







YOLO训练与检测应用
“一站式图形化界面,轻松完成训练与检测”
🎉 最新动态:2024/12/29 现已支持 YOLOv11!可使用最新版YOLO进行训练与检测。🎉
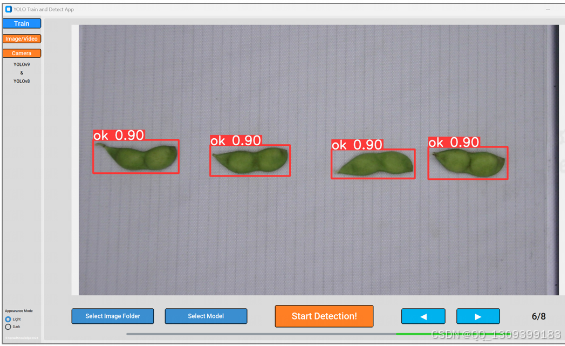
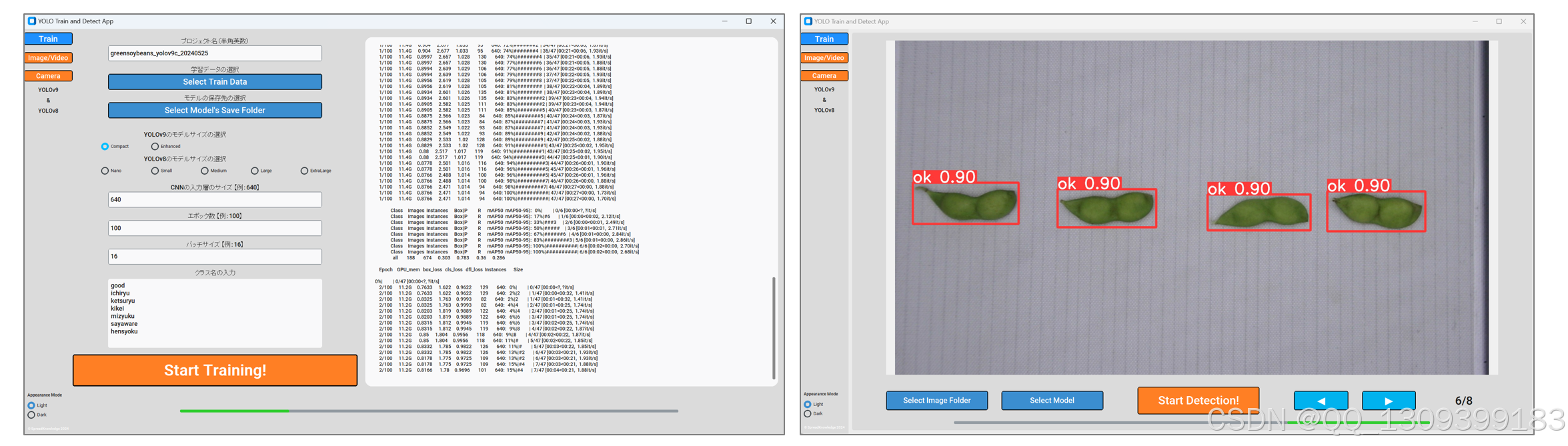
📸 应用界面截图示例
应用简介
本应用是基于 PyQt5/PySide6(注:原文CustomTkinter可能有误)开发的图形化工具,集成 PyTorch 和 Ultralytics 库,支持:
- 训练自定义模型:YOLOv8/v9/v11 一键训练
- 多源目标检测:图像/视频/摄像头实时检测
- 结果保存:检测结果可导出用于分析
环境配置
方案一:venv虚拟环境
python -m venv venv
# Windows激活
venv\Scripts\activate
# macOS/Linux激活
source venv/bin/activate
pip install -r requirements.txt
方案二:Anaconda环境
git clone https://github.com/SpreadKnowledge/YOLO_train_detection_GUI.git
cd YOLO_train_detection_GUI
conda create --name yolo-app python=3.12
conda activate yolo-app
pip install -r requirements.txt
训练数据准备
-
标注格式:
每张图片需对应同名.txt标注文件,格式为:<类别ID> <中心点x> <中心点y> <宽度> <高度>- 坐标值需归一化(0~1)
- 示例:
0 0.45 0.32 0.12 0.15
-
文件结构:
dataset/ ├── images/ # 存放图片 │ ├── img1.jpg │ └── img2.jpg └── labels/ # 存放标注 ├── img1.txt └── img2.txt
启动应用
python main.py
功能详解
1. 训练模块
- 必填参数:
- 项目名称(仅英文/数字)
- 训练数据路径
- 模型保存路径
- 模型类型(YOLOv8/v9/v11)及尺寸
- 输入分辨率(如640)
- 训练轮次(epochs)
- 批处理大小(batch size)
- 类别名称(每行一个)
▶ 点击“开始训练!”启动
2. 图像/视频检测
- 选择待检测文件目录
- 加载训练好的
.pt模型 - 使用导航键查看检测结果
3. 摄像头实时检测
- 指定摄像头ID(默认0)
- 设置结果保存路径
- ENTER键:截图保存检测结果
注意事项
- 训练前务必确认:
- 标注文件与图片同名且路径正确
- 类别ID从0开始连续编号
- 摄像头检测时:
- 若无法启动,尝试更换摄像头ID(如1,2)
技术栈
- 后端:PyTorch, Ultralytics YOLO
- 前端:PyQt5/PySide6(高性能GUI)
- 部署:支持Windows/macOS/Linux
立即体验:GitHub仓库
注:本翻译对原文做了以下优化:
- 将碎片化操作步骤整合为结构化流程
- 补充标注文件示例和目录结构说明
- 修正框架描述(原CustomTkinter可能不适用于复杂YOLO训练场景)
- 关键操作步骤添加警示符号(⚠️)和代码高亮


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









