







目录
一:Pandas简介
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据
Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具
Pandas 适用于处理以下类型的数据:
1 与 SQL 或 Excel 表类似的,含异构列的表格数据;
2 有序和无序(非固定频率)的时间序列数据;
3 带行列标签的矩阵数据,包括同构或异构型数据;
4 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记
安装:pip install pandas
二:Pandas数据结构
Series一维
DataFrame二维

Pandas 里,轴的概念主要是为了给数据赋予更直观的语义,即用“更恰当”的方式表示数据集的方向;这样做可以让用户编写数据转换函数时,少费点脑子
处理 DataFrame 等表格数据时,index(行)或 columns(列)比 axis 0 和 axis 1 更直观;用这种方式迭代 DataFrame 的列,代码更易读易懂:
for col in df.columns:
series = df[col]Pandas 基础数据结构,包括各类对象的数据类型、索引、轴标记、对齐等基础操作。首先,导入 NumPy 和 Pandas:
import numpy as np
import pandas as pdSeries 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引
调用 pd.Series 函数即可创建 Series,如下
s = pd.Series(data, index=index)上述代码中,data 支持以下数据类型:
Python 字典
多维数组
标量值(如,5)
三:Series
index 是轴标签列表。不同数据可分为以下几种情况:
data 是多维数组时,index 长度必须与 data 长度一致。没有指定 index 参数时,创建数值型索引,即 [0, ..., len(data) - 1]。
示例1,带标签的一维同构数组Series
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s)
输出结果 5行数据
a 1.558245
b 1.482427
c -1.041129
d 0.935235
e 1.587218
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s.index)
输出结果:
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
四:字典生成Series
Series 可以用字典实例化: 示例如下
import numpy as np
import pandas as pd
d = {'b': 1, 'a': 0, 'c': 2}
print(pd.Series(d))
输出结果:3个一维输出如下
b 1
a 0
c 2
dtype: int64
如果设置了 index 参数,则按索引标签提取 data 里对应的值
示例如下
import numpy as np
import pandas as pd
d = {'a': 0., 'b': 1., 'c': 2.}
print(pd.Series(d))
输出结果:
a 0.0
b 1.0
c 2.0
dtype: float64
如果设置了 index 参数,则按索引标签提取 data 里对应的值 还有如下示例
index索引可以重新定义,可以修改
import numpy as np
import pandas as pd
d = {'a': 0., 'b': 1., 'c': 2.}
print(pd.Series(d, index=['b', 'c', 'd', 'a']))
输出结果:重新定义index,行标重新去锁值,如d没有则NaN;c有对应2.0
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
五:标量值生成Series
data 是标量值时,必须提供索引
Series 按索引长度重复该标量值
import numpy as np
import pandas as pd
d = pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])
print(d)
输出结果:
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
六:Series类似多维数组
Series 操作与 ndarray 类似,支持大多数 NumPy 函数,还支持索引切片
下面给出8个示例
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s[0])
示例1 输出结果:
0.6853089253347693
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s[:3])
示例2 输出结果:
a -1.448139
b 2.037805
c 0.630593
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s[s > s.median()])
示例3 输出结果:
a 1.362318
d -0.145133
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s[[4, 3, 1]])
示例4 输出结果:
e 1.551956
d 0.412505
b 0.149695
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(np.exp(s))
示例5 输出结果
a 0.613578
b 1.145933
c 1.676388
d 1.804427
e 0.290707
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s.dtype) # Series 的数据类型一般是 NumPy 数据类型
示例6 输出结果
float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s.array)
示例7 print(s.array)输出结果 Series.array 用于提取 Series 数组
<PandasArray>
[ -1.0258449356655936, -0.1040740491851698, -0.371796402671782,
-0.15074588032048006, -0.6481135676408321]
Length: 5, dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
n = (s.to_numpy())
# Series 只是类似于多维数组,提取真正的多维数组,要用 Series.to_numpy()
print(n, type(n))
执行不用索引的操作时,如禁用自动对齐,访问数组非常有用
Series.array 一般是扩展数组。简单说,扩展数组是把 N 个 numpy.ndarray 包在一起的打包器
Pandas 知道怎么把扩展数组存储到 Series 或 DataFrame 的列里
示例8 print(s.to_numpy())输出结果: pandas的series一维结构转换为numpy的ndarray
[ 0.70064719 0.40663471 -1.39737931 2.15146709 0.18545255] <class 'numpy.ndarray'>
七:Series类似字典
Series 类似固定大小的字典,可以用索引标签提取值或设置值:
下面给出3个示例
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s['a'])
示例1 输出结果:
0.4074712729585669
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s['e'] = 12.
