






笔记目录
对鲁棒泛化的研究已经发展了相当长的一段时间,作为提高鲁棒泛化的经典算法,Generalist获得CVPR 2023 (Highlight, Top 2.5%),从个人兴趣出发,我对本文的算法做了一些简单的分析。
Generalist是一个使用两个base learner的集成学习框架,是一个用于训练深度神经网络分类器的算法,旨在解决自然泛化和鲁棒泛化之间的权衡问题。
该算法的目标是通过解耦自然泛化和鲁棒泛化,同时训练两个专注于不同任务的基础学习器,并利用全局学习者聚合它们的学习成果,从而在保持高自然准确性的同时提高模型对抗性样本的鲁棒性。通过这种方式,算法旨在在自然和对抗性环境中实现更好的性能平衡。
核心算法

f(·):一个具有初始可学习参数 θg 的DNN分类器,用于全局学习者。
θn 和 θr:每个基础学习的初始可学习参数,分别用于自然数据和对抗数据。
ℓ1 和 ℓ2:自然和对抗设置的目标函数。
T:迭代次数。
K:对抗攻击步骤数。
ε:扰动幅度。
κ:步长。
τn 和 τr:自然和对抗训练的学习率。
α’:指数衰减率,用于指数移动平均(EMA)。
γ:混合比例,用于组合基础学习者的参数。
t’ 和 c:通信的起始点和频率。
Q&A
需要探索的问题Q
1 小批量样本minibatch(x,y)是怎么定义的?
2 for下的第一行公式是什么意思,E代表什么意思
3 为什么模型集成(model ensembling)在for内要执行两次?
4 输出的参数global learner θg是什么意思?
5 为什么攻击要用sign符号函数
6 为什么要使用frequency of communication t’
7 使用自然数据更新学习参数所用到的模型集成、数据增强或标签平滑等操作具体指的是什么?
8 为什么生成对抗样本时只要生成x’不用生成y’
对问题的解答A
问题1
x:通常是一个二维数组或张量,其中每一行代表一个训练样本的特征。这些特征可以是图像的像素值、文本数据的词嵌入向量等。
y:一个一维数组或张量,包含与 x 中每个样本对应的标签。在监督学习中,这些标签是模型需要学习预测的目标。
修改:这个小批量样本mini batch xy,但其实x的它的shape其实不一定是一个二维的速度或者脏量,因因为我们在这里的话。x一般是图片,那么图片它其实是有四个,四个维度,就对x而言,然后第一个维度是这样一个小match,它的样本的数量,然后。第二个维度是图片的通道,也一般都是三,然后第三个维度的话,第四个维度分别指的是图片的长和宽,所以说这里的话X它的dimension是四而不是二。
问题2
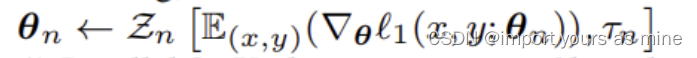
想要理解这一公式,首先得知道l1,l2是表示loss的意思,也就是机器学习中的损失。故E内部表示的是损失的梯度,而E表示的是其期望。
整个表达式的意思是,在第 t 步,我们使用自然分类任务的优化器 Zn,根据从数据集 D1 中抽取的样本 (x, y) 的损失函数梯度来更新基础学习器 θn 的参数。这个更新过程考虑了所有可能的样本 (x, y),并计算了它们的梯度的平均值(期望值),然后使用这个平均梯度和学习率 τ1 来调整参数 θt n。
Zn的含义已在前文定义过了。
问题3
更新基础学习器1(Base Learner1)在处理自然数据集(D1)时,模型集成可以用来平滑模型的输出,减少过拟合,并提高对自然样本的分类准确性。这通常通过在训练过程中对模型的不同版本进行平均或者加权平均来实现。
更新基础学习器2(Base Learner2)在处理对抗性数据集(D2)时,模型集成同样可以提高模型对对抗性攻击的鲁棒性。通过对在对抗性训练过程中生成的多个模型的预测进行集成,可以使得最终的模型更加稳定,减少对抗性样本对模型性能的影响。
在每次迭代中,全局学习器(Global Learner)会收集这两个基础学习器的参数,并通过指数移动平均(Exponential Moving Average, EMA)的方式更新自己的参数。这样,全局学习器能够融合两个专门化学习器的知识,从而在测试时既能处理自然样本,也能对抗对抗性样本。
问题4
初始学习参数θg是全局学习参数,由基础学习参数θn,θr构成,由代码上的倒数第二个迭代公式我们可以知道θg是他们的加权平均迭代而成的。
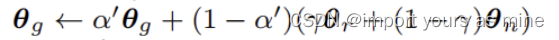
问题5
使攻击的力度加大。
修改:问题五成理解的不太对,就是这里的sign的意思是因为可能你得去了解一下attack就pd attack它其实是因为是无穷分数棒棒的,所以说。通过泰勒展开,然后它的sign,这个方向是使它的loss最快就最快上升的一个方向,所以说这这地方必须要去sign,我一会儿,哎,我记得我给你发的那个。视频里面应该那个goodfellow它是有讲解的,对,就是因为泰勒展开,所以说它的方向是最大的。
问题6
个人认为是base learner学一段时间后再复制给global learner,从而减少迭代次数和学习时间。
修改:问题六的话,他这里是其实第一个是节省时间吧,就是你不说一直在河边来河边去的,其实对于时间也是有消耗的,然后第二个其实其实我们最希望是统计一下历史的他的学习。他的一个学习的参数就是,如果你你每隔一个iteration就更新一次,合并一次的话,可能可能它的抖动会比较大。
问题7
模型集成(Model Ensembling):
模型集成是一种提高模型泛化能力的技术,它通过结合多个模型的预测结果来生成最终的输出。这些模型可以是完全相同的模型但具有不同的初始化权重,或者是不同的模型架构。集成方法可以是简单的平均(对于回归问题)或投票(对于分类问题),也可以是更复杂的加权平均或基于学习的方法。模型集成可以减少模型的方差,提高对未见数据的预测准确性。
数据增强(Data Augmentation):
数据增强是一种通过对原始数据进行变换来增加数据多样性的技术。这些变换可以包括旋转、缩放、裁剪、颜色变换、添加噪声等。数据增强的目的是模拟不同的输入条件,使模型能够学习到更加鲁棒的特征表示,从而提高模型对新数据的泛化能力。在图像识别任务中,数据增强尤其有效,因为它可以帮助模型抵抗输入数据的小变化。
标签平滑(Label Smoothing):
标签平滑是一种正则化技术,用于防止模型对特定的类别过度自信。在标签平滑中,对于每个样本,其真实类别的标签不再是一个one-hot编码(即只有一个位置为1,其余位置为0),而是将这个位置的值降低(例如从1降低到0.9),并将其余位置的值从0提升到一个很小的正数(例如从0提升到0.01/类别数)。这样,模型就不太可能对某个类别产生极端的预测,而是学会更加平衡地看待所有类别。标签平滑有助于减少模型的过拟合,提高其泛化能力。
