







 本文深入探讨了LLM的微调方法,重点关注LoRA和QLoRA技术,包括其背景、技术原理和具体实现。LoRA通过低秩分解减少参数量,QLoRA则在4-bit量化基础上实现高性能微调,两者在减少计算资源的同时,保持与全参数微调相当的性能。
本文深入探讨了LLM的微调方法,重点关注LoRA和QLoRA技术,包括其背景、技术原理和具体实现。LoRA通过低秩分解减少参数量,QLoRA则在4-bit量化基础上实现高性能微调,两者在减少计算资源的同时,保持与全参数微调相当的性能。
近期,OpenAI发布了gpt-4 turbo,又一次刷新了人们对LLM的认识。同时,谷歌也不甘示弱,推出了最新的 Gemini 模型和"超级计算机",在多个领域展现了强大的实力。大模型的竞争激烈异常,我们不仅要关注这些科技巨头的最新动态,更应该学会如何微调这些大模型,在 AI 发展的浪潮中有自己的思考和探索。

上一篇我们讲了 LLM(大语言模型)的基础以及微调的意义,为了方便大家了解 LLM(大语言模型)开发和微调经验,熟悉 LLM 开发范式,吸引更多的开发和使用者参与到 LLM 开发应用中来,趣丸科技技术团队的算法专家们也结合实战总结了一些探索经验,形成系列科普文章。
本篇文章将从微调具体方法深入展开,并带领大家测评两种主要的微调方法特点。微调的方法包括Freeze、P-Tuning、LoRA 、AdaLoRA 、 QLoRA 等,本文奖将重点介绍LoRA 和QLoRA 方法,包括背景、技术原理、具体实现等详尽阐述,大家可以根据不同的应用需求和计算资源,选择到最合适自己的微调途径。
本文大纲
1. 微调的五大方法
2. 深度解析微调技术
• LoRA 方法
• QLoRA 方法
3. 微调的实战应用
微调的五大方法
1. Freeze 方法,即参数冻结,对原始模型部分参数进行冻结操作;
2. P-Tuning 方法,参考 ChatGLM 官方代码 ,是针对于大模型的 soft-prompt 方法;
3. LoRA 方法,的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练;
4. AdaLoRA 方法是对 LoRA 的一种改进,并根据重要性评分动态分配参数预算给权重矩阵;
5. QLoRA 方法,是使用一种新颖的高精度技术将预训练模型量化为 4 bit,并添加一小组可学习的低秩适配器权重。
1. LoRA 方法
背景
神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank)。
因此,论文的作者认为权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。
技术原理
LoRA (论文:https://arxiv.org/abs/2106.09685),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
在涉及到矩阵相乘的模块,在原始的 PLM 旁边增加一个新的通路,通过前后两个矩阵 A,B 相乘,第一个矩阵 A 负责降维,第二个矩阵 B 负责升维,中间层维度为 r,从而来模拟所谓的本征秩(intrinsic rank)。
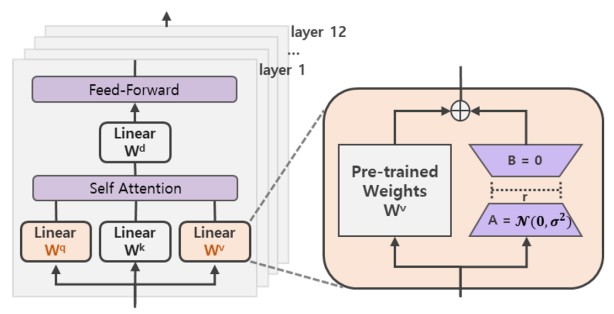
可训练层维度和预训练模型层维度一致为 d,先将维度 d 通过全连接层降维至 r,再从 r 通过全连接层映射回 d 维度,其中,r<<d,r 是矩阵的秩,这样矩阵计算就从 d x d 变为 d x r + r x d,参数量减少很多,计算过程更快。
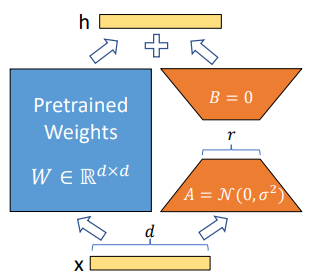
在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将 PLM 跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即 h=Wx+BAx。第一个矩阵的 A 的权重参数会通过高斯函数初始化,而第二个矩阵的 B 的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路 BA=0 从而对模型结果没有影响。
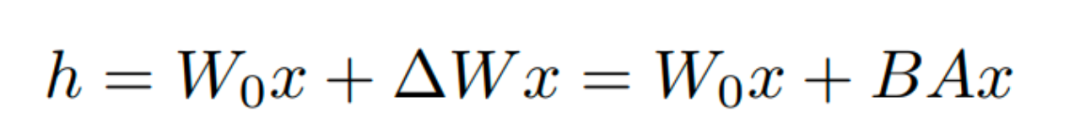
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积 BA 跟原本的权重矩阵 W 加到一起作为新权重参数替换原本 PLM 的 W 即可,对于推理来说,不会增加额外的计算资源。
此外,Transformer 的权重矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2013
2013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









