









 本文详细介绍如何使用Python的Pandas库进行数据处理与分析,包括数据的合并、清洗、转换、标准化以及异常值处理等关键步骤。
本文详细介绍如何使用Python的Pandas库进行数据处理与分析,包括数据的合并、清洗、转换、标准化以及异常值处理等关键步骤。
合并数据
堆叠合并数据
concat函数(可横向可纵向)
pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False,copy=True)
| 数据名称 | 说明 |
|---|---|
| objs | 接收多个Series,DataFrame,Panel的组合。多个列表组合,无默认 |
| axis | 0 or 1,连接的轴向。默认0 |
| join | 接收inner或者outer,表示是按照交集(inner)还是并集(outer)进行合并,默认outer |
| join_axes | 接收index对象,表示对其他n-1条轴的索引,不知行交集并集运算 |
| ignore_index | 接收布尔,是否不保留连接轴上的索引,产生一组新的索引range(total_length),默认False |
| keys | 接收sequence,与连接对象有关的值,用于形成连接周向上的层次化索引,默认None |
| levels | 接收多个sequence的list |
| names | 接收list,在设置了keys和levels,用于创建分层级别的名称,None |
| verify_integrity | 接收布尔,检查结果对象新轴上的重复情况,发现重复引发异常。默认False |
横向堆叠
- 当axis=1是左行对其,可以使用join参数进行内连接还是外连接,内连接仅返回索引重叠部分,外连接不足的地方用Na不齐
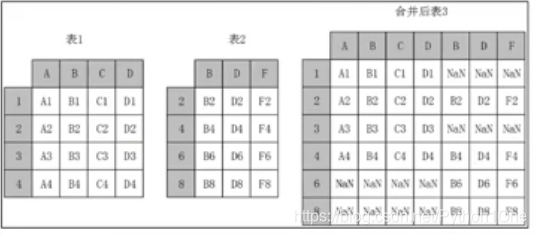
纵向堆叠
- 当axis=0做列对其
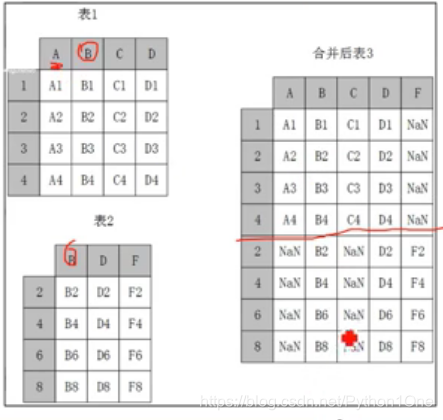
纵向堆叠——append方法
做纵向堆叠,两张表的列名要相同
pd.DataFrame.append(self,other,ignore_index=False,verify_integrity=False)
| 参数名称 | 说明 |
|---|---|
| self | 与DataFrame进行堆叠 |
| other | 接收其他的DataFrame或者series |
| ignore_index | true产生新索引,默认False |
| verify_integrity | true时当ignore_index为False时检查数据索引是否冲突若冲突添加失败,默认False |
- 实例
横向外、内连接
df1 = lis.iloc[:,:10]
df2 = lis.iloc[:,10:]
print(df1.shape,df2.shape)
print(pd.concat([df1,df2],axis=1,join='inner').shape) # 外连接
print(pd.concat([df1,df2],axis=1,join='outer').shape)# 内连接
>>>
>(2779, 10) (2779, 9)
(2779, 19)
(2779, 19)
纵向外、内连接
df3 = lis.iloc[:1500,:]
df4 = lis.iloc[1500:,:]
print(df3.shape,df4.shape)
print(pd.concat([df3,df4],axis=0,join='inner').shape) # 外连接
print(pd.concat([df3,df4],axis=0,join='outer').shape)# 内连接
>>>
>(1500, 19) (1279, 19)
(2779, 19)
(2779, 19)
- append连接
print(df3.shape,df4.shape)
print(df3.append(df4).shape)
>>>
>(1500, 19) (1279, 19)
(2779, 19)
主键合并数据
相当于SQL中的join,根据某个字段进行合并。
merge函数
pd.merge(left,right,how,on,left_on,right_on,left_index,right_index,sort,suffixes)
| 参数 | 说明 |
|---|---|
| left | 接受dataframe或者series。表示要添加的新数据。没有默认 |
| right | 接受dataframe或者series。表示要添加的数据,没有默认 |
| how | 接受inner,outer,left,right。表示数据的连接方式。默认为inner |
| on | 表示两个数据合并的主键(必须一致)。默认为None |
| right_on | 接受string或者sequence.表示right参数接收数据用于合并的主键。默认为None |