这三个技术的目的都是为了使模型对微笑的输入更鲁棒。
问题8
y是标签,标签不需要有对抗的标签。(生成对抗标签是一个好像是个好思路,不知有没有人研究过)
修改:对,就是我们说的对称样本,其实是这样的,但是其实你是得X加一些噪声,然后改变它的输出,就这些输出本身本身是不动的,就是因为你加的噪声,噪声很小嘛。你人这么去看,它还是就是原来是一张猫的图片,然后你加装上之后,它还是一张猫的图片,所以说它的标签其实是不动的。
代码实现
既然伪代码已经了解的差不多了,可以具体了解一下真代码。(代码可从github上获得)
train函数
Algorithm 1 的具体实现,对train每一行做了解读
def train(epoch, model, model_st, teacher_at, teacher_st, teacher_mixed, Attackers, optimizer_ST, optimizer_AT, device, descrip_str):
teacher_at.model.eval()
teacher_st.model.eval()
teacher_mixed.model.eval()
首先是对每个参数的解释:
epoch: 表示当前的训练周期序号。每个epoch包含整个训练数据集的一次完整迭代。
model: 用于训练的原始模型。在对抗性训练的上下文中,这个模型可能会被用来生成对抗性样本。
model_st: 这是一个模型的副本,通常用于生成干净的(未受攻击的)样本,以进行模型的自然误差率(natural error rate)的评估。
teacher_at: 使用了指数移动平均(EMA)的模型,model的EMA,用于生成更稳健的对抗性样本。
teacher_st: 另一个使用EMA的模型,通常用于生成干净的样本,model_st的EMA。
teacher_mixed: 结合了对抗性训练和自然训练的模型,使用来自teacher_at和teacher_st的信息。
Attackers: 一个攻击对象,用于生成对抗性样本。它实现了多种对抗性攻击算法,可以在训练过程中对模型的鲁棒性进行测试。
optimizer_ST: 这是用于优化model_st(学生模型)的优化器。优化器负责根据损失函数的结果更新模型的权重。
optimizer_AT: 这是用于优化model(对抗性模型)的优化器。
device: 表示模型和数据应该运行在的设备,CPU或GPU。
descrip_str: 这是一个字符串,用于描述当前训练过程的状态,显示当前的epoch、损失、准确率等信息,以便于监控训练进度。
在函数内部,首先将所有的教师模型设置为评估模式(.eval())。这是非常重要的一步,因为在评估模式下,模型不会跟踪梯度(即不会计算反向传播),这有助于防止在模型评估或测试时的意外更新。此外,这也确保了模型中的某些层(如Dropout层和Batch Normalization层)在训练和评估时表现一致。
losses = AverageMeter()
clean_accuracy = AverageMeter()
adv_accuracy = AverageMeter()
pbar = tqdm(train_loader)
pbar.set_description(descrip_str)
tqdm 是一个快速、可扩展的进度条工具,它可以提供在控制台中的进度条显示,使得长时间运行的任务能够给用户一个进度的反馈。descrip_str 是一个字符串变量,可能包含了关于当前训练过程的描述信息,例如训练的模型类型、当前的epoch数等。这行代码将这个描述信息设置到 tqdm 进度条上,以便知道进度条表示的具体内容。
for batch_idx, (inputs, target) in enumerate(pbar):
pbar_dic = OrderedDict()
获取数据:在每次循环迭代开始时,创建一个新的 OrderedDict 实例可以确保在处理每个批次之前,字典被重置为一个空的状态。这样做是必要的,因为希望为每个批次独立地收集指标,然后将它们平均以得到整个数据集的性能评估。
inputs, target = inputs.to(device), target.to(device)
# 这两行代码将输入数据 inputs 和目标 target 移动到指定的设备 device 上。这是必要的步
# 骤,因为深度学习模型通常在特定的硬件设备(如GPU)上运行,以加速计算。.to(device) 方法
# 确保数据张量在正确的设备上,以便模型可以对其进行操作
# loss, logit = trades_loss(model, inputs, target, optimizer, epoch, step_size=0.003, epsilon=0.031, perturb_steps=10, beta=6.0, distance='l_inf', device='device')
# loss, logit = mart_loss(model, inputs, target, optimizer, epoch, step_size=0.003, epsilon=0.031, perturb_steps=10, beta=6.0, distance='l_inf', device='device')
x_adv, _ = Attackers.run_specified('PGD_10', model, inputs, target, return_acc=False)
# For AT update
model.train()
lr = adjust_learning_rate(epoch)
optimizer_AT.param_groups[0].update(lr=lr)
optimizer_AT.zero_grad()
logit = model(x_adv)
model.train() 将模型设置为训练模式。
adjust_learning_rate 根据当前的 epoch(训练周期)动态调整学习率 lr。
optimizer_AT.param_groups[0] 访问参数组列表中的第一个元素,这是模型的所有参数。
在每次反向传播之前,需要将模型参数的梯度清零。这是因为默认情况下,梯度是累加的,如果不清零,那么每次的梯度计算将会包含之前所有迭代的梯度和,这会导致错误的权重更新。optimizer_AT.zero_grad() 正是执行了这个操作,确保每次反向传播只计算当前批次的梯度。
x_adv由attackers.run_specified()生成,只在这里用到了,生成logic,即对抗样本对应的值。
loss_at = nn.CrossEntropyLoss()(logit, target)
