




ViT简介
ViT是Vision Transformer的缩写,它是一种基于Transformer架构的模型,用于处理图像识别任务。Transformer最初是在自然语言处理(NLP)领域提出的,特别是在语言模型和机器翻译任务中取得了巨大成功。ViT将Transformer的思想扩展到了计算机视觉领域。
ViT的基本原理
ViT将输入图像转换为一个序列化的表示形式。通过将图像分割成多个固定大小的小块(patches),然后将每个patch线性投影到一个D维的嵌入空间来实现。
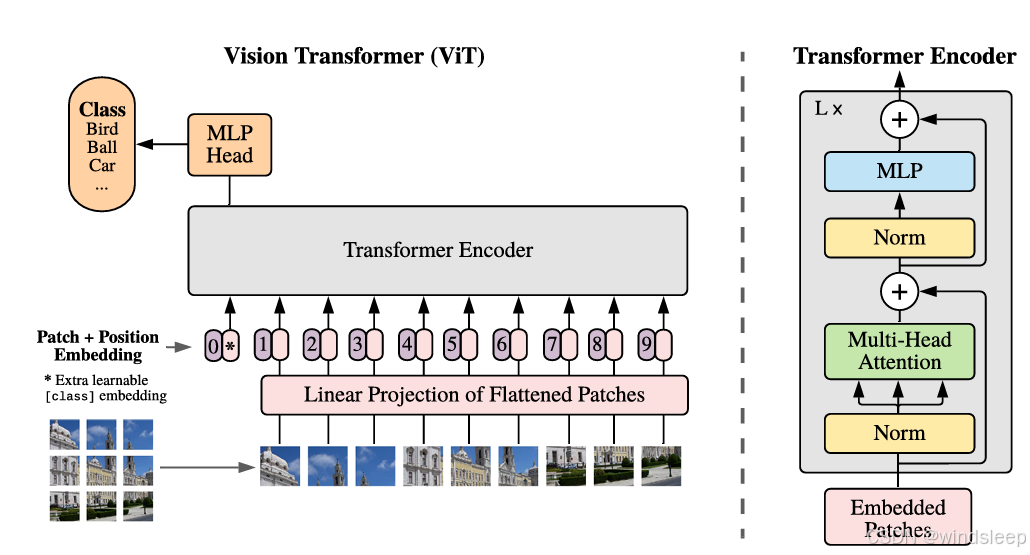
- Patch Embedding:
- 与卷积神经网络(CNN)不同,ViT不直接处理原始像素值。它首先将输入图像划分为多个小块(称为"patches")。
- 每个patch通过一个线性层(即全连接层)被转换成一个D维的特征向量。这一步将图像的二维空间信息转换为一维序列数据。
- Class Token:
- 类似于在Transformer模型中的[CLS] token,ViT引入了一个特殊的类别token,它与图像patches的嵌入向量一起输入到模型中。这个token的最终状态将被用作分类任务的表示。
- Positional Encoding:
- 与Transformer在NLP中使用位置编码类似,ViT向每个patch嵌入向量添加位置编码,以保持序列中每个patch的位置信息。位置编码通常使用正弦和余弦函数的组合来生成,确保模型能够理解图像中的空间结构。
- Multi-head Self-Attention:
- 与NLP中的Transformer相同,ViT使用多头自注意力机制来捕捉不同位置之间的依赖关系。
- 每个头学习图像的不同子空间表示,增强了模型捕获全局上下文的能力。
- Value(V)、Key(K)、Query(Q)的计算:
- 在自注意力层中,模型会为输入序列的每个元素计算K、V和Q。这些计算是通过线性层完成的,然后通过这些向量计算注意力权重,这些权重决定了在生成输出序列时每个元素对其他元素的影响程度。
- Feed-Forward Networks:
- 在自注意力层之后,ViT使用前馈神经网络(FFN)来进一步处理特征。
- Layer Normalization and Residual Connections:
- 与Transformer一样,ViT在每个子层(自注意力和FFN)之后使用层归一化(Layer Normalization)和残差连接(Residual Connections),以促进深层网络的训练。
- Pooling:
- 与CNN中的池化操作不同,ViT不使用固定的池化策略。相反,它可以通过不同的方式(如全局平均池化或通过类别token)来聚合特征。
ViT模型在多个视觉识别任务上表现出色,包括图像分类、目标检测和图像分割等。ViT的成功证明了Transformer架构不仅适用于序列数据,也能够处理具有空间结构的图像数据。
ViT的原始论文名:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
链接:https://arxiv.org/pdf/2010.11929

















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









