










“ 打造一款模型是一件非常复杂的事情,设计的问题也非常非常多,因此大家要做好心理准备 ”
这段时间写的文章主要都在讲大模型的应用问题,以及自己在工作中遇到的一些问题;而今天我们就从大模型服务的角度,来思考一下打造一款大模型需要经过哪些步骤,也就是怎么打造一款大模型。
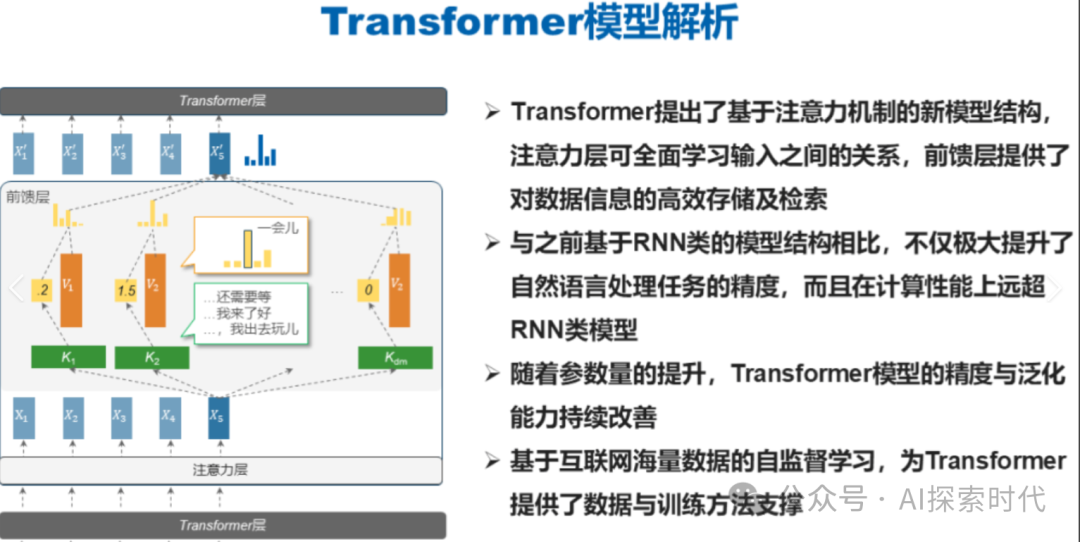
怎么打造一款大模型?
可能不同的人对大模型有不同的理解,不同的企业实现大模型的方式可能也不太一样;但其大体上的步骤和过程还是差不多的。
打造一款大模型第一步应该做什么?
有人说打造大模型的第一步是做训练数据的收集与整理;从技术的角度来说这么说也没错,但从流程上来说就有点问题了,你都不知道你想要一个什么样的大模型,那你怎么收集数据?
在上一篇文章中讲过怎么设计一款大模型,但设计模型只是打造模型的其中一个步骤。
要想打造一款模型,基本上要经过以下几个重要步骤:
-
需求采集__与分析
不论做任何事情,第一步都要明白自己想要做什么;因此,第一步就是采集需求,分析需求,然后根据需求设计功能点。
这里面还涉及到很多细节方面的东西,比如需求评审,需求确认,需求文档等等,这里就不详细展开讨论了。
-
模型的设计与实现
模型的设计与实现,是大模型的项目的关键环节,这个环节可以说是打造模型过程中最复杂,也是最难的一点,其直接决定着模型的性能。具体来说主要包括以下几点:
设计一款模型,需要结合项目目标,数据特性以及算法理论选择或设计一款模型架构。
理解问题:首先你要理解你的需求,就是你到底想做一个什么样的模型,分类,聚类,生成模型等
设计模型架构:比如选择模型架构,transformer,bert,rnn等;然后根据你的需求,设计神经网络的层数,节点数,正/反向传播,损失函数等。
算法选择:现在需求有了,架构也有了,那么采用哪种算法来实现,比如自然语言处理的分词算法,图像处理的卷积算法等。
正则化与优化策略:为了防止过拟合或欠拟合,并提升模型的泛化能力,所以有时需要使用正则等方式对模型进行优化。
设置评估指标:设计一款模型的目的不是为了好玩,而是这个模型能够解决什么问题,因此就需要有一个标准来评估其好坏。
- 准备训练数据
这一步可能很多人都会觉得很简单,训练数据用爬虫爬一下不就有了,或者掏钱买一点就行了;但事实上,在模型训练过程中数据准备也是很重要的一环,模型的好坏除了取决于模型的设计和架构之外,其次就是训练数据的质量了。
数据采集:数据采集包括数据需求定义,数据源,数据采集,数据存储等等。
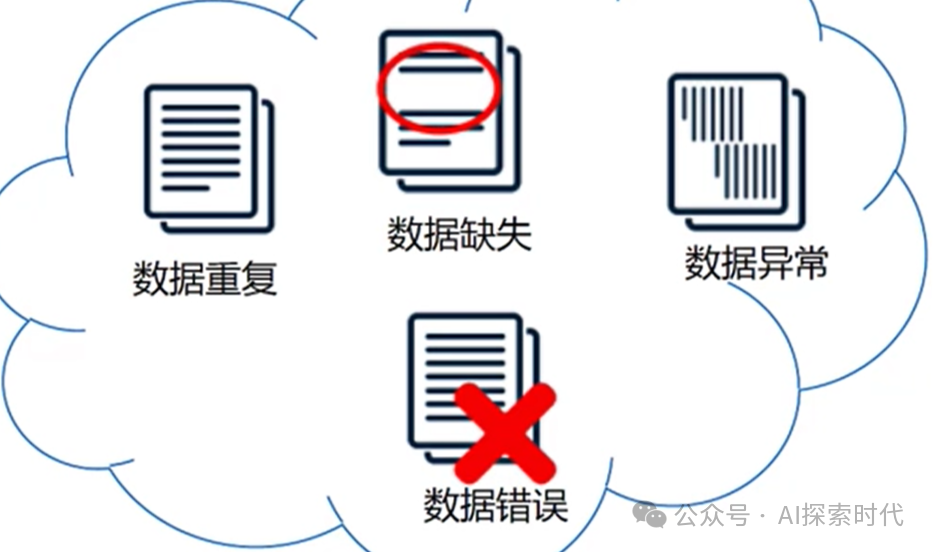
