









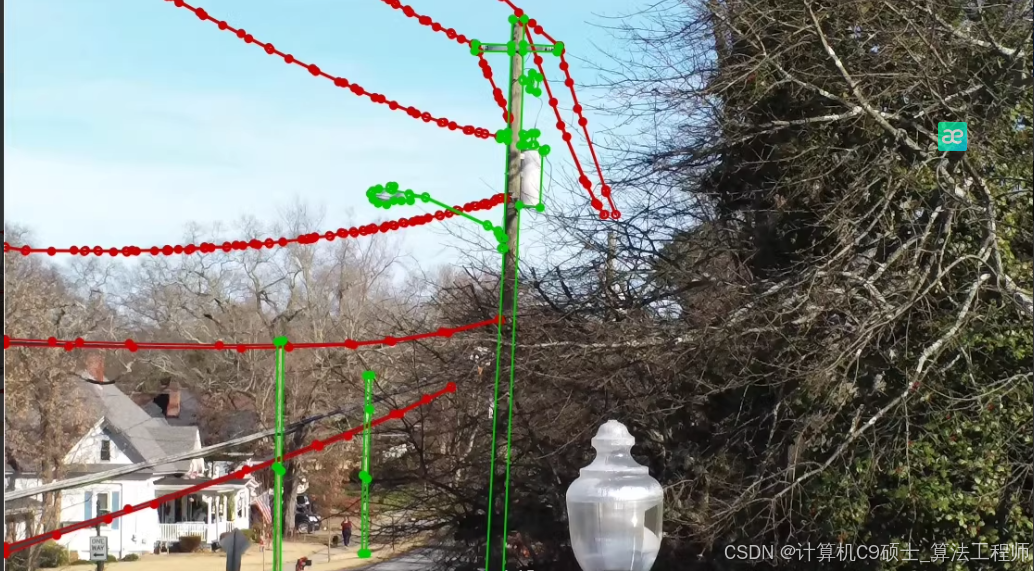
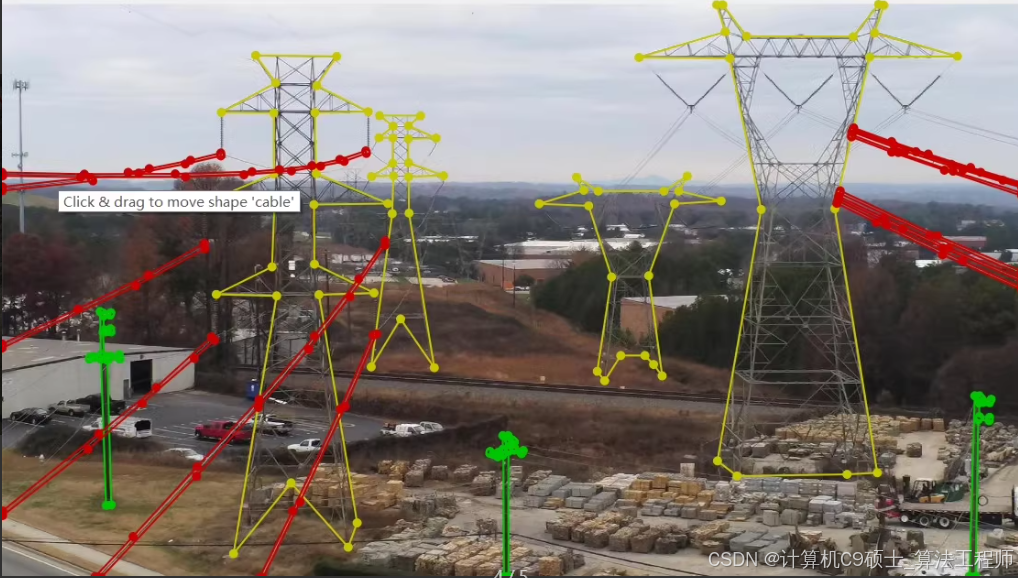
输电线路语义分割图像数据集,输电线路,输电杆塔,水泥杆,输电线路木头杆塔,图片总共1200张左右,包含分割标签,json标签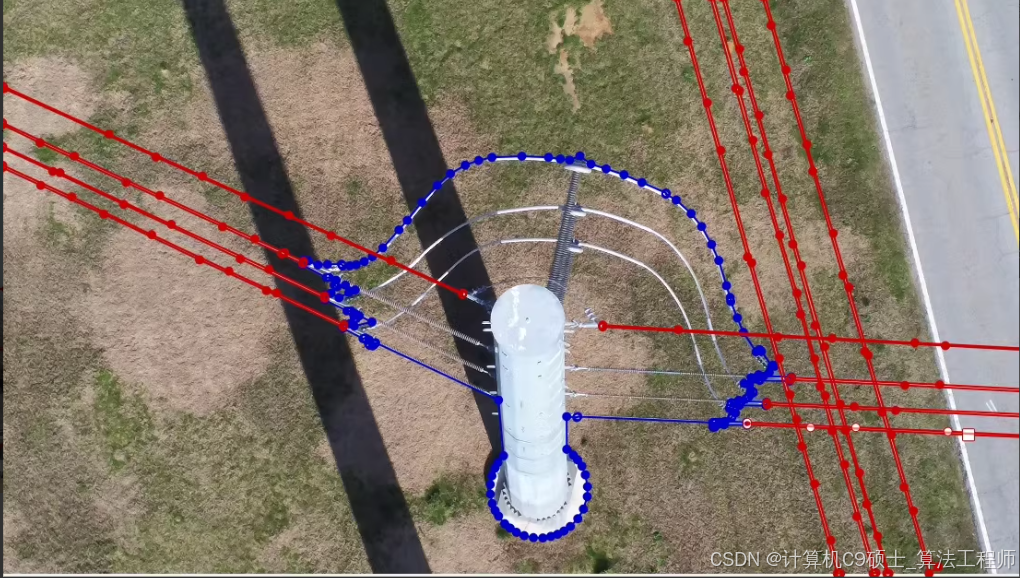