| left_on | 接受string或者sequence.表示left参数接收数据用于合并的主键。默认为None |
| left_index | 接受True or False。表示是否将left参数数据的index(行索引)作为连接主键。默认为None |
| right_index | 接受True or False。表示是否将right参数数据的index(行索引)作为连接主键。默认为None |
| sort | 接受boolean。表示是否根据连接键对合并后的数据进行降序。默认为False |
| suffixes | 接受tupple。表示用于追加到left和right参数接受数据列明相同时的后缀。默认为(’_x’,’_y’) |
join函数
使用join方法时,两个主键的名字必须相同。
dataframe.join(self,other,on=None,how=‘left’,lsuffix=’’,resuffix=’’,sort=False)
| 参数 | 说明 |
|---|---|
| other | 接收dataframe或者series或者list.表示参与连接的其他dataframe |
| on | 接收列名或者包含列名的List,tuple。表示用于连接的列名。默认为None |
| how | 接收 inner outer left right,默认为inner |
| lsuffix | 接受string,表示用于追加到左侧重叠列名的尾缀,无默认 |
| rsuffix | 接受string,表示用于追加到右侧重叠列名的尾缀,无默认 |
| sort | 接受boolean,根据连接键对合并后的数据进行排序 |
重叠合并数据
此处的数据合并比较类似于字典中的updata方法。用一个dataframe来更新弥补另一个dataframe中相同位置处的缺失值。
dataframe.combine_first(other)
dict1 = {'ID':[1,2,3,4,5,6,7,8,9],
'System':['win10','win10',np.nan,'win10',np.nan,np.nan,'win7','win7','win8'],
'cpu':['i7','i5',np.nan,'i7',np.nan,np.nan,'i5','i5','i3']}
dict2 = {'ID':[1,2,3,4,5,6,7,8,9],
'System':[np.nan, np.nan,'win7',np.nan,'win8','win7',np.nan,np.nan,np.nan],
'cpu':[np.nan,np.nan,'i3',np.nan,'i7','i5',np.nan,np.nan,np.nan]}
df5 = pd.DataFrame(dict1)
df6 = pd.DataFrame(dict2)
print('经过重叠合并后的数据为:\n',df5.combine_first(df6))
解释
创建了两个字典各有nan数据(空数据)两字典列名行数完全相同,两字段合并,将没有数据的填充
清洗数据
检测与处理重复值
记录重复
DataFrame.duplicated()记录重复
去除重复
- 利用list去重
def delRep(list1):
list2 = []
for i in list1:
if i not in list2:
list2.append(i)
return list2
- 利用集合set的元素是唯一的特性去重
dish_set = set(dishes)
- pandas提供drop_duplicates的方法去重,只对DataFrame和Series有效,不改变排列,代码简介,运行稳定。
DataFrame(Serise).drop_duplicates(self,subset=None,Keep='first',inplace=False)
| 参数名称 | 说明 |
|---|---|
| subset | 接收string或者sequence。表示去重的列,默认None,全部相同才会认为是重复 |
| keep | 接收First,Last,False,表示如果重复保留第几个数据,False表示重复的话直接去除数据,默认First |
| inplace | 接收布尔,是否在原表进行操做,默认False |
检测与处理缺失值
利用isnull或notnull找到缺失值
- pandas提供isnull和notnull来找到缺失值来返回False或者True
- 结合sum可以找出有多少个缺失值
- isnull与notnull的返回结果正好相反
- 找到缺失值后与源数据做loc操作
print("删除缺失记录前数据的形状为:",data1.shape)
exp1 = data1["SUM_YR_1"].notnull()
exp2 = data1["SUM_YR_2"].notnull()
exp = exp1 & exp2 # 与操作