loss_at.backward()
optimizer_AT.step()
机器学习的标准步骤,logic接力,算loss,bp回退,最后使用优化器来跟新模型参数。以上九行代码都是对对抗模型AT进行训练的过程。
teacher_at.update_params(model)
teacher_at.apply_shadow()
使用指数移动平均(Exponential Moving Average, EMA)来更新模型参数:第一行代码调用了 EMA 类的 update_params 方法,它用于更新 teacher_at 实例的内部状态,即它的“影子”参数(shadow parameters)
第二行代码将 teacher_at 的模型参数临时替换为其影子参数。这意味着在接下来的操作中,teacher_at 模型将使用这些平滑后的参数进行推理或评估,而不是使用训练过程中实时更新的参数。这通常用于生成更稳健的模型,因为 EMA 参数通常在训练过程中逐渐变化,不太可能因单个训练步骤而产生剧烈波动。
补充:EMA有效的原因:普通的参数权重相当于一直累积更新整个训练过程的梯度,使用EMA的参数权重相当于使用训练过程梯度的加权平均(刚开始的梯度权值很小)。由于刚开始训练不稳定,得到的梯度给更小的权值更为合理,所以EMA会有效。
# For ST update
model_st.train()
optimizer_ST.param_groups[0].update(lr=lr)
optimizer_ST.zero_grad()
nat_logit = model_st(inputs)
loss_st = nn.CrossEntropyLoss()(nat_logit, target)
loss_st.backward()
optimizer_ST.step()
teacher_st.update_params(model_st)
teacher_st.apply_shadow()
这九行代码与上一个九行的代码功能一样,不同的是使用model_st是未受对抗攻击的数据训练的。
beta = adjust_beta(epoch)
bata是混合模型对两个模型应用的两个模型的比率,adjust_bata的定义为:adjust_beta = lambda t: np.interp([t], [0, args.epochs // 3, args.epochs * 2 // 3, args.epochs], [1.0, 1.0, 1.0, 0.4])[0]
表示比率随训练轮数从1下降到0.4,之后回具体解释一下beta
teacher_mixed.update_params(teacher_at.model, teacher_st.model, beta=beta)
teacher_mixed.apply_shadow()
我的理解是这一步是算法鲁棒的关键,相当于把两个EMA过的model不仅结合在一起了,还又EMA了一遍。这应该是Generalist的核心技术。
在这里看一下update_params的源码:
def update_params(self, model, model2=None, beta=None):
decay = min(self.alpha, (self.step + 1) / (self.step + 10))
state = model.state_dict()
for i, name in enumerate(self.param_keys):
if model2 and beta:
if i < len(self.param_keys):
state2 = model2.state_dict()
self.shadow[name].copy_(decay * self.shadow[name] + (1 - decay) * (state[name] * beta + state2[name] * (1-beta)))
else:
self.shadow[name].copy_(decay * self.shadow[name] + (1 - decay) * state[name])
for i, name in enumerate(self.buffer_keys):
if self.buffer_ema:
if model2 and beta:
if i < len(self.buffer_keys):
state2 = model2.state_dict()
self.shadow[name].copy_(decay * self.shadow[name] + (1 - decay) * (state[name] * beta + state2[name] * (1-beta)))
else:
self.shadow[name].copy_(decay * self.shadow[name] + (1 - decay) * state[name])
else:
self.shadow[name].copy_(state[name])
self.step += 1
看到这里才知道,原来beta的作用是让在不同轮数,生成混合模型的对抗训练模型和标准训练模型混合的比例不同。beta一开始是1,最后是0.4,表示一开始全是对抗训练的加权,后来是标准训练的加权占比0.6,这样训练听起来就非常合理。
if epoch >= 75 and epoch % 5 == 0:
model.load_state_dict(teacher_mixed.shadow)
model_st.load_state_dict(teacher_mixed.shadow)
超过75次epoch之后,每五次epoch将 model 和model_st的参数加载为 teacher_mixed.shadow 中的参数。这意味着在75次训练之后,model和model_st数据的差距不会超过五次训练,model的结果由model_st的加权,model_st的结果有model的加权,二者不是相互割裂的。
losses.update(loss_at.item())
clean_accuracy.update(torch_accuracy(teacher_st.model(inputs), target, (1,))[0].item())
adv_accuracy.update(torch_accuracy(teacher_at.model(inputs), target, (1,))[0].item())
pbar_dic['loss'] = '{:.2f}'.format(losses.mean)
