







文章目录
论文: Robust unsupervised audio-visual speech enhancement using a mixture of variational autoencoders
原文地址: VAE-AVSE. 本文是在阅读原文时的简要总结和记录。

Abstract
1. 动机
- 视听(audio-visual)语音增强比纯音频(audio_only)语音增强(SE)效果更好;
- 但在视觉信息不可靠时(e.g. 遮挡),AVSE模型并不鲁棒
2. 本文工作:基于混合VAE的AVSE模型。
- 混合模型包含两部分:trained audio_only VAE和trained audio-visual VAE
- 在遇到不可靠的视觉帧时,将AVSE模型切换至AOSE模型,以解决鲁棒性的问题。
- 通过变分EM方法(variational expectation-maximization)估计模型参数
Introduction
1. 已有基于VAE的纯音频语音增强(audio-only SE)
使用VAE对语音频谱进行建模,通过考虑NMF(nonnegative matrix factorization)噪声方差模型以无监督的方式进行语音增强。
2. 本文的前序工作:基于VAE的AVSE模型
AVSE将视觉信息(e.g lip video frames)与noisy speech一起输入模型,获得clean speech。论文 Audio-Visual Speech Enhancement Using Conditional Variational Auto-Encoders 将基于VAE的AOSE模型扩展为AVSE模型,证明了AVSE比AOSE性能要好,尤其是在信噪比较低时。
3. 现有AVSE模型的缺点:在不可靠的视觉信息时不鲁棒
视觉信息不可靠(e.g. 唇部遮挡)时AVSE模型可能比AOSE模型效果还差。
4. 本文的主要工作:使AVSE模型在视觉信息不可靠时也能拥有鲁棒性能
- 提出了VAE混合模型:trained AOSE & AVSE模型;
- 在视觉信息不可靠时,选择AOSE模型,跳过noisy video frames;
- 选择使用AOSE还是AVSE模型要以一种无监督的方式在每帧时都进行,因此提出了一种变分推断结构来解决此问题。
基于VAE的SE模型
1. 基于VAE的AOSE模型
令
s
f
n
s_{fn}
sfn表示复值STFT结果,其中
f
∈
{
0
,
…
,
F
−
1
}
f\in \{0,\dots,F-1\}
f∈{0,…,F−1}表示频率下标,
n
∈
{
0
,
…
,
N
−
1
}
n\in \{0,\dots,N-1\}
n∈{0,…,N−1}表示时间下标。在每一时频bin,有如下概率生成模型,即AOSE-VAE:
s
f
n
∣
z
n
∼
N
c
(
0
,
σ
f
a
(
z
n
)
)
,
s_{fn}|\bf{z_n} \sim \mathcal{N_c}(0, \sigma_f^a(\bf{z_n})),
sfn∣zn∼Nc(0,σfa(zn)),
z
n
∼
N
(
0
,
I
)
\bf{z_n} \sim \mathcal{N}(0, I)
zn∼N(0,I)
1).
z
n
∈
R
L
,
L
≪
F
\bf{z_n} \in \mathbb{R}^L, L \ll F
zn∈RL,L≪F,是隐随机变量;
2).
N
(
0
,
I
)
\mathcal{N}(0, I)
N(0,I)表示0均值单位方差的高斯分布;
3).
N
c
(
0
,
σ
)
\mathcal{N_c}(0, \sigma)
Nc(0,σ)表示具有0均值和
σ
\sigma
σ方差的单变量复值高斯分布;
4).
s
n
∈
C
F
\bf{s_n}\in\mathbb{C}^F
sn∈CF表示在第
n
n
n帧时的STFT;
5).
{
σ
f
a
:
R
L
→
R
+
}
f
=
0
F
−
1
\{\sigma_f^a: \mathbb{R}^L \rightarrow \mathbb{R}_+\}_{f=0}^{F-1}
{σfa:RL→R+}f=0F−1表示非线性函数,可以用神经网络建模,输入是
z
n
∈
R
L
\bf{z_n} \in \mathbb{R}^L
zn∈RL。
这些参数是通过定义另一个神经网络(称为编码器/推理网络)使用变分推理来估计的,该网络在给定bf{s_n}的情况下逼近\bf{z_n}的后验。
2. 基于VAE的AVSE模型
s
f
n
∣
z
n
,
v
n
∼
N
c
(
0
,
σ
f
a
v
(
z
n
,
v
n
)
)
,
s_{fn}|\bf{z_n, v_n} \sim \mathcal{N_c}(0, \sigma_f^{av}(\bf{z_n, v_n})),
sfn∣zn,vn∼Nc(0,σfav(zn,vn)),
z
l
n
∣
v
n
∼
N
(
μ
l
(
v
n
)
,
σ
l
(
v
n
)
)
z_{ln}|\bf{v_n} \sim \mathcal{N}(\mu_l(\bf{v_n}), \sigma_l(\bf{v_n}))
zln∣vn∼N(μl(vn),σl(vn))
1).
v
n
∈
R
M
\bf{v_n} \in \mathbb{R}^M
vn∈RM,表示第n帧时的lip embedding;
2).
{
σ
f
a
v
)
:
R
L
×
R
M
→
R
+
}
f
=
0
F
−
1
\{\sigma_f^{av}): \mathbb{R}^L\times \mathbb{R}^M \rightarrow \mathbb{R}_+\}_{f=0}^{F-1}
{σfav):RL×RM→R+}f=0F−1表示非线性函数,可以用神经网络建模,输入是
z
n
,
v
n
\bf{z_n, v_n}
zn,vn;
3).产生 zn 的先验的非线性函数
{
μ
l
:
R
M
→
R
}
l
=
0
L
−
1
\{\mu_l: \mathbb{R}^M \rightarrow \mathbb{R}\}_{l=0}^{L-1}
{μl:RM→R}l=0L−1和
{
σ
l
:
R
M
→
R
}
l
=
0
L
−
1
\{\sigma_l: \mathbb{R}^M \rightarrow \mathbb{R}\}_{l=0}^{L-1}
{σl:RM→R}l=0L−1是用一个以 \bf{v_n} 作为输入的神经网络建模的。
以类似于AOSE-VAE 的方式,定义编码器(Encoder)网络, 在给定
s
n
\bf{s_n}
sn和
v
n
\bf{v_n}
vn的情况下逼近
z
n
\bf{z_n}
zn的后验,再与解码器和先验联合训练。
VAE混合模型:提出了一种自动选择机制,为每一帧选择AOSE/AVSE
VAE混合模型(VAE-MM):