data1_notnull = data1.loc[exp,:] #不太好理解
print('删除缺失记录后数据的形状为:',data1_notnull.shape)
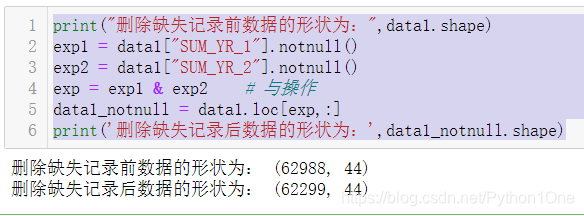
- 或者直接操作
data1_notnull = data1[exp]

删除法
DataFrame.dropna(self,asix=0,how='any',thresh=None,subset=None,inplace=False)
| 参数名称 | 说明 |
|---|---|
| asix | 接收0或者1,0表示删除观测记录(行),1表示删除特征(列)。默认0 |
| how | 接收特定string,any表示只要有缺失就执行删除,all表示当全部为确实才执行删除,默认any |
| subset | 接收array数据,表示去重的列或者行,默认None,所有行列 |
| inplace | 接收布尔,是否在原表进行操做,默认False |
异常值处理
df.replace()更换方法
df.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method='pad')
| 参数 | 说明 |
|---|---|
| to_replace | 表示查找被替换纸的方式 |
| value | 用来替换任何匹配to_replace的值,默认None |
标准化数据
离差标准化数据
离差标准化公式
将数据变为[0,1]
X*=X-min/max-min
- min是最小值
- man是最大值
# 定义离差标准化函数
def MinMaxScale(data):
data = (data-data.min())/data.max()-data.min()
return data
# 对商品的售价和销量做离差
data1 = MinMaxScale(detail['counts'])
data2 = MinMaxScale(detail['amounts'])
data3 = pd.concat([data1,data2],axis=1)
print(detail.loc[:10,['counts','amounts']])
print(data3.iloc[:10])
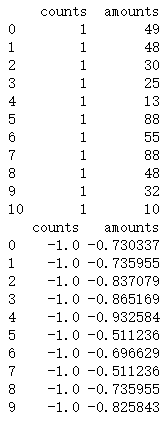
离差标准化特点
- 数据不会变化,原先取值大的数据还是大。
- 数据和min值相等时,通过离差标准化数据变为0
- 数据极差过大,出现中间数值非常小的情况
- 若某个数值很大,则离差标准化会接近0,并且相互之间差别不大。若将来遇到超过或小于min,max的时候会引起系统报错,需要重新确定min,max
标注差标准化数据
公式及其特点
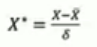
x-原始数据的均值除原始数据的标注差,也不会改变数据分布
def StandarScaler(data):
data = (data-data.mean())/data.std()
return data
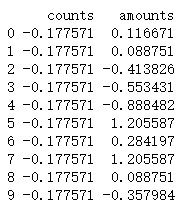
data4 = StandarScaler(detail['counts'])
data5 = StandarScaler(detail['amounts'])
data6 = pd.concat([data4,data5],axis=1)
print(data6.iloc[:10])
小数定标标准化数据
公式及对比
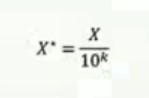
k = 数据中,绝对值最大的值得位数
自定义小数定标准差标准化函数
def DeccimalScaler(data):
data = data/10**np.ceil(np.log10(data.abs().max()))
return data
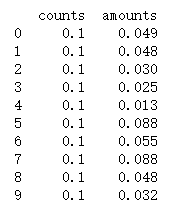
data7 = DeccimalScaler(detail['counts'])
data8 = DeccimalScaler(detail['amounts'])
data9 = pd.concat([data7,data8],axis=1)
print(data9.iloc[:10])
- 离差标准化方法简单,标准化的数据限定在[0,1]之间
- 标准差标准化受到数据分布的影响较小
- 小数定标标准化方法适用范围广,受到数据分布影响小,更加实用
转换数据
哑变量处理类别数据
哑变量处理
数据分析模型中的算法要求输入特征为数值型,但是有部分数据不是数值型,这些数据需要进行哑变量处理才可放入模型之中。
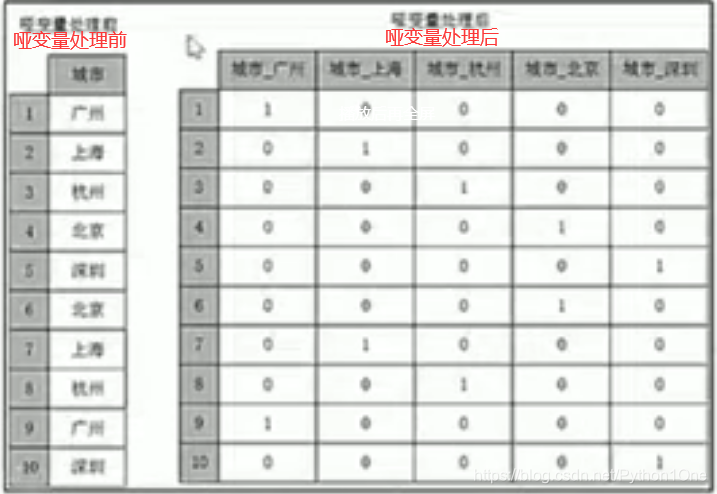
get_dummies函数进行哑变量处理