pbar_dic['Acc'] = '{:.2f}'.format(clean_accuracy.mean)
pbar_dic['advAcc'] = '{:.2f}'.format(adv_accuracy.mean)
pbar.set_postfix(pbar_dic)
随着epoch不断迭代,更新普通模型和鲁棒模型的准确度,至此train代码结束。
test函数
def test(model, model_st, Attackers, device):
model.eval()
model_st.eval()
clean_accuracy = AverageMeter()
adv_accuracy = AverageMeter()
ema_clean_accuracy = AverageMeter()
ema_adv_accuracy = AverageMeter()
clean_accuracy:模型在未受攻击(即原始、未添加扰动)的测试数据上的准确率。
adv_accuracy:模型在受到对抗性攻击的测试数据上的准确率。
ema_clean_accuracy:使用指数移动平均(Exponential Moving Average, EMA)参数的模型在未受攻击的测试数据上的准确率。
ema_adv_accuracy:使用EMA参数的模型在受到对抗性攻击的测试数据上的准确率。
pbar = tqdm(test_loader)# 使用tqdm库来创建一个进度条,它将显示每个epoch中处理的批次数量。test_loader是一个PyTorch数据加载器,它按批次提供数据。
pbar.set_description('Testing') #设置进度条的描述文本为'Testing',这样在运行测试时,控制台输出的进度条前会显示这个描述。
for batch_idx, (inputs, target) in enumerate(pbar):
pbar_dic = OrderedDict()
inputs, target = inputs.to(device), target.to(device)
acc = Attackers.run_specified('NAT', model, inputs, target, return_acc=True)
adv_acc = Attackers.run_specified('PGD_20', model, inputs, target, category='Madry', return_acc=True)
ema_acc = Attackers.run_specified('NAT', model_st, inputs, target, return_acc=True)
ema_adv_acc = Attackers.run_specified('PGD_20', model_st, inputs, target, category='Madry', return_acc=True)
clean_accuracy.update(acc[0].item())
adv_accuracy.update(adv_acc[0].item())
ema_clean_accuracy.update(ema_acc[0].item())
ema_adv_accuracy.update(ema_adv_acc[0].item())
pbar_dic['cleanAcc'] = '{:.2f}'.format(clean_accuracy.mean)
pbar_dic['advAcc'] = '{:.2f}'.format(adv_accuracy.mean)
pbar_dic['ema_cleanAcc'] = '{:.2f}'.format(ema_clean_accuracy.mean)
pbar_dic['ema_advAcc'] = '{:.2f}'.format(ema_adv_accuracy.mean)
pbar.set_postfix(pbar_dic)
return clean_accuracy.mean, adv_accuracy.mean, ema_clean_accuracy.mean, ema_adv_accuracy.mean
attack函数
def attack(model, Attackers, device):
model.eval()
clean_accuracy = AverageMeter()
pgd20_accuracy = AverageMeter()
pgd100_accuracy = AverageMeter()
mim_accuracy = AverageMeter()
cw_accuracy = AverageMeter()
APGD_ce_accuracy = AverageMeter()
APGD_dlr_accuracy = AverageMeter()
APGD_t_accuracy = AverageMeter()
FAB_t_accuracy = AverageMeter()
Square_accuracy = AverageMeter()
aa_accuracy = AverageMeter()
pbar = tqdm(test_loader)
pbar.set_description('Attacking all')
for batch_idx, (inputs, targets) in enumerate(pbar):
pbar_dic = OrderedDict()
inputs, targets = inputs.to(device), targets.to(device)
acc_dict = Attackers.run_all(model, inputs, targets)
clean_accuracy.update(acc_dict['NAT'][0].item())
pgd20_accuracy.update(acc_dict['PGD_20'][0].item())
pgd100_accuracy.update(acc_dict['PGD_100'][0].item())
mim_accuracy.update(acc_dict['MIM'][0].item())
cw_accuracy.update(acc_dict['CW'][0].item())
APGD_ce_accuracy.update(acc_dict['APGD_ce'][0].item())
APGD_dlr_accuracy.update(acc_dict['APGD_dlr'][0].item())
APGD_t_accuracy.update(acc_dict['APGD_t'][0].item())
