







 本文详细介绍了标记分布学习(LDL),它是传统单标记学习(SLL)和多标记学习(MLL)的扩展,目标是让模型预测的标记分布与真实分布接近。文章阐述了LDL的定义,展示了如何从LDL导出MLL和SLL,以及LDL在分类和回归任务中的应用。
本文详细介绍了标记分布学习(LDL),它是传统单标记学习(SLL)和多标记学习(MLL)的扩展,目标是让模型预测的标记分布与真实分布接近。文章阐述了LDL的定义,展示了如何从LDL导出MLL和SLL,以及LDL在分类和回归任务中的应用。
前言
主要简单介绍标记分布学习LDL/ 多标记学习MLL/ 单标记学习三者的概念与联系。
标记分布学习LDL
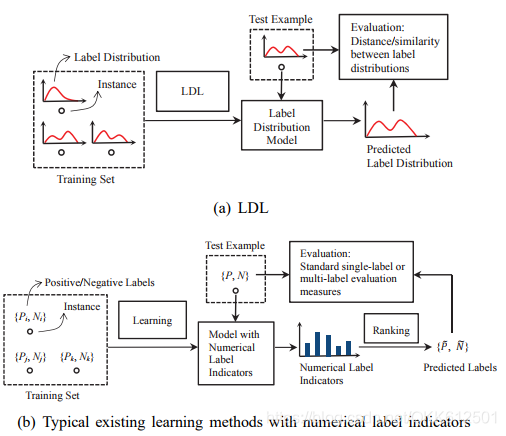
如上图所示, 与传统的单标记学习( single label learning, SLL)和多标记学习(mutli label learning, MLL)不同, 在标记分布学习(label distribution leaning, LDL)中,ground-truth label本身就是以标记分布的(离散)形式给出的,目标就是训练模型使得预测的标记分布与ground-truth label (distribution)尽可能匹配、接近。
下面给出**LDL**的正式定义:
记输入空间为
X
∈
R
q
X \in R^{q}
X∈Rq, 标记的完备集为
Y
=
(
y
1
,
.
.
.
,
y
c
)
Y=(y_{1}, ..., y_{c})
Y=(y1,...,yc), 训练集为:
S
=
{
(
x
1
,
Y
1
)
,
.
.
.
,
(
x
n
,
Y
n
)
}
S=\{(x_{1}, Y_{1}), ..., (x_{n}, Y_{n})\}
S={(x1,Y1),...,(xn,Yn)}, 其中
D
i
D_{i}
Di就是i-th个样本的定义在Y上的ground-truth label distribution。 LDL的目标就是通过优化下面这个问题来学习条件概率分布
p
(
y
∣
x
)
p(y|x)
p(y∣x):
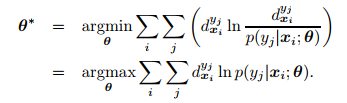
其中
p
(
y
∣
x
;
θ
)
p(y|x;\theta)
p(y∣x;θ)表示由
θ
\theta
θ参数化的模型。上式中采用了KL divergence来度量两个分布之间的"距离"。
LDL与MLL和SLL的关系
MLL和SLL可以看做式LDL的特例, 具体来说:
(1)LDL -> MLL
对于MLL, 每个样本
x
i
x_{i}
xi的标记
Y
i
Y_{i}
Yi为
Y
Y
Y的自子集,对应的优化目标为:
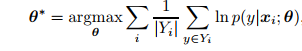
(2)LDL -> SLL
对于SLL,每个样本
x
i
x_{i}
xi的标记
Y
i
Y_{i}
Yi为
Y
Y
Y中的单个标记,记
x
i
x_{i}
xi的真实标记为
y
(
x
i
)
y(x_{i})
y(xi)
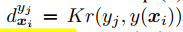
其中
K
r
Kr
Kr为Kronecker delta function, 对应的优化目标可以简化为:
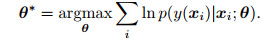
其中
y
(
x
i
)
y(x_{i})
y(xi)为
x
i
x_{i}
xi的真实标记,可以看到此时, 最小化KL divergence已经变为最大化似然函数。
LDL都可以用来做哪些任务?
LDL既可以做分类任务也可以用来做回归任务:
(1)做分类任务
hard label的话实际上就是传统的SLL, 当然也可以将其转化为soft label的形式。
(2)做回归任务
一般要对ground-truth value根据其取值范围进行离散化来产生标记的完备集
Y
Y
Y, 并将每个样本的ground-truth value固定到Y中最近的值, 然后再将其转化为定义在Y的值得分布形式:一般常用高斯分布,即以ground-truth value作为mean value。 模型预测(经过softmax)的结果也是概率分布的形式。


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











