






转载一篇总结写得很不错的博客,原博客Shreya Mattoo发表于2022.7.28
什么是目标检测
前言
视觉的光学迷宫,被技术简化了。
人体物体检测非常快速和精确。我们的大脑被设计来识别元素,作为对我们的视觉系统的反射。
现在是时候准备竞争了。
随着人工智能、物联网和量子计算等新兴技术的兴起,计算机科学家已经能够将我们的思维过程克隆到计算机中。这种现象通常被称为对象检测,它在很大程度上消除了各行各业对人类的依赖。
物体检测也是自动驾驶技术背后的关键概念。许多汽车公司除了将其用于图像识别软件之外,还将其用于为装有人工智能传感器的车辆提供动力,以实现安全行驶、事后检测交通状况、创建3D地图以及在无人驾驶的情况下导航。
目标检测将正常的视力提升到一个新的水平!就像人类的大脑一样,它帮助机器在我们的视觉世界中导航——当然,这需要一点帮助。
什么是目标检测?
物体检测是一种计算机视觉技术,用于在特定环境下识别和分类特定物体。物体检测的主要目标是扫描数字图像或现实场景,以定位每个物体的实例,分离它们,并分析它们的必要特征,以便实时预测。
对象检测是公司整体数据架构的一部分。一些企业已经在与它合作,而另一些企业则在等待有人宣布它是一项成功的突破性创新。
目标检测的主要例子包括安全和监视、访问控制、生物识别考勤、道路状况监测、自助机器和海洋边境保护。
目标检测是如何工作的?
物体检测的工作原理与物体识别类似。唯一的区别是物体识别是识别正确的物体类别的过程,而物体检测只是检测物体在图像中的存在和位置。
目标检测任务可以通过两种不同的数据分析技术方法来执行。
-
图像处理是无监督学习的一部分,它不需要历史训练数据来教授分析模型。模型在输入图像上进行自我训练,并创建特征图来进行预测。图像处理不需要高图形处理能力(GPU)或大型数据集来执行。
-
深度神经网络:深度神经网络通常是一种监督学习算法,需要大数据集和高GPU计算能力来预测对象类别。这是一种更准确的方法,可以对图像中部分隐藏、复杂或置于未知背景中的物体进行分类。
训练深度神经网络是一项劳动密集型和昂贵的任务。然而,有一些大规模的数据集提供了标记数据的可用性。
提示:COCO是一个大规模的对象检测、分割和字幕数据集,可用于训练深度神经网络。
您可以期待MS COCO的一些功能:
- 对象分割
- 语境中的识别
- 超像素物质分割
- 以330K图像进行预训练
- 150万个对象实例
- 80个对象类
- 91种物品类别
- 每张图片有5个字幕
- 25万人有重点
目标检测的重要性
理解了工作方法之后,是时候讨论是什么使得对象检测如此重要。
物体检测为其他重要的AI视觉技术(如图像分类、图像检索或物体协同分割)奠定了基础,这些技术可以从现实生活中的物体中提取有意义的信息。开发人员和工程师正在使用这些技术来建造未来的机器,这些机器将把杂货和药品送到我们家门口!
目标检测算法可以帮助自动检测牛的运动、交通信号和道路车道,以便自动驾驶车辆到达目的地。这反过来又消除了对司机进行后勤跑腿的需求。

来源:geeksforgeeks
不仅如此,通过修剪深层神经网络的层,物体检测也可以在移动网络上运行。它已经被用于机场的安检扫描仪或金属探测器,以检测不需要的和非法的物体。
除此之外,企业还将物体检测用于计数、车牌识别、语音识别和证据检测。然而,有时,精度的轻微不足会妨碍它探测微小物体的效率。由于缺乏百分精度,它在采矿和军事等一些关键领域不太受欢迎。
对象检测方法的类型
执行目标检测的最首选方法是机器学习或深度学习。这两种方法都与支持向量机(SVM)结合使用,以提取特征,训练算法并对对象进行分类。
如果没有适当的数据集,就不可能进行对象检测。数据集涵盖对象的所有主要已知特征,如位置、尺寸、类别或颜色。在实践中,如果一个物体检测模型在一个包含轮子、挡风玻璃、闪光灯、引擎和后备箱的数据集上进行预训练,它可以准确地将给定图像中的物体分类为汽车。
不同类型的目标检测方法在不同行业中具有不同的有效性和适用性。让我们来详细了解一下:
机器学习
使用机器学习算法执行目标检测的优点是,它依赖于手动输入的数据进行分类,而不是自动训练数据。这使得整个算法更不容易出错,更稳定。
目标检测是一个有监督的机器学习问题,这意味着你需要使用预先训练好的模型来触发目标检测器。ML算法的训练数据集中的类列表必须属于特定的图像或图像列表。
像自然语言处理(NLP)这样的机器学习方法根据背景下的照明强度来识别和分类物体。用于2D对象的ML算法也可以用于检测图像中的3D对象。
聚合信道特征(ACF)
ACF是一种机器学习方法,它基于训练图像数据集和对象的地面位置识别图像中的特定对象。ACF主要用于多视角物体检测,比如识别从三个摄像头捕捉到的3D物体。自动辅助车辆、行人检测和人脸检测都是基于这一原理。
ACF结合了不同的通道,从图像中提取渐变或像素的特征,而不是在不同的位置裁剪图像。常见的通道包括灰度或RBG,这取决于目标检测问题的难度。ACF使您对对象有更丰富的了解,并加快检测速度以获得更高的精度。
Tip: To create an ACF object detector, declare and define a MATLAB programming function, “trainACFObjectDetector()” and load the training images. Test the detection accuracy on a separate test image.
