argument('-set', '--Imagesetpath', type=str, default="ImageSets", help="voc数据集的图片链接集路径")
args = parser.parse_args()
xml_path_list = glob.glob(args.xmlpath + "/*.xml")
for xml_path in xml_path_list:
voc2yolo(xml_path)
# 获取图片文件夹下的所有图片的filepath
imglist = get_image_list(args.Imagepath)
# 将获取到的filepath写入链接图片以及可划分测试集、训练集的txt文件中
imglist2file(imglist)
















 2509
2509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









