






地物分类是遥感的基础之一,同时也是重点之一;接下来小编将给大家介绍如何使用GEE基于随机森林算法进行地物分类以及对分类结果进行精度评估;
一.导入所需影像、行政边界以及样本点(数量不能超过5000个)(以Sentinel2A为例)
var roi=ee.FeatureCollection('projects/ee-zs2003/assets/JX_border');
var sample=ee.FeatureCollection('projects/ee-zs2003/assets/jiangxi_sample');
var s2c=ee.ImageCollection('COPERNICUS/S2_SR_HARMONIZED')
.filterDate("2023-1-1","2023-12-31") //选取时间
.filterBounds(roi)
.select("B2","B3","B4","B8","B11") //选择波段
.filter(ee.Filter.lte("CLOUDY_PIXEL_PERCENTAGE",5)) //筛选出云量小于5%的影像
.median() //对影像集合进行中值合成
.clip(roi); //裁剪至研究区范围对影像添加特征波段以辅助分类
//对分类图像添加特征波段
var MNDWI=s2c.normalizedDifference(['B3','B11']).rename('MNDWI');
var NDBI=s2c.normalizedDifference(['B11','B8']).rename('NDBI');
var NDVI=s2c.normalizedDifference(['B8','B4']).rename('NDVI');
var rawimage=s2c.addBands(MNDWI).addBands(NDBI).addBands(NDVI);选取要进行分类的特征波段以及样本点属性字段对应的字段名
var bands = ["B2","B3","B4","NDVI","MNDWI","NDBI"];
var classProperty = 'type';对样本点进行采样操作,即获取每个样本点对应的像元中每个特征波段的信息
var inforsample = rawimage.select(bands).sampleRegions({
collection: sample,
properties: [classProperty],
scale: 10
});将样本点随机取70%作为训练集,剩下30%作为验证集
var withRandom = inforsample.randomColumn('random');
var split = 0.7;
var trainingPartition = withRandom.filter(ee.Filter.lt('random', split));
var validationPartition = withRandom.filter(ee.Filter.gte('random', split));对训练集进行随机森林分类模型训练
// 构建随机森林分类模型
var classifier = ee.Classifier.smileRandomForest(100).train({
features: trainingPartition,
classProperty: classProperty,
inputProperties:bands
});将影像利用训练好的模型进行分类,得到分类图像并显示出来
var classified = rawimage.classify(classifier);
Map.addLayer(classified, {min: 1, max: 6, palette: ['yellow','green','00ffff','orange','red','blue']},"随机森林分类");
//一共有6类,对应的分别是:耕地、林地、草地、裸地、建成区、水体对分类结果进行精度评估:这里主要有两种方法:
1、利用验证样本集对第六步训练集训练好的模型进行评估,这也是GEE官方示例给出的精度评估方式,同时也是对机器学习模型进行精度评估的常用方法
var test = validationPartition.classify(classifier);
var confusionMatrix = test.errorMatrix(classProperty, 'classification');
print("混淆矩阵", confusionMatrix);
print("Kappa系数", confusionMatrix.kappa());
print("总体精度", confusionMatrix1.accuracy());2. 直接利用验证样本集对分类好的图像进行验证,这是做遥感影像地物分类最常用的方法,就应用场景而言比第一种方法要更合理一些
var test = classified.sampleRegions({
collection:validationPartition,
properties: [classProperty],
scale: 10
});
var confusionMatrix = test.errorMatrix(classProperty, 'classification');
print("混淆矩阵", confusionMatrix);
print("Kappa系数", confusionMatrix.kappa());
print("总体精度", confusionMatrix1.accuracy());
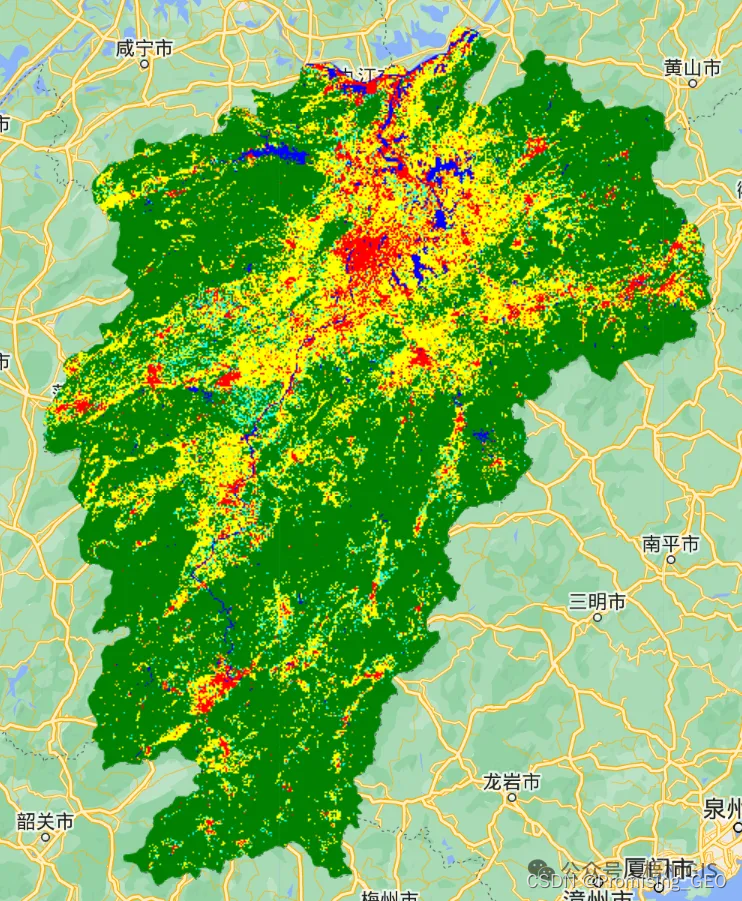


两种不同精度评估方式得到的结果也会有所不同,但是差异并不大;
对于精度问题,可以加入水体掩膜、灯光数据、POI密度、路网密度等辅助数据以提高分类精度,如有需要,欢迎私信留言!
完整代码链接如下:
https://code.earthengine.google.com/4e0e71f23c8cae8cb8a0ac65484cbdf5?asset=projects%2Fee-lihuanfen9585%2Fassets%2Fnc1
















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









