







 本文介绍了如何使用Google Earth Engine(GEE)进行随机森林分类,以进行土地利用分类。通过选取研究区域和 Landsat 8 数据集,建立样本点并进行训练与验证。最终通过混淆矩阵计算分类精度和Kappa系数,评估模型性能。虽然Kappa系数未达到80%,但展示了GEE在遥感图像分类中的应用。
本文介绍了如何使用Google Earth Engine(GEE)进行随机森林分类,以进行土地利用分类。通过选取研究区域和 Landsat 8 数据集,建立样本点并进行训练与验证。最终通过混淆矩阵计算分类精度和Kappa系数,评估模型性能。虽然Kappa系数未达到80%,但展示了GEE在遥感图像分类中的应用。
今日分享:
Google Earth Engine(GEE)随机森林分类
九月第一天,来简单分享下如何在GEE中进行随机森林分类。之做土地利用分类,一直再用ENVI去做,发现做分类时,用ENVI的插件时间太长了,所以就试试用GEE去做一下监督分类。
主要参考Google Earth Engine(GEE)的官方文档
01
—
GEE部分实现代码
选择研究区和数据集
var roi = ee.Geometry.Polygon(
[[[105.76168216373424, 38.90136066495491],
[105.76168216373424, 37.81375799864711],
[106.89327396060924, 37.81375799864711],
[106.89327396060924, 38.90136066495491]]], null, false);
Map.centerObject(roi,10)
var landsat8col = ee.ImageCollection('LANDSAT/LC08/C02/T1_L2')
.filterDate('2021-07-01', '2021-09-30')
.filterBounds(roi)
.filter(ee.Filter.lte('CLOUD_COVER',5))//云量设置
.median();
//显示
var visualization = {
min: 0.0,
max: 60000,
bands: ['SR_B5', 'SR_B4', 'SR_B3'],
};
var clip_L8_ = landsat8col.clip(roi)
Map.addLayer(landsat8col.clip(roi), visualization, '假彩色');建立并选择样本点,我大致分了常见的六个地类,分别是耕地,草地,林地,居民点及工矿用地,水域,未利用地,设置了用于训练的样本和验证的样本
var training = Crop.merge(grassland).merge(Forest).merge(Urban).merge(Water).merge(Bareland);
print(training);
var trainingData = training.randomColumn('random')
//其实就是80%的样本用于分类
//其余20%的样本用于验证
var sample_training = trainingData.filter(ee.Filter.lte("random", 0.8));
var sample_validate = trainingData.filter(ee.Filter.gt("random", 0.8));然后就可以调用模型进行随机森林分类了(ps:样本点还是要自己选的)
var classifier = ee.Classifier.smileRandomForest(50)
.train({
features: training,
classProperty: 'class',
inputProperties: clip_L8_.bandNames()
});
var Classified_RF = clip_L8_ .classify(classifier).byte();
var dict = classifier.explain();
var variable_importance = ee.Feature(null, ee.Dictionary(dict).get('importance'));
Map.addLayer(Classified_RF.clip(roi),{min: 0, max: 5,
palette: ['c0c220','26ff4a','7eff8d','ff4e28','319599',"989990"]}, 'Classified_RF');然后就可以用混淆矩阵法去计算分类精度和kappa系数
// 总体分类精度
var accuracy = testAccuracy.accuracy();
// Kappa系数
var kappa = testAccuracy.kappa();最后就是的导出分类后的结果了
Export.image.toDrive({
image: Classified_RF,
description: 'RF2021a',
crs: "EPSG:32649",
scale: 30,
region: roi,
maxPixels: 1e13,
folder: 'RF'
});02
—
结果显示
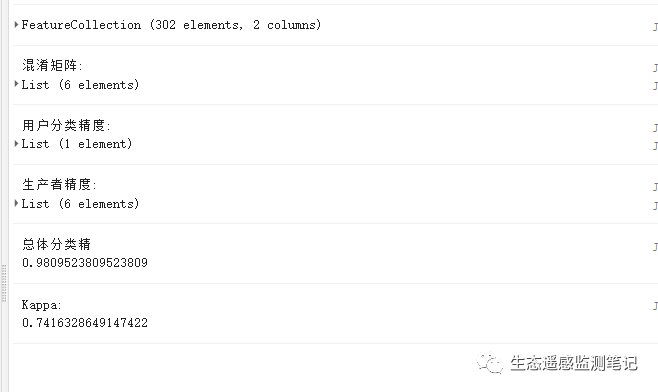
kappa系数没有到80%以上,可能是我选的样本有点问题



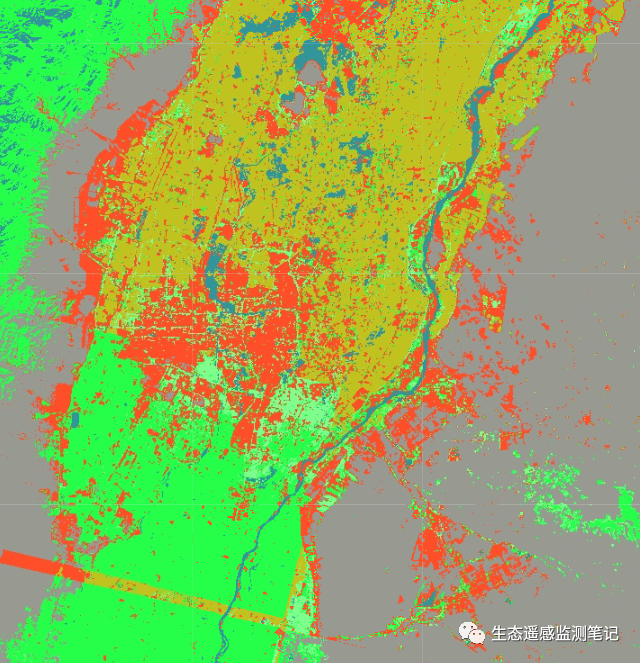
分类结果
完整代码请在公众号后台私信“0901随机森林分类”
感谢关注,欢迎转发!
声明:仅供学习使用!
希望关注的朋友们转发,如果对你有帮助的话记得给小编点个赞或者在看!
## ****更多内容请关注微信公众号“生态遥感监测笔记”**


















 2887
2887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











