







论文作者:Yufu Wang,Yu Sun,Priyanka Patel,Kostas Daniilidis,Michael J. Black,Muhammed Kocabas
作者单位:Meshcapade ; MPI for Intelligent Systems; ETH Zurich ¨;University of Pennsylvania ;Archimedes
论文链接:http://arxiv.org/abs/2504.06397v1
内容简介:
1)方向:人体姿态与形状(HPS)
2)应用:人体姿态与形状(HPS)
3)背景:现有的人体姿态与形状估计方法往往缺乏有效机制来结合辅助的“侧信息”,从而提升在复杂场景下的重建精度。此外,最精确的方法通常依赖于裁剪后的人员检测,无法有效利用场景上下文,而处理全图像的方法虽然能够考虑场景信息,但往往难以准确检测人物,并且比使用裁剪图像的方法效果差。尽管最近的基于语言的方法尝试通过大规模的语言或视觉-语言模型进行HPS推理,但其度量精度远低于现有的最先进方法。
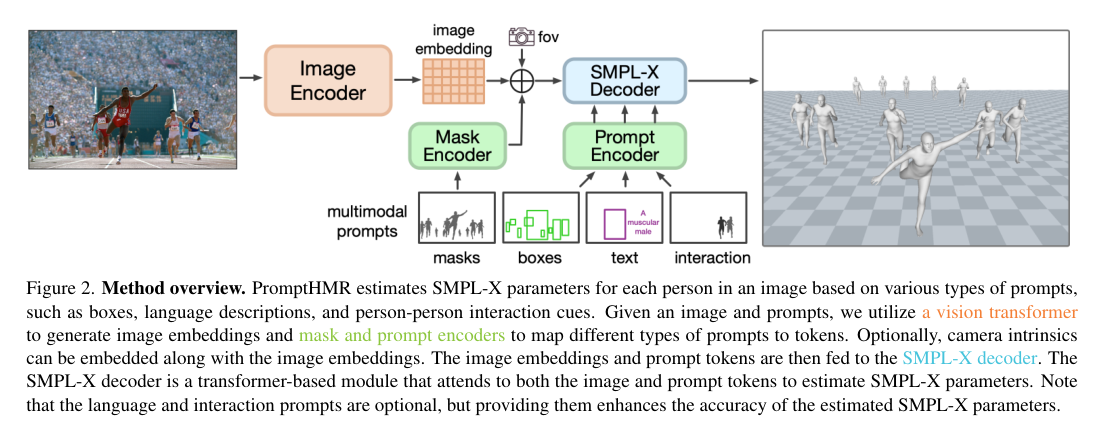
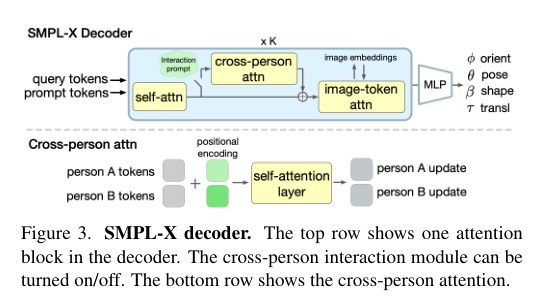
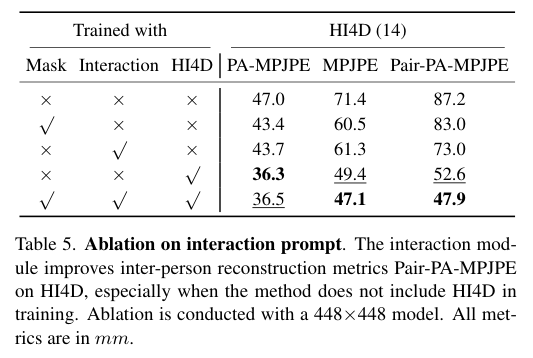
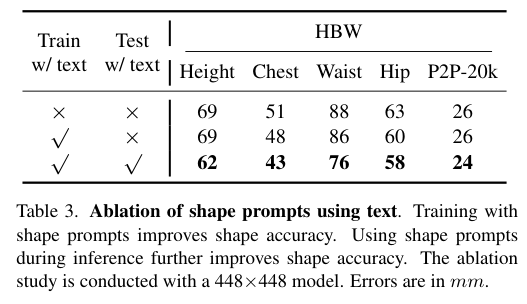
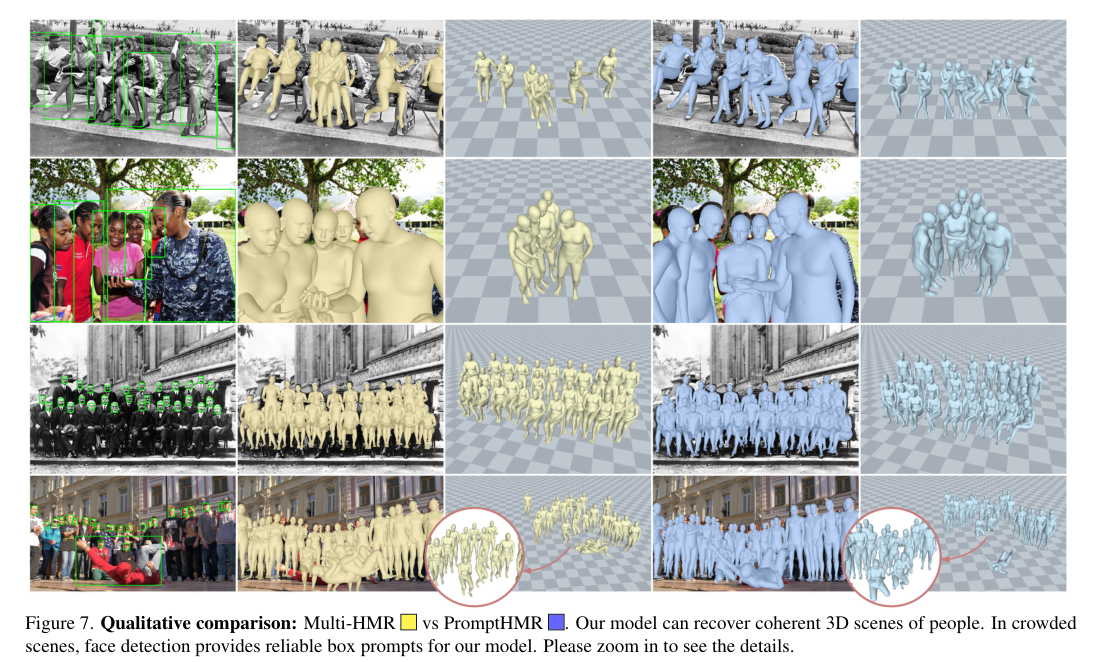
4)方法:本文提出了一种基于Transformer的可提示方法——PromptHMR,该方法通过空间和语义提示重新构建HPS估计过程。PromptHMR能够处理全图像,以保持场景上下文信息,并接受多种输入模态:如空间提示(边界框、掩码)和语义提示(语言描述或互动标签)。通过这些提示,模型在估计人体姿态和形状时能够更好地处理复杂的场景和交互信息。
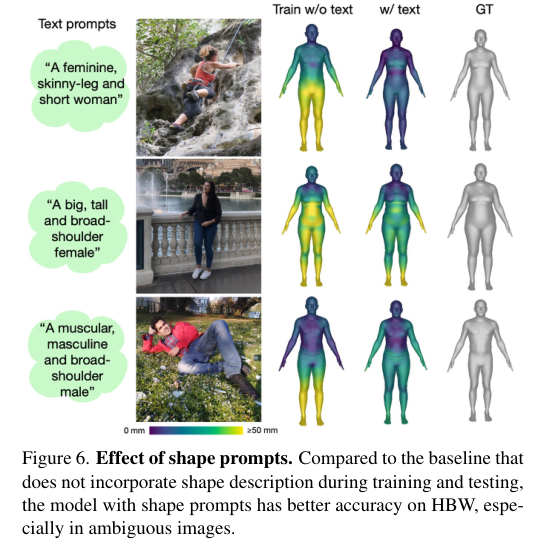