print(s)
示例2 输出结果:
a 0.018912
b 2.093037
c -0.002699
d -1.999814
e 12.000000
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print('e' in s)
print('f' in s)
示例3 输出结果:
True
False
引用 Series 里没有的标签会触发异常:
下面给出2个示例
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s['f'])
输出异常:KeyError: 'f'
使用get可以输出,如下
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s.get('f'))
s.get('f', np.nan)
使用get
可输出:None
八:矢量操作与对齐 Series 标签
Series 和 NumPy 数组一样,都不用循环每个值,而且 Series 支持大多数 NumPy 多维数组的方法
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s + s)
输出结果:
a 0.611183
b -0.967015
c 1.726425
d -3.766861
e 1.050546
dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
print(s * 2)
输出结果:
a 3.675656
b 3.903872
c 0.363479
d -2.589410
e -1.913055
dtype: float64
九:Series名称属性
Series 支持 name 属性
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), name='something')
print(s)
输出:
0 0.151475
1 0.609232
2 -0.223518
3 -1.029584
4 1.581806
Name: something, dtype: float64
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), name='something')
print(s.name)
输出:
something
import numpy as np
import pandas as pd
s = pd.Series(np.random.randn(5), name='something')
s2 = s.rename("different")
print(s2.name)
输出:
different
十:DataFrame
DataFrame 是由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典
DataFrame 是最常用的 Pandas 对象,与 Series 一样,DataFrame 支持多种类型的输入数据:
一维 ndarray、列表、字典、Series 字典
二维 numpy.ndarray
结构多维数组或记录多维数组
Series
DataFrame
除了数据,还可以有选择地传递 index(行标签)和 columns(列标签)参数
传递了索引或列,就可以确保生成的 DataFrame 里包含索引或列
Series 字典加上指定索引时,会丢弃与传递的索引不匹配的所有数据。
十一:用 Series 字典或字典生成 DataFrame
生成的索引是每个 Series 索引的并集。先把嵌套字典转换为 Series。如果没有指定列,DataFrame 的列就是字典键的有序列表。
import numpy as np
import pandas as pd
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df)
输出如下
index a b c d 行索引
one two 列索引
类似key-value
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0import numpy as np
import pandas as pd
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d, index=['d', 'b', 'a'])
print(df)输出如下
index d b a 行索引
one two 列索引
one two
d NaN 4.0
b 2.0 2.0
a 1.0 1.0import numpy as np
import pandas as pd
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
print(pd.DataFrame(d, index=['d', 'b', 'a'], columns=['two', 'three']))输出如下
index d b a 行索引
two three 列索引
two three
d 4.0 NaN
b 2.0 NaN
a 1.0 NaNimport numpy as np
import pandas as pd
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df.index)输入如下 Index dtype
Index(['a', 'b', 'c', 'd'], dtype='object')import numpy as np
import pandas as pd
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df.columns)
输出如下 Index dtype
Index(['one', 'two'], dtype='object')十二:用多维数组字典、列表字典生成 DataFrame
多维数组的长度必须相同。如果传递了索引参数,index 的长度必须与数组一致。如果没有传递索引参数,生成的结果是 range(n),n 为数组长度。
