







 本文介绍了如何使用LeNet模型训练和测试MNIST数据集,详细讲解了从数据层、卷积层、池化层、全连接层到损失层的网络结构,并提供了相应的prototxt配置文件解析。还涵盖了MNIST Solver的定义,包括训练迭代、学习率策略等关键参数。最后,给出了训练模型的命令行操作指导。
本文介绍了如何使用LeNet模型训练和测试MNIST数据集,详细讲解了从数据层、卷积层、池化层、全连接层到损失层的网络结构,并提供了相应的prototxt配置文件解析。还涵盖了MNIST Solver的定义,包括训练迭代、学习率策略等关键参数。最后,给出了训练模型的命令行操作指导。
1. 数据集准备
详细信息见: Caffe: LMDB 及其数据转换
mnist是一个手写数字库,由DL大牛Yan LeCun进行维护。mnist最初用于支票上的手写数字识别, 现在成了DL的入门练习库。征对mnist识别的专门模型是Lenet,算是最早的cnn模型了。
mnist数据训练样本为60000张,测试样本为10000张,每个样本为28*28大小的黑白图片,手写数字为0-9,因此分为10类。
1)数据可以从MNIST官网上下载)
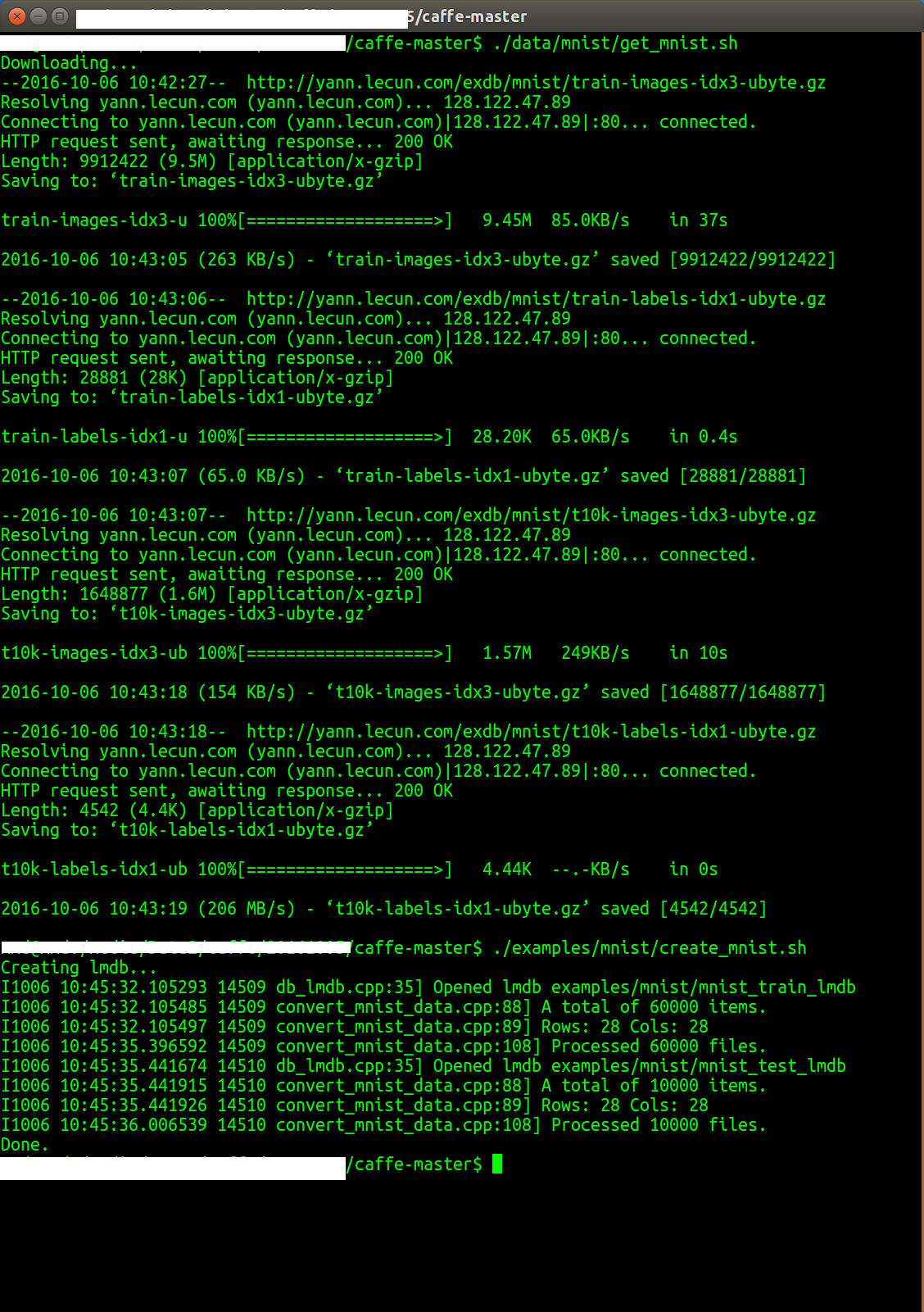
2)或者执行如下命令
$CAFFE_ROOT表示源代码的根目录
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh
运行成功后,在 data/mnist/目录下有四个文件:
train-images-idx3-ubyte: 训练集样本 (9912422 bytes)
train-labels-idx1-ubyte: 训练集对应标注 (28881 bytes)
t10k-images-idx3-ubyte: 测试集图片 (1648877 bytes)
t10k-labels-idx1-ubyte: 测试集对应标注 (4542 bytes)
这些数据不能在caffe中直接使用,需要转换成LMDB数据
./examples/mnist/create_mnist.sh
2.LeNet: MNIST 分类模型的训练和测试
2.1 LeNet分类模型
使用LeNet模型网络来训练,是数字识别的好模型。The design of LeNet contains the essence of CNNs that are still used in larger models such as the ones in ImageNet. In general, it consists of a convolutional layer followed by a pooling layer, another convolution layer followed by a pooling layer, and then two fully connected layers similar to the conventional multilayer perceptrons. We have defined the layers in `$CAFFE_ROOT/examples/mnist/lenet_train_test.prototxt`.
2.2 MNIST网络结构定义
此处解释MNIST手写数字识别LeNet模型的定义 `lenet_train_test.prototxt`,Caffe中使用的protobuf 定义在 `$CAFFE_ROOT/src/caffe/proto/caffe.proto`中.接下来将会写一个protobuf定义:`caffe::NetParameter` (或者Python形式, `caffe.proto.caffe_pb2.NetParameter`) .
开始,先定义一个网络名字:
name: "LeNet"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









