







配置文件解读
-
数据路径:
•train: 训练集路径,指向pets/train/images。
•val: 验证集路径,指向pets/val/images。
•test: 测试集路径被注释掉了,可能是你尚未准备好测试集,或者不需要测试集。 -
类别数量:
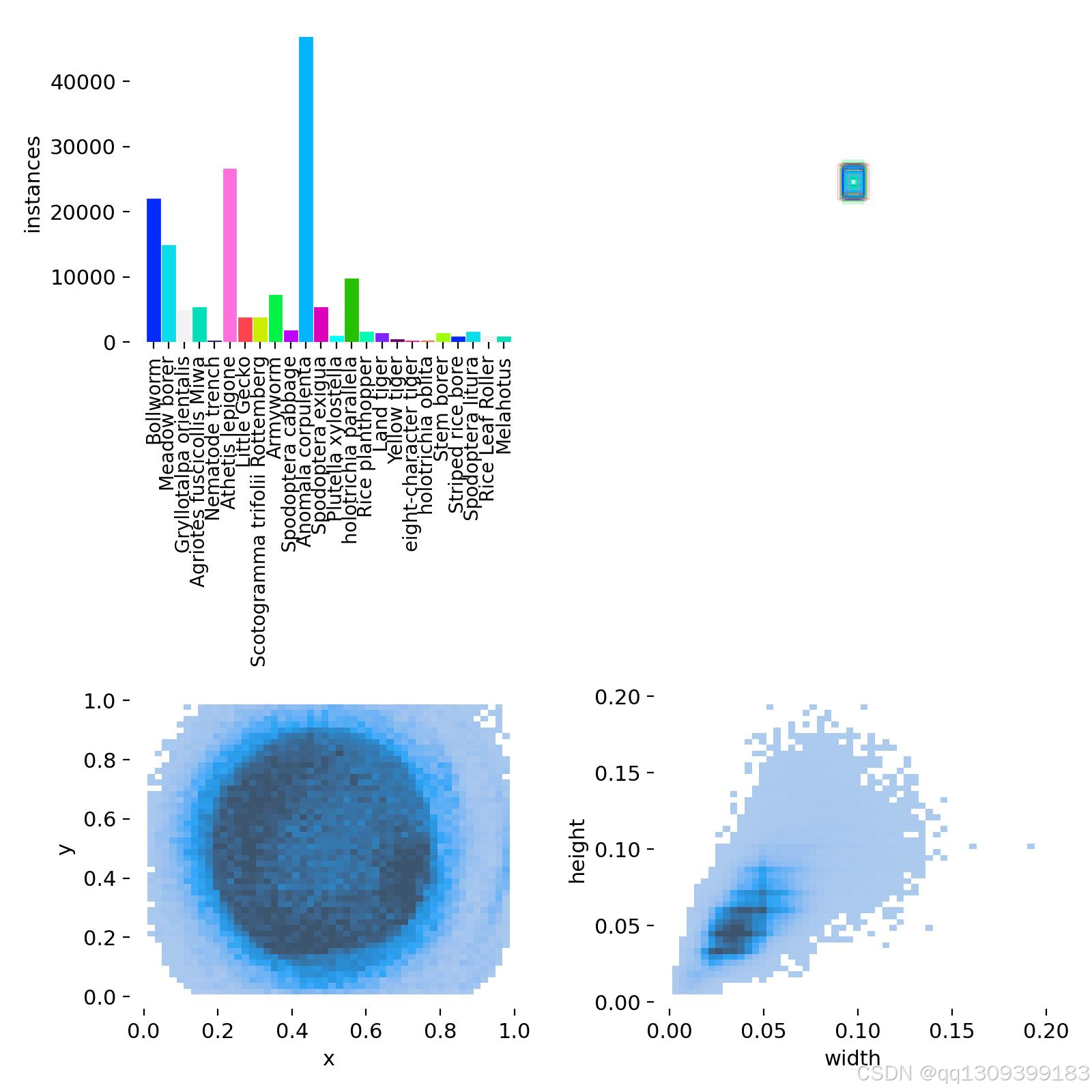
•nc: 24,表示你的数据集中有24个类别。

-
类别名称:
•names列表中列出了24种昆虫的名称,包括:
◦Bollworm(棉铃虫)
◦Meadow borer(草地螟)
◦Gryllotalpa orientalis(东方蝼蛄)
◦Agriotes fuscicollis Miwa(一种金龟子)
◦Nematode trench(线虫沟)
◦Athetis lepigone(甘蓝夜蛾)
◦Little Gecko(小壁虎,可能是误写,应该不是昆虫)
◦Scotogramma trifolii Rottemberg(三叶草夜蛾)
◦Armyworm(草地贪夜蛾)
◦Spodoptera cabbage(甘蓝夜蛾)
◦Anomala corpulenta(铜绿丽金龟)
◦Spodoptera exigua(小菜蛾)
◦Plutella xylostella(菜青虫)
◦holotrichia parallela(平行蝼蛄)
◦Rice planthopper(稻飞虱)
◦Land tiger(地老虎)
◦Yellow tiger(黄地老虎)
◦eight-character tiger(八字地老虎)
◦holotrichia oblita(一种蝼蛄)
◦Stem borer(茎螟)
◦Striped rice bore(条纹螟)
◦Spodoptera litura(斜纹夜蛾)
◦Rice Leaf Roller(稻纵卷叶螟)
◦Melahotus(可能是某种昆虫,但名称不明确)。

-
问题点:
•Little Gecko并不是昆虫,可能是数据标注错误,建议检查并移除。
•Melahotus名称不明确,建议确认其是否为有效分类。
•test数据集路径被注释掉了,如果需要测试模型性能,建议补充测试集。

项目建议
-
数据预处理:
• 确保每张图片的标注文件(如.txt文件)与图片一一对应,且标注格式符合YOLOv11的要求。
• 检查是否有错误标注的类别(如Little Gecko)。
• 如果类别数量较多(如24类),建议对数据进行平衡处理,避免某些类别样本过少。 -
模型训练:
• 使用YOLOv11进行训练时,建议从预训练模型开始(如COCO预训练权重),以加速收敛。
• 设置合适的超参数,如学习率(lr)、批量大小(batch-size)等。
• 如果显存不足,可以尝试减小输入图片的分辨率。 -
类别名称修正:
• 确保names列表中的类别名称准确无误。
• 如果Melahotus是无效分类,建议移除或替换为正确的名称。 -
测试集准备:
• 如果没有测试集,可以从训练集中划分一部分作为验证集,或者收集新的测试数据。
-
模型评估:
• 使用YOLOv11提供的评估工具(如mAP、F1分数等)对模型性能进行评估。
• 如果某些类别的检测效果较差,可以尝试数据增强(如旋转、翻转、亮度调整等)来提升模型的泛化能力。 -
部署与应用:
• 如果项目需要部署到实际场景中,可以考虑将模型转换为ONNX或TensorRT格式以提升推理速度。
• 结合硬件设备(如NVIDIA Jetson系列)进行实时检测。

示例代码(YOLOv11训练命令)
python train.py --data your_data.yaml --weights yolov11n.pt --epochs 300 --batch-size 16 --img-size 640
• your_data.yaml 是你的配置文件。
• yolov11n.pt 是YOLOv11的预训练权重。
• --epochs 300 表示训练300个epoch。
• --batch-size 16 表示每次训练的批量大小。
• --img-size 640 表示输入图片的分辨率为640x640。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