DPM对象检测
可变形部件模型(DPM)是一种混合图形模型和图像可变形部件来识别物体的机器学习方法。它包含四个主要部分:
- 粗根过滤器在图像中定义几个边界框来捕获对象。
- 部分过滤器覆盖对象的碎片,并将它们转换为较暗像素的箭头。
- 空间模型存储所有对象片段相对于根过滤器中边界框的位置。
- 利用回归函数减小边界框与地面真实值之间的距离,以准确预测目标。
 来源: lilianweng.github.io
来源: lilianweng.github.io
提示:在从建筑工地收集数据时,提取突出物体的重要特征非常有用,可以跟踪工作进度或执行健康、安全和环境(HSE)规范。
深度学习
虽然机器学习模型是建立在手动选择特征的基础上,但深度学习工作流具有自动选择特征的功能,以适应您的技术堆栈。像卷积神经网络模型这样的深度学习方法可以更快更准确地预测目标。当然,你需要更高的GPU和更大的数据集来实现这一点!
深度学习被用于各种目标检测任务。现代视频监控摄像头或监控系统由神经网络驱动,可以成功检测未知的人脸或物体。下面是一些深度学习方法
You Only Look Once (YOLO)
YOLO是一个单级目标检测框架,专门用于工业应用,具有硬件友好的高效设计和高性能。这是一个CNN,它是在图像网络等大型可视化数据库上训练的,可以在TensorFlow、Darknet或Python的开源编辑器中编码。
YOLO以每秒45帧的闪电般的速度产生最先进的物体检测。到目前为止,已经推出了不同版本的YOLO,如YOLOv1、YOLOv2或YOLOv3。
最新版本YOLOv6可以通过应用程序编程接口(api)在PyTorch中的自定义数据集上进行训练。Pytorch是一个python包,也是深度学习研究中最受欢迎的形式之一。YOLOv6经过专门训练,可以探测道路上的移动车辆。
你知道吗?YOLO或基于区域的卷积神经网络(R-CNN)使用平均平均精度或mAP()函数。它将地面包围框与实际检测到的框进行比较,并返回概率或置信度分数。分数越高,预测越准确。
SSD (Single Shot Detector)
SSD是一种自定义对象检测器,它没有特定的区域建议网络(图像的不同部分聚集在一个网络中)用于对象预测。它通过深度学习模型的一系列层,一次直接预测图像的位置和对象类型。
SSD分为两部分:
Backbone
预训练的图像分类网络骨干从图像中提取特征来识别图像。像ResNet这样的网络是在ImageNets(大型图像数据库)上训练的,并且与内部的图像分类层分离。它将骨干模型作为一个深度神经网络,仅在数百万张图像上进行训练,从输入图像中提取语义信息,同时保留图像的空间结构。
对于ResNet34,骨干为任何输入图像创建256x7x7的特征映射。
Head
目标检测模型的头部只是一个添加到主干上的神经网络大脑层,有助于图像的最终回归过程。它输出对象的空间位置,并在最终SSD阶段将其与对象类结合。

Source:developers.arcgis.com
SSD模型的重要组成
-
网格单元格:与YOLO算法一样,SSD算法将边界框划分为5x5的网格。每个网格单元格负责输出它所包含的对象的形状、位置、颜色和标签。
-