其中 α n \alpha_n αn是控制第n帧选择AO/AVSE的隐变量,由参数为 π \pi π的Bernoulli分布建模。
VAE-MM的训练与推断
带噪语音信号可以表示为
x
f
n
=
s
f
n
+
b
f
n
x_{fn}=s_{fn}+b_{fn}
xfn=sfn+bfn,其中噪声信号
b
f
n
∼
N
c
(
0
,
(
W
b
H
b
)
f
n
)
b_{fn}\sim\mathcal{N}_c(0, (\bf{W}_b\bf{H}_b)_{fn})
bfn∼Nc(0,(WbHb)fn),即前述NMF噪声模型。其中
W
b
∈
R
F
×
K
\bf{W}_b\in\mathbb{R}^{F\times K}
Wb∈RF×K是一个半正定矩阵,表示频谱功率模式;
H
b
∈
R
K
×
N
\bf{H}_b\in\mathbb{R}^{K\times N}
Hb∈RK×N也是半正定矩阵,表示时域激活,
K
(
F
+
N
)
≪
F
N
K(F+N)\ll FN
K(F+N)≪FN。
待估计参数可以写作
Θ
=
{
W
b
,
H
b
,
π
}
\Theta=\{\bf{W}_b, \bf{H}_b, \pi\}
Θ={Wb,Hb,π},使用变分期望最大化(Variational Expectation Maximization, VEM)方法来估计这些参数。后验分布可以如下近似:
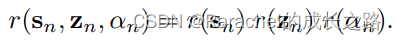
其中的变分因子可以通过最小化其与真实后验分布的KL散度来估计。
这一节主要是给出了EM算法的推导结果,就不罗列在此了。主要思想是先求
s
n
,
z
n
,
α
n
\bf{s}_n, \bf{z}_n, \alpha_n
sn,zn,αn的期望,在通过最大似然更新参数。















 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