对于输电线路及其相关结构的语义分割任务,您需要准备一个包含图像和对应分割标签的数据集。您的数据集已经包含了1200张左右的图像以及相应的JSON格式的分割标签。接下来,我将指导您如何设置环境、准备数据、定义模型,并进行训练和评估。
1. 环境准备
确保安装了必要的库和工具:
pip install torch torchvision
pip install numpy
pip install matplotlib
pip install opencv-python
pip install pyyaml
pip install albumentations
pip install pycocotools
2. 数据集准备
假设您的数据集目录结构如下:
transmission_line_dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
└── transmission_line_data.yaml
每个图像文件对应一个JSON格式的标签文件,标签文件中包含了每个类别的多边形标注信息。
3. 创建数据集配置文件
创建一个 transmission_line_data.yaml 文件,内容如下:
train: ../transmission_line_dataset/images/train
val: ../transmission_line_dataset/images/val
nc: 4 # 总共有4个类别
names: ['transmission_line', 'transmission_tower', 'concrete_pole', 'wooden_pole']
label_dir: ../transmission_line_dataset/labels

4. 准备数据加载器
我们需要自定义一个数据加载器来读取图像和掩码,并进行数据增强。
import os
import json
import cv2
import numpy as np
from torch.utils.data import Dataset
import albumentations as A
from albumentations.pytorch import ToTensorV2
class TransmissionLineDataset(Dataset):
def __init__(self, image_dir, label_dir, transform=None):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
label_path = os.path.join(self.label_dir, self.images[idx].replace('.jpg', '.json'))
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
with open(label_path, 'r') as f:
label = json.load(f)
mask = np.zeros((image.shape[0], image.shape[1]), dtype=np.uint8)
for shape in label['shapes']:
points = np.array(shape['points'], dtype=np.int32)
cv2.fillPoly(mask, [points], color=shape['label'] + 1) # 假设标签从0开始
if self.transform is not None:
transformed = self.transform(image=image, mask=mask)
image = transformed['image']
mask = transformed['mask']
return image, mask
# 数据增强
transform = A.Compose([
A.Resize(512, 512), # 根据需要调整尺寸
A.Rotate(limit=35, p=1.0),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
])
# 创建数据加载器
train_dataset = TransmissionLineDataset(train_image_dir, train_label_dir, transform=transform)
val_dataset = TransmissionLineDataset(val_image_dir, val_label_dir, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False, num_workers=4)
5. 定义U-Net模型
我们可以使用PyTorch来定义一个简单的U-Net模型。
import torch
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=4, init_features=32):
super(UNet, self).__init__()
features = init_features
self.encoder1 = self._block(in_channels, features)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.encoder2 = self._block(features, features * 2)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.encoder3 = self._block(features * 2, features * 4)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.encoder4 = self._block(features * 4, features * 8)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.bottleneck = self._block(features * 8, features * 16)
self.upconv4 = nn.ConvTranspose2d(features * 16, features * 8, kernel_size=2, stride=2)
self.decoder4 = self._block((features * 8) * 2, features * 8)
self.upconv3 = nn.ConvTranspose2d(features * 8, features * 4, kernel_size=2, stride=2)
self.decoder3 = self._block((features * 4) * 2, features * 4)
self.upconv2 = nn.ConvTranspose2d(features * 4, features * 2, kernel_size=2, stride=2)
self.decoder2 = self._block((features * 2) * 2, features * 2)