锚框:当CNN将图像划分为一个网格时,网格中的每个单元格都被分配了多个锚框。SSD模型在训练期间采用模板匹配技术,将边界框与图像的每个ground truth对象进行匹配。

Source: pyimagesearch.com
在这里,预测边界框用红色绘制,而地面真相边界框(手工标记)用绿色绘制。由于有高度的重叠,这个锚框负责识别对象的存在。这里的交点除以并集可以被测量为
合集交集(IoU):重叠面积/合集面积
- 纵横比:每个物体都有不同的形状和配置。有些更圆更大,而另一些则缩小更短。SSD体系结构通过一个比率参数帮助预先声明纵横比。
- 缩放级别:缩放参数可以放大每个网格单元中的较小对象,以识别它们的存在、类别和位置。例如,如果我们需要从直升机上识别建筑物和公园,我们需要缩放SSD算法,使其同时检测较大和较小的物体。
- 接受野:接受野被定义为算法当前正在处理的图像的移动像素集。CNN模型的不同层计算输入图像的不同区域。越深入,物体的大小就越大。就像显微镜一样,CNN模型放大物体的每个像素,以计算它属于哪个类别。
EfficientNet
EfficientNet是一种卷积神经网络架构,在检测物体之前统一缩放它们的所有维度。这些神经网络是在应用软件的固定成本下开发的。考虑到资源的可用性,可以跨应用程序域扩展EfficientNet算法,以实现更好的对象检测结果。
EfficientNet被认为是现有的用于对象检测的最好的CNN模型之一,因为它在学习数据集(如Flowers)上达到了最先进的精度(98.8%),同时比其他对象检测模型快6.1倍。
Mask R-CNN
这通过汇集区域提议网络和预先训练的CNN(如AlexNet)来扩展Faster R-CNN。区域提议网络是由边界框分隔的区域网络。Mask R-CNN从图像中提取特征,并创建特征映射来检测物体的存在。它还为每个对象生成一个高质量的蒙版(边界框),以将其与其他对象分开。
Mask R-CNN是如何工作的?
Mask R-CNN使用Faster R-CNN和Fast R-CNN构建。Faster R-CNN有一个softmax层,将输出分为两部分,一个类预测和边界框偏移,Mask R-CNN是添加了第三个分支,描述对象掩码,即对象的形状。它不同于其他类别,需要提取对象的图形坐标来准确预测位置。
掩码R-CNN是两个cnn的组合,通过在对象掩码层中池化工作,也称为与现有边界框平行的感兴趣区域(ROI)
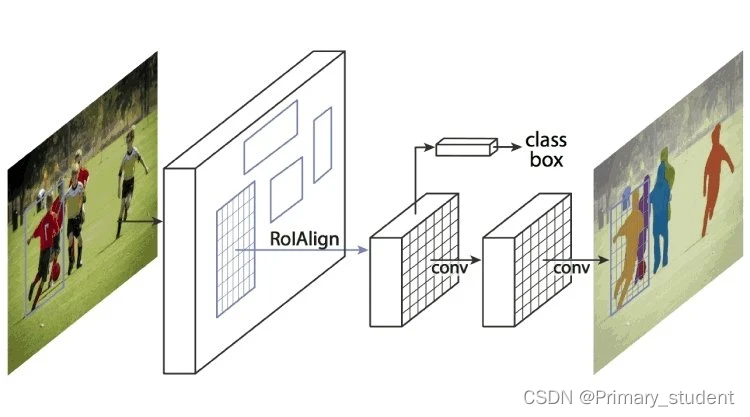
Source: viso.ai
Mask R-CNN的特征
让我们简要地讨论一些特性。
- 这是一个非常简单的模型,以每秒5帧(FPS)的速度训练和运行
- 它在检测不同形态的人脸时效果奇佳。
- 它在每一个目标检测任务上都优于所有单个模型条目。
- 掩码R-CNN可以很容易地推广到其他任务。它还可以用于估计特定框架下的人体姿势。
- 它为创造能够预测我们未来环境的自助机器人提供了坚实的基础。
所有监督对象检测算法都依赖于标记的数据集,这意味着人类必须应用他们的知识来训练不同输入的神经网络。数据集中有标签的对象可以通过label_maps()函数获取,以推断正确的对象类别。
什么是标签映射?