数据清洗与预处理:由于数据采集时,数据来源不一而足,数据质量也不一而足,因此数据的清洗和预处理就显得特别重要,其作用就是保证给到大模型的训练数据是高质量的,而不是随便找的。比如,数据缺失,异常值,数据重复,数据转换等多种操作。
数据标注:数据标注应该大部分人都知道,监督学习过程中,需要大量的标注数据才能进行模型训练;但数据标注也有很多注意点,比如数据标注的目的,如何标注,使用哪种工具,标注质量的检查等等;由于训练数据一般比较庞大,因此很难人工进行检查;因此,其难度可想而知。
数据集的划分:有过模型训练经验的人应该都知道,模型训练一般会把数据集划分成训练集,测试集,验证集等多个模块;但数据集应该怎么划分,有哪些标准;比如划分策略,是随机划分,还是分层抽样,或者根据时间划分等。
最后,还要数据的分割工具,数据的存储与加载等等问题。
- 模型初始化
说到模型初始化,可能有些人听过,有些人根本不知道这玩意;所谓的模型初始化就是,新设计的模型其参数值是默认的或者没有值;因此就需要在训练之前给模型设置一个初始值;这个值可以是随机的,也可以是来自某些经验值。
初始化也是一个复杂的过程,由于某些模型参数量巨大,因此就需要有一个初始化的策略;还有一些参数的权重,包括一些超参数的设计等;比如训练的批次大小,训练速率等。
模型初始化可能会影响到模型的训练成果,或者影响模型的训练效率等。
- 模型训练
模型训练可能是很多人比较感兴趣的一个话题,而且可能有部分人已经自己训练过一些小模型;因此,这里就不再多说了。
模型训练是一个系统性的过程,涉及到训练数据的收集,整理;超参数的设定,正反向传播函数的选择等等。
- 模型测试与验证
模型测试与验证这个就更不用多说了,一款模型的效果怎么样,设计的好不好,训练结果是否达到预期;这些都需要在对模型做过测试和验证之后,才能得到结论。
而模型测试与验证,又涉及到前面的训练数据的划分,以及评估指标的实现等等。
- 模型部署与维护
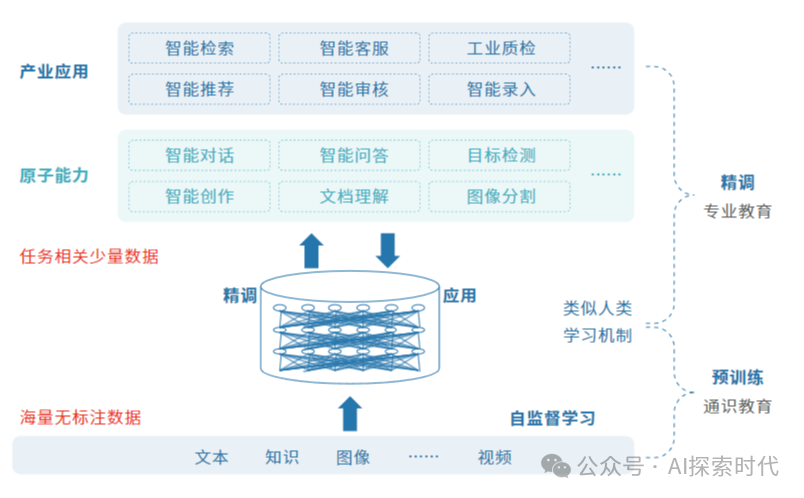
最后,就是大模型的部署与维护了;大模型与传统的普通企业项目不同,大模型体积巨大,不但自己体积大,而且训练数据体积也很庞大;因此单一机器无法承载大模型的训练,部署与维护;因此分布式就成了一个必然选择。
但,大模型在分布式场景中怎么实现,怎么实现并行计算,怎么进行数据和模型的加载,存储;自动化运维应该怎么做,怎么保证模型的高可用性等等。
还有就是,大模型部署完成后的接口封装,怎么把大模型应用到业务系统中,怎么保证其在高并发环境下的性能和稳定性问题等。
总之,大模型由于其体量问题,其部署与维护需要专业的运维团队,并且还要有完善的自动化运维系统,否则靠人力很难完成。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