pd.get_dummies(data,prefix=None,prefix_sep='_',dummy_na=False,colimns=None,sparse=False,drop_first=False)
| 参数名称 | 说明 |
|---|---|
| data | 接收array、DataFrame或者Series。表示需要处理的数据 |
| prefix | 接收String、string列表或者string的dict。表示哑变量处理后的列名的前缀。默认None |
| prefix_sep | 接收string,表示前缀的连接符。默认‘_’ |
| dummy_na | 接收布尔,是否为Nan值添加一列,默认False |
| colimns | 接收list数据,表示DataFrame中需要编码的列名,默认None,表示对所有objecy和category类型进行编码 |
| sparse | 接收布尔,虚拟列是否是稀疏的,默认False |
| drop_first | 接收布尔,是否通过从k个分类级别中删除第一级来获得k-1个分类级别。默认False |
data = detail.loc[:5,'dishes_name']
print("前:\n",data)
print('后:\n',pd.get_dummies(data))

特点
- 对一个类别型特征若有m个,则经过哑变量处理后就变成了m个二元特征,并且这些特征相斥,每次只有一个激活,这使得数据变得稀松
- 主要解决算法模型无法处理的数据类型,在一定程度上起到了扩充特征的作用,由于疏忽变成了稀疏矩阵,加速了算法模型的运算速度。
离散化连续性数据
离散化
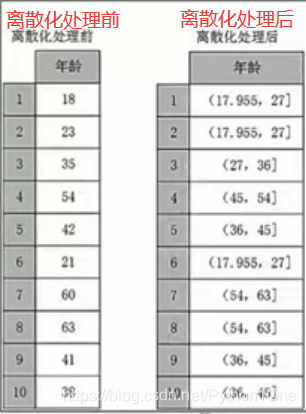
等宽法
将数据的值域分成具有相同宽度的区间。
pd.cut(x,bins,right=True,labels=None,rebins=False,precision=3,include_lowest=False)
| 参数名称 | 说明 |
|---|---|
| x | 接收数据或者Series。代表要处理数据 |
| bins | 接收int,list,array,tuple.若为int,代表离散化后的类别数目;若为序列类型的数据,则表示进行切分的区间,没连个数间隔为一个区间,无默认 |
| right | 接收布尔,是否右侧为闭区间,默认True |
| labels | 接收list,array,代表历史那后各个标签的别称,默认空 |
| rebins | 接收布尔,代表是否返回区间的标签,默认False |
| precision | 接收int,显示标签的精度,默认3 |
| include_lowest | 接收布尔, |
price = pd.cut(detail['amounts'],5)
print("离散化后的数据\n",price.value_counts())

- (0.823, 36.4] 之间的数据有5461个而(107.2, 142.6]之间的数据有154个
- 对数据分布有较高的要求,若数据分布不均匀,name各类的数目也会变得不均匀,有些区间包含许多数据,有些包含数据极少。
等频法
def SameRateCut(data,k):
w = data.quantile(np.arange(0,1+1.0/k,1.0/k))
data = pd.cut(data,w)
return data
result = SameRateCut(detail['amounts'],5).value_counts()
print(result)

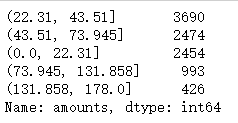
基于聚类分析的方法
自定义数据k-means聚类离散化函数
def KmeanCut(data,k):
from sklearn.cluster import KMeans # 引入KMeans
kmodel=KMeans(n_clusters=k,n_jobs=4) # 建立模型,n_jobs是并行数
kmodel.fit(data.values.reshape((len(data),1))) # 训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort_values(0) # 输出聚类中心并排序
# w = pd.rolling_mean(c,2).iloc[1:]
w = c.rolling(2).mean().iloc[1:] # 相邻两项求重点,作为便捷点
w = [0]+list(w[0])+[data.max()] # 把首末边界点加上
data = pd.cut(data,w)
return data
result = KmeanCut(detail['amounts'],5).value_counts()
print(result)
使用scikit-learn构建模型
参考下一章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