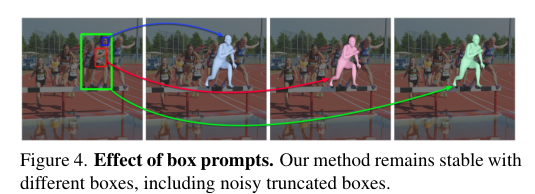
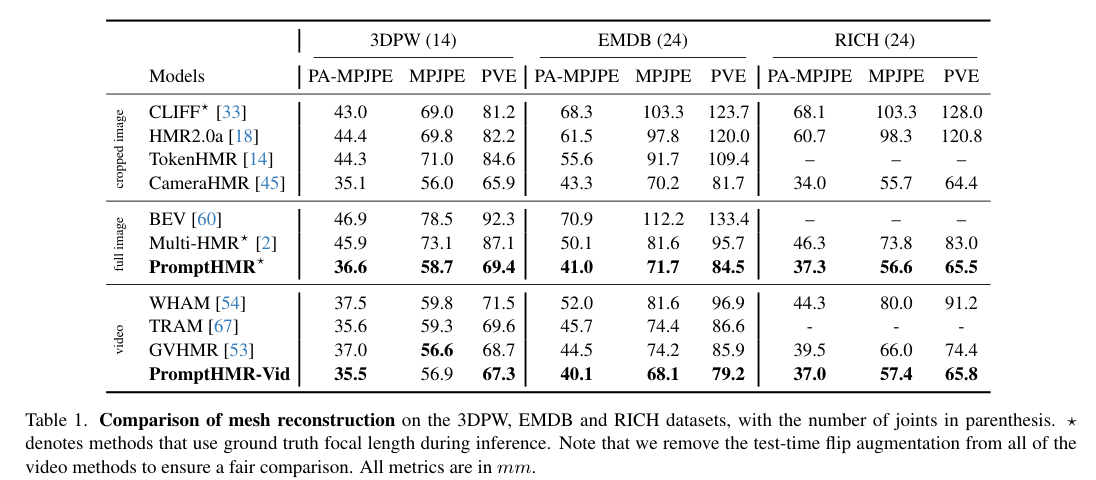
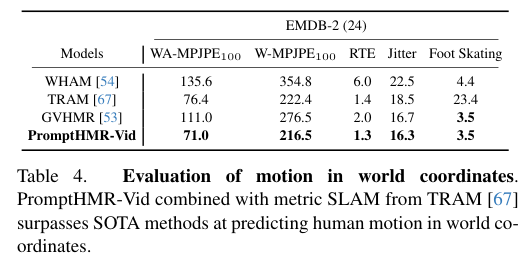
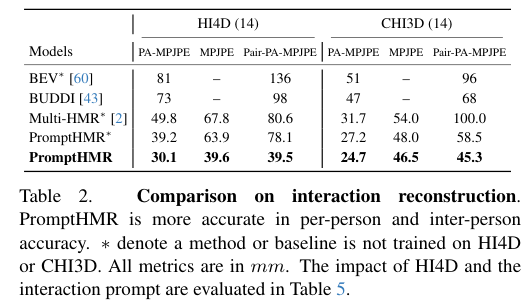
5)结果:在多个基准数据集上的实验表明,PromptHMR在各种挑战性场景中表现出色,能够准确估计从边界框(如拥挤场景中的人脸)中的人物,利用语言描述提高身体形状估计,建模人物之间的互动,并在视频中生成时间连贯的动作。PromptHMR达到了最先进的性能,同时提供了灵活的提示控制,能够有效改善HPS估计过程。























 2240
2240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