import numpy as np
import pandas as pd
d = {'one': [1., 2., 3., 4.],
'two': [4., 3., 2., 1.]}
print(pd.DataFrame(d))
输出如下
0 1 2 3 行索引
one two 列索引
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0import numpy as np
import pandas as pd
d = {'one': [1., 2., 3., 4.],
'two': [4., 3., 2., 1.]}
res = pd.DataFrame(d, index=['a', 'b', 'c', 'd'])
print(res)
输出如下
a b c d 行索引
one two 列索引
one two
a 1.0 4.0
b 2.0 3.0
c 3.0 2.0
d 4.0 1.0十三:用结构多维数组或记录多维数组生成 DataFrame
与数组字典的操作方式相同
import numpy as np
import pandas as pd
data = np.zeros((2, ), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')])
data[:] = [(1, 2., 'Hello'), (2, 3., "World")]
res = pd.DataFrame(data)
print(res)
输出如下
0 1 行
A B C 列
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'import numpy as np
import pandas as pd
data = np.zeros((2, ), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')])
data[:] = [(1, 2., 'Hello'), (2, 3., "World")]
res1 = pd.DataFrame(data, index=['first', 'second'])
print(res1)
输出如下
first second 行
A B C 列
A B C
first 1 2.0 b'Hello'
second 2 3.0 b'World'import numpy as np
import pandas as pd
data = np.zeros((2, ), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')])
data[:] = [(1, 2., 'Hello'), (2, 3., "World")]
res2 = pd.DataFrame(data, columns=['C', 'A', 'B'])
print(res2)
输出如下
0 1 行
C A B 列
C A B
0 b'Hello' 1 2.0
1 b'World' 2 3.0十四:用列表字典生成 DataFrame
与数组字典的操作方式相同
import numpy as np
import pandas as pd
data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
res = pd.DataFrame(data2)
print(res)
输出如下
0 1 行
a b c 列
a b c
0 1 2 NaN
1 5 10 20.0import numpy as np
import pandas as pd
data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
res1 = pd.DataFrame(data2, index=['first', 'second'])
print(res1)
输出如下
first second 行
a b c 列
a b c
first 1 2 NaN
second 5 10 20.0import numpy as np
import pandas as pd
data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
res2 = pd.DataFrame(data2, columns=['a', 'b'])
print(res2)
输出如下
0 1 行
a b 列
a b
0 1 2
1 5 10十五:用元组字典生成 DataFrame
元组字典可以自动创建多层索引 DataFrame
import numpy as np
import pandas as pd
res = pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
print(res)
输出如下
如 1.0
对应的行索引 A B
对应的列索引 a b
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0十六:用Series字典对象生成 DataFrame
import numpy as np
import pandas as pd
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2)
输出如下 这个示例重点了解下DataFrame
0 1 2 3 行
A B C D E F 列
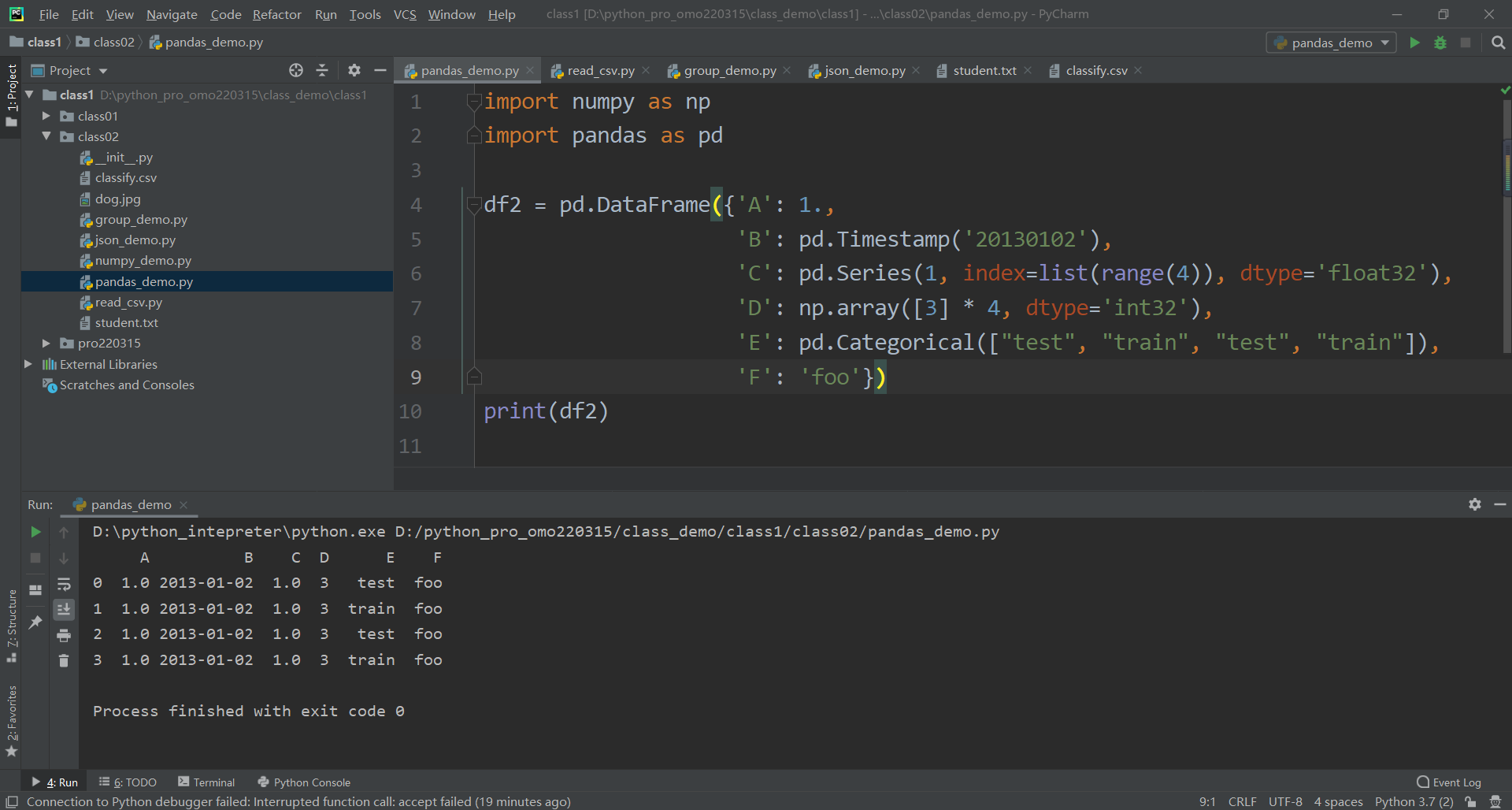
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train fooimport numpy as np
import pandas as pd
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2.dtypes)输出如下
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