Tensorflow编程中的label-map()将输出数字映射到对象类。如果一个对象检测算法的输出是4,这个函数扫描训练数据,返回数字“4”对应的类。如果输入“4”为“plane”,则输出文本为“plane”。
图像分类与目标检测
目标检测经常与图像分类相混淆。虽然这些是同一个魔方的侧面,但这里有一些显著的区别。

图像分类是一个简单的概念,即根据多光谱图像的组成部分对其进行分类。如果给你一张狗的图像,图像分类模型可以解释它的核心特征,并很容易地将图像标记为“狗”。如果图像包含两个对象,比如猫和狗,模型使用多标签分类器对这两个对象进行分类。
除了定义对象类之外,图像分类模型不接受任何用于对象定位的变量。这就是目标检测的作用。
目标检测算法可以通过在图像周围绘制边界框来识别对象类并预测物体在图像中的确切位置。这是图像分类和物体定位的结合,使系统能够知道每个物体在图像中的位置及其原因。它使系统能够直观地分析每个对象,并确定它们在现实生活中的应用,就像人类一样。
目标检测的实际应用
到目前为止,目标检测已经在安全、交通、医疗和军事等关键领域取得了巨大成就。为了提高生产效率,软件公司使用它来自动检索和分类大型关系数据集。这个过程也称为数据标记。
以下是一些现实生活中的应用,引用了人工智能驱动的物体检测系统的重要性:
到目前为止,目标检测已经在安全、交通、医疗和军事等关键领域取得了巨大成就。为了提高生产效率,软件公司使用它来自动检索和分类大型关系数据集。这个过程也称为数据标记。
以下是一些现实生活中的应用,引用了人工智能驱动的物体检测系统的重要性:
警察和法医:物体检测可以跟踪和定位特定的物体,如人、车辆或背包,从帧到帧。它允许警察和法医专业人员检查犯罪现场的每一个角落,以收集证据。然而,由于大量数据的存在,物体检测的过程有点棘手,需要数小时的镜头来确定什么可以帮助案件的成功。
非接触式结账:许多餐厅使用RFID对象跟踪,通过扫描空盘子来计算结账金额。这一过程会自动将所有项目的价格加到总额中,并消除了餐厅中常见的现金和信贷交易。
库存和仓储:物流专业人员可以通过实时物体检测轻松检测、分类和提取成品进行运输。一些公司甚至开发了自助机器,可以将包装好的物品送到客户家中,而无需人与人之间的接触。它还可以通过跟踪库存水平来自动化和调节供应链管理,以确定最佳的生产流程。
停车系统:预先集成在汽车中的视觉探测器可以检测到地面停车场或停车场的开放停车位。它还可以为驾驶员提供停车位和其他车辆的前后视图,以安全地停车。
生物识别和面部识别:机场安检在登机口附近使用面部识别来证明旅客的身份。面部识别设备将身份文件与指纹等其他生物识别技术进行比较,以防止欺诈和身份盗窃。在国际中转过程中,移民和海关部门使用面部匹配来将旅行者的肖像与护照上的照片进行比较。
7大生物认证平台:
LastPass
RSA SecurID套件
RSA SecurID®访问
ValidSoft VIP语音识别平台
Yubico
Secret Double Octopus
Nowsta
*根据2022年7月21日收集的G2数据,这是7个领先的生物识别认证平台。
**灾害响应:**我们的生态系统最近的波动,如臭氧层的恶化、温室气体的增加和全球变暖,总的来说,已经促使开发人员和工程师创建目标检测应用程序。通过微调神经网络和使用基本工具包,可以为灾害响应和管理建立快速准确的模型。
目标检测不仅仅是超级计算机时代的产物;这也是对人类安全未来的承诺。除了为机器提供人工智能视觉之外,它还比我们更好地发现、分析和解决我们的世俗问题。
物体检测可能还不够广泛。但它已经开辟了跨越商业链的成功之路。这里没有回头路了。
通过使用自然语言处理(NLP)软件进行面部和语音到文本识别,探索您业务中的众多人工智能可能性。
原作者简介:

Shreya Mattoo
Shreya is a Content Marketing Specialist at G2. Graduated in 2017 with a major in Computer Applications, she is now an experienced content developer with a demonstrated sales and marketing background. Driven by targets and willingness to learn, she believes that learning is a way of success. When she’s free, you can catch her reading crime fiction, watching documentaries or immersing herself in music.
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