self.upconv1 = nn.ConvTranspose2d(features * 2, features, kernel_size=2, stride=2)
self.decoder1 = self._block(features * 2, features)
self.conv = nn.Conv2d(in_channels=features, out_channels=out_channels, kernel_size=1)
def forward(self, x):
enc1 = self.encoder1(x)
enc2 = self.encoder2(self.pool1(enc1))
enc3 = self.encoder3(self.pool2(enc2))
enc4 = self.encoder4(self.pool3(enc3))
bottleneck = self.bottleneck(self.pool4(enc4))
dec4 = self.upconv4(bottleneck)
dec4 = torch.cat((dec4, enc4), dim=1)
dec4 = self.decoder4(dec4)
dec3 = self.upconv3(dec4)
dec3 = torch.cat((dec3, enc3), dim=1)
dec3 = self.decoder3(dec3)
dec2 = self.upconv2(dec3)
dec2 = torch.cat((dec2, enc2), dim=1)
dec2 = self.decoder2(dec2)
dec1 = self.upconv1(dec2)
dec1 = torch.cat((dec1, enc1), dim=1)
dec1 = self.decoder1(dec1)
return torch.softmax(self.conv(dec1), dim=1)
def _block(self, in_channels, features):
return nn.Sequential(
nn.Conv2d(in_channels, features, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(features),
nn.ReLU(inplace=True),
nn.Conv2d(features, features, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(features),
nn.ReLU(inplace=True)
)

6. 训练模型
接下来,我们需要编写训练循环来训练模型。
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = UNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
writer = SummaryWriter(f"runs/{datetime.now().strftime('%Y%m%d-%H%M%S')}")
num_epochs = 20
for epoch in range(num_epochs):
model.train()
for i, (images, masks) in enumerate(train_loader):
images, masks = images.to(device), masks.to(device).long()
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
if (i + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
writer.add_scalar('Training Loss', loss.item(), epoch * len(train_loader) + i)
# 验证阶段
model.eval()
with torch.no_grad():
total_val_loss = 0
for images, masks in val_loader:
images, masks = images.to(device), masks.to(device).long()
outputs = model(images)
loss = criterion(outputs, masks)
total_val_loss += loss.item()
avg_val_loss = total_val_loss / len(val_loader)
print(f'Validation Loss: {avg_val_loss:.4f}')
writer.add_scalar('Validation Loss', avg_val_loss, epoch)
# 保存模型
torch.save(model.state_dict(), f'models/unet_epoch_{epoch+1}.pth')
writer.close()
7. 评估和可视化
训练完成后,您可以使用以下代码来评估模型并在验证集上进行可视化。
import matplotlib.pyplot as plt
def visualize_predictions(model, dataloader, device, n_images=5):
model.eval()
with torch.no_grad():
for i, (images, masks) in enumerate(dataloader):
if i >= n_images:
break
images, masks = images.to(device), masks.to(device).long()
outputs = model(images)
_, predicted_masks = torch.max(outputs, dim=1)
for j in range(images.size(0)):
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
axs[0].imshow(images[j].permute(1, 2, 0).cpu().numpy())
axs[0].set_title('Image')
axs[1].imshow(masks[j].cpu().numpy(), cmap='gray')
axs[1].set_title('Ground Truth Mask')
axs[2].imshow(predicted_masks[j].cpu().numpy(), cmap='gray')
axs[2].set_title('Predicted Mask')
plt.show()
visualize_predictions(model, val_loader, device)
8. 总结
以上步骤展示了如何使用U-Net模型对输电线路及其相关结构进行语义分割。如果您希望使用其他模型或有特定的需求,


















 2697
2697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









