






目录
Pandas是基于NumPy的模块,功能:数据的筛选清洗和处理,与NumPy模块相比更擅长处理二维数组。
两种数据结构:Series DataFrame
Series 序列(一维,带索引的数组对象)
 图自夜曲编程
图自夜曲编程
与字典不同,Series中数据有顺序,访问:①通过index ②通过0,1,2位置
(没有定义index,默认从0开始)
values可以是多种数据类型,但一个Series里的所有值数据类型一致。
1.传入列表
import pandas as pd
#作为索引的列表和作为值的列表元素个数要一致
GDP=[80855,77388,68024,47251,40471]
city=['GD','JS','SD','ZJ','HN']
#列表city赋值给index
#info 一个Series对象
info=pd.Series(GDP,index=city)
print(info)2.传入数组
import pandas as pd
import numpy as np
GDP=np.array([808,787,214,504,703])
rank=[1,2,3,4,5]
info=pd.Series(GDP,index=rank)
print(info)访问
1.位置索引访问 基于元素自身下标, info[0] 输出info第一个数据。
2.索引标签访问 info[ 'JS' ]
Series三种常用属性
1.dtype Series.dtype 返回 int64
2.values 会以数组形式返回变量info的值values
info.values 返回 [589 893 234 543 543]
3.index
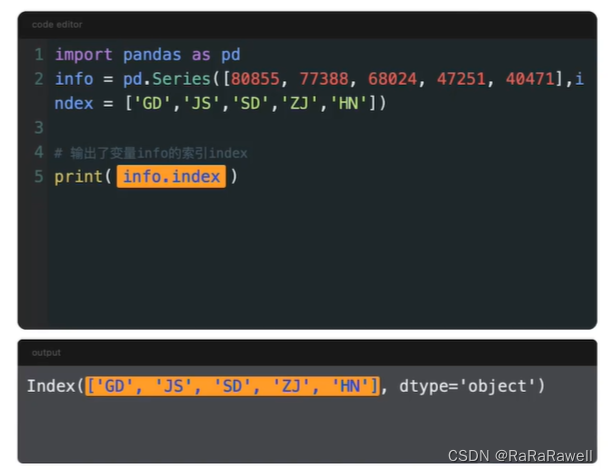
不是数组形式
DataFrame 数据框
常用的数据类型,一个二维的矩阵数据表,像一个表格,通过行和列可以定位一个值

同一列数据类型相同,列与列之间数据类型可以不同
没有定义index会从0开始生成
1.传入字典
import pandas as pd
data={'rank':[1,2,3,4],'GDP':[342,234,355,234]}
city=['GD','JS','SD','ZJ']
#字典的key是对象,成为列索引columns
#字典的values是对应的列表,成为值values
#index行索引
df=pd.DataFrame(data,index=city)
print(df)2.传入列表
import pandas as pd
#data是嵌套列表,没有自定义column,默认从0开始生成
data=[['Mary',678],['Tony',876],['Kevin',358]]
rank=[1,2,3]
result=pd.DataFrame(data,index=rank,columns=['name','score'])
print(result)3种常用属性
df.dtypes
df.values
df.index
DataFrame的轴axis
二维数组2个轴,三维3个
第0轴垂直向下,axis=0:垂直方向进行操作;第1轴水平向右,axis=1:水平方向进行操作
sum()函数用于对DataFrame中的数据进行求和,df.sum(axis=0),对垂直的方向上进行求和操作
df.sum(axis=1)水平上求和
mean()求平均数














 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