FAB_t_accuracy.update(acc_dict['FAB_t'][0].item())
Square_accuracy.update(acc_dict['Square'][0].item())
aa_accuracy.update(acc_dict['AA'][0].item())
pbar_dic['clean'] = '{:.2f}'.format(clean_accuracy.mean)
pbar_dic['PGD20'] = '{:.2f}'.format(pgd20_accuracy.mean)
pbar_dic['PGD100'] = '{:.2f}'.format(pgd100_accuracy.mean)
pbar_dic['MIM'] = '{:.2f}'.format(mim_accuracy.mean)
pbar_dic['CW'] = '{:.2f}'.format(cw_accuracy.mean)
pbar_dic['APGD_ce'] = '{:.2f}'.format(APGD_ce_accuracy.mean)
pbar_dic['APGD_dlr'] = '{:.2f}'.format(APGD_dlr_accuracy.mean)
pbar_dic['APGD_t'] = '{:.2f}'.format(APGD_t_accuracy.mean)
pbar_dic['FAB_t'] = '{:.2f}'.format(FAB_t_accuracy.mean)
pbar_dic['Square'] = '{:.2f}'.format(Square_accuracy.mean)
pbar_dic['AA'] = '{:.2f}'.format(aa_accuracy.mean)
pbar.set_postfix(pbar_dic)
return [clean_accuracy.mean, pgd20_accuracy.mean, pgd100_accuracy.mean, mim_accuracy.mean, cw_accuracy.mean, APGD_ce_accuracy.mean, APGD_dlr_accuracy.mean, APGD_t_accuracy.mean, FAB_t_accuracy.mean, Square_accuracy.mean, aa_accuracy.mean]
main函数
def main():
best_ema_acc_adv = 0
start_epoch = 1
if args.arch == "smallcnn":
model = SmallCNN()
if args.arch == "resnet18":
model = ResNet18(num_classes=args.num_classes)
if args.arch == "preactresnet18":
model = PreActResNet18(num_classes=args.num_classes)
if args.arch == "WRN32":
model = Wide_ResNet_Madry(depth=32, num_classes=args.num_classes, widen_factor=10, dropRate=0.0)
由先前的代码可知,默认选择的模型是resnet18
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_at = torch.nn.DataParallel(model)
model_st = copy.deepcopy(model_at)
teacher_at = EMA(model_at)
teacher_st = EMA(model_st)
teacher_mixed = EMA(model_st)
# model_at = model_at.to(device)
Attackers = AttackerPolymer(args.epsilon, args.num_steps, args.step_size, args.num_classes, args.norm, device)
logger_test = Logger(os.path.join(args.out_dir, 'log_results.txt'), title='reweight')
if not args.resume:
optimizer_ST = optim.SGD(model_st.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
optimizer_AT = optim.SGD(model_at.parameters(), lr=args.lr, momentum=0.9, weight_decay=weight_decay)
logger_test.set_names(['Epoch', 'Natural', 'PGD20', 'ema_Natural', 'ema_PGD20'])
for epoch in range(start_epoch, args.epochs+1):
descrip_str = 'Training epoch:{}/{}'.format(epoch, args.epochs)
# start_time = time.time()
train(epoch, model_at, model_st, teacher_at, teacher_st, teacher_mixed, Attackers, optimizer_ST, optimizer_AT, device, descrip_str)
# elapsed = round(time.time() - start_time)
# elapsed = str(datetime.timedelta(seconds=elapsed))
# print(elapsed)
nat_acc, pgd20_acc, ema_nat_acc, ema_pgd20_acc = test(teacher_st.model, teacher_mixed.model, Attackers, device=device)
logger_test.append([epoch, nat_acc, pgd20_acc, ema_nat_acc, ema_pgd20_acc])
if ema_nat_acc >= 88 and ema_nat_acc + ema_pgd20_acc > best_ema_acc_adv:
print('==> Updating the teacher model_at..')
best_ema_acc_adv = ema_nat_acc + ema_pgd20_acc
torch.save(teacher_mixed.model.state_dict(), os.path.join(args.out_dir, 'ema_bestpoint.pth.tar'))
# Save the last checkpoint
torch.save(model_at.state_dict(), os.path.join(args.out_dir, 'lastpoint.pth.tar'))
# model_at.load_state_dict(torch.load(os.path.join(args.out_dir, 'bestpoint.pth.tar')))
teacher_mixed.model.load_state_dict(torch.load(os.path.join(args.out_dir, 'ema_bestpoint.pth.tar')))
res_list1 = attack(teacher_mixed.model, Attackers, device)
teacher_mixed.model.load_state_dict(torch.load(os.path.join(args.out_dir, 'lastpoint.pth.tar')))
res_list2 = attack(teacher_mixed.model, Attackers, device)
logger_test.set_names(['Epoch', 'clean', 'PGD20', 'PGD100', 'MIM', 'CW', 'APGD_ce', 'APGD_dlr', 'APGD_t', 'FAB_t', 'Square', 'AA'])
logger_test.append([1000000, res_list1[0], res_list1[1], res_list1[2], res_list1[3], res_list1[4], res_list1[5], res_list1[6], res_list1[7], res_list1[8], res_list1[9], res_list1[10]])
logger_test.append([1000001, res_list2[0], res_list2[1], res_list2[2], res_list2[3], res_list2[4], res_list2[5], res_list2[6], res_list2[7], res_list2[8], res_list2[9], res_list2[10]])
logger_test.close()
模型训练与代码调试过程
首先,创建miniconda环境
export PATH=/home/zmwei/anaconda3/bin:$PATH
conda create -n project_01 python=3.7 numpy torch torchvision cuda
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch
下载cifar-10数据集
创建项目环境,并cd到项目的目录下
运行python3 main.py
输出结果报错:
Files already downloaded and verified
Files already downloaded and verified
Traceback (most recent call last):
File "main.py", line 344, in <module>
main()
File "main.py", line 299, in main
Attackers = AttackerPolymer(args.epsilon, args.num_steps, args.step_size, args.num_classes, args.norm, device)
TypeError: __init__() takes 6 positional arguments but 7 were given
第299行的参数数量出了问题
于是我再attacks.py的第18行加了个norm
24行加了个self.norm = norm
175行吧norm=‘linf’改成self.norm
疑似解决
重新开始训练,在执行到第一个epoch时报错,报错原因是
Traceback (most recent call last):
File "main.py", line 344, in <module>
main()
File "main.py", line 313, in main
train(epoch, model_at, model_st, teacher_at, teacher_st, teacher_mixed, Attackers, optimizer_ST, optimizer_AT, device, descrip_str)
File "main.py", line 141, in train
x_adv, _ = Attackers.run_specified('PGD_10', model, inputs, target, return_acc=False)
ValueError: too many values to unpack (expected 2)
这个错误信息表明在尝试解包 Attackers.run_specified 方法的返回值时出现了问题。具体来说,run_specified 方法返回的值比预期的多,而代码尝试将这些返回值解包到两个变量 x_adv 和 _ 中。
把_换成stepcount仍然报错
result = Attackers.run_specified('PGD_10', model, inputs, target, return_acc=False)
print(result)
加入这两行调试
根据提供的打印结果,Attackers.run_specified 方法返回的是一个四维的PyTorch张量(tensor)。这个张量是一系列图像数据,为对抗性样本的图像特征。
张量的具体内容是一系列数值,这些数值被组织成多个三维数组。每个三维数组可能代表一个图像的像素值或其他相关数据。张量中的每个数字代表张量中该位置的数值。
由于返回值是一个张量而不是一个包含多个返回值的元组或列表,所以当你尝试使用如下方式解包返回值时:
x_adv, _ = Attackers.run_specified(‘PGD_10’, model, inputs, target, return_acc=False)
会出现错误,因为这里期望 run_specified 返回两个值,但实际上它只返回了一个张量。
为了解决这个问题,应该只将张量赋值给一个变量,如下所示:
x_adv = Attackers.run_specified(‘PGD_10’, model, inputs, target, return_acc=False)
这样,x_adv 将包含 run_specified 方法返回的张量,而不会有解包错误。如果 run_specified 方法的实现确实只设计为返回一个值,那么上述修改是正确的。如果它应该返回额外的信息(例如,一个包含张量和其他数据的元组),那么需要检查 run_specified 的实现,并相应地调整调用代码。
事实表明,原代码在使用PGD作为max时,上述操作时正确的。
if 'PGD' in name:
num_steps = int(name.split('_')[-1])
return self.PGD(model, img, gt, num_steps=num_steps, category=category, step_count=step_count, return_acc=return_acc)
attacks.py, 46-48行获取参数的方法蛮不错的。
模型训练能够初步进行,但是运行速度较慢,原因是没在GPU上运行,
测试cuda是否能使用
>>> import torch
>>> torch.cuda.is_available()
False
return false ,原因是nvcc的环境变量没配置
解决方案:编辑 shell 配置文件:根据你使用的 shell 类型,编辑相应的配置文件。对于大多数Linux系统,默认的 shell 是 bash,可以编辑 ~/.bashrc 文件。打开终端并使用文本编辑器,如 nano 或 vim:
nano ~/.bashrc
或者
vim ~/.bashrc
添加环境变量:在 ~/.bashrc 文件的末尾添加以下行,将 /usr/local/cuda- 替换为 nvcc 的实际安装路径:
export PATH=/usr/local/cuda-<version>/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-<version>/lib64:$LD_LIBRARY_PATH
例如,你的CUDA版本是11.3,那么路径应该是
export PATH=/usr/local/cuda-11.3/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH
然后保存并关闭文件,如果你使用的是 nano,可以按 Ctrl+X 然后按 Y 确认保存更改并退出。如果你使用的是 vim,可以按 Esc,然后输入 :wq 并按 Enter 保存并退出。
为了让更改生效,你需要运行以下命令来重新加载 ~/.bashrc 文件:
source ~/.bashrc
或者你可以关闭并重新打开你的终端。之后,通过运行以下命令来验证 nvcc 是否已正确添加到 PATH:
echo $PATH
你能在输出中看到 /usr/local/cuda-/bin。最后,再次运行以下命令来验证 nvcc 是否安装成功:
nvcc --version
成功安装,执行:
import torch
print(torch.cuda.is_available()) # 应该返回True,如果支持CUDA
print(torch.cuda.device_count()) # 返回你的GPU数量
print(torch.version.cuda) # 返回PyTorch支持的CUDA版本
很遗憾的是,print(torch.version.cuda) 中输出的是12.1。但是我的cuda版本貌似是11.3,所以以下是重装torch。
因为服务器使用的cuda为12.2,而目前(2024年4月22日)pytoch所支持cuda的最高版本是12.1,本来想对cuda降级,被告知支持cuda11.3的pytoch1.8.1也可以兼容cuda12.2,尝试之后兼容成功。
运行代码,继续报错:
Traceback (most recent call last):
File "main.py", line 344, in <module>
main()
File "main.py", line 313, in main
train(epoch, model_at, model_st, teacher_at, teacher_st, teacher_mixed, Attackers, optimizer_ST, optimizer_AT, device, descrip_str)
File "main.py", line 141, in train
x_adv = Attackers.run_specified('PGD_10', model, inputs, target, return_acc=False)# tyx删除了一个解包返回值
File "/home/yxtian/Generalist/Generalist-main/attacks.py", line 48, in run_specified
return self.PGD(model, img, gt, num_steps=num_steps, category=category, step_count=step_count, return_acc=return_acc)
File "/home/yxtian/Generalist/Generalist-main/attacks.py", line 81, in PGD
output = model(x_adv)
File "/data0/yxtian/envs/project_01/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/data0/yxtian/envs/project_01/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 155, in forward
"them on device: {}".format(self.src_device_obj, t.device))
RuntimeError: module must have its parameters and buffers on device cuda:0 (device_ids[0]) but found one of them on device: cpu
错误信息指出模型期望其参数和缓冲区位于cuda:0(即第一个GPU)上,但实际上至少有一个参数或缓冲区被发现在CPU上.
试着使用.to(device)确保模型被移动到正确的设备上
继续报错:
/data0/yxtian/envs/project_01/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py:30: UserWarning:
There is an imbalance between your GPUs. You may want to exclude GPU 4 which
has less than 75% of the memory or cores of GPU 0. You can do so by setting
the device_ids argument to DataParallel, or by setting the CUDA_VISIBLE_DEVICES
environment variable.
warnings.warn(imbalance_warn.format(device_ids[min_pos], device_ids[max_pos]))
Training epoch:1/120: 0%| | 0/391 [00:57<?, ?it/s]
Traceback (most recent call last):
File "main.py", line 346, in <module>
main()
File "main.py", line 315, in main
train(epoch, model_at, model_st, teacher_at, teacher_st, teacher_mixed, Attackers, optimizer_ST, optimizer_AT, device, descrip_str)
File "main.py", line 141, in train
x_adv = Attackers.run_specified('PGD_10', model, inputs, target, return_acc=False)# tyx删除了一个解包返回值
File "/home/yxtian/Generalist/Generalist-main/attacks.py", line 48, in run_specified
return self.PGD(model, img, gt, num_steps=num_steps, category=category, step_count=step_count, return_acc=return_acc)
File "/home/yxtian/Generalist/Generalist-main/attacks.py", line 86, in PGD
loss_adv.backward()
File "/data0/yxtian/envs/project_01/lib/python3.7/site-packages/torch/tensor.py", line 245, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/data0/yxtian/envs/project_01/lib/python3.7/site-packages/torch/autograd/__init__.py", line 147, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
You can try to repro this exception using the following code snippet. If that doesn't trigger the error, please include your original repro script when reporting this issue.
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.allow_tf32 = True
data = torch.randn([16, 512, 4, 4], dtype=torch.float, device='cuda', requires_grad=True)
net = torch.nn.Conv2d(512, 512, kernel_size=[3, 3], padding=[1, 1], stride=[1, 1], dilation=[1, 1], groups=1)
net = net.cuda().float()
out = net(data)
out.backward(torch.randn_like(out))
torch.cuda.synchronize()
ConvolutionParams
data_type = CUDNN_DATA_FLOAT
padding = [1, 1, 0]
stride = [1, 1, 0]
dilation = [1, 1, 0]
groups = 1
deterministic = true
allow_tf32 = true
input: TensorDescriptor 0x7f4eb98d29b0
type = CUDNN_DATA_FLOAT
nbDims = 4
dimA = 16, 512, 4, 4,
strideA = 8192, 16, 4, 1,
output: TensorDescriptor 0x7f4fbd1009b0
type = CUDNN_DATA_FLOAT
nbDims = 4
dimA = 16, 512, 4, 4,
strideA = 8192, 16, 4, 1,
weight: FilterDescriptor 0x7f4fbc5f6f20
type = CUDNN_DATA_FLOAT
tensor_format = CUDNN_TENSOR_NCHW
nbDims = 4
dimA = 512, 512, 3, 3,
Pointer addresses:
input: 0x7f4f38280000
output: 0x7f4f38380000
weight: 0x7f5101400000
Additional pointer addresses:
grad_output: 0x7f4f38380000
grad_weight: 0x7f5101400000
Backward filter algorithm: 1
试试把torch.backends.cudnn.deterministic改为false,但是并没有影响结果。
最后尝试外部解决方案,用命令行在包内以这种形式启动程序:
CUDA_VISIBLE_DEVICES=0,1 python main.py
成功运行,说明直接跑python程序指定cpu是最方便的方法
在实际运行时,如果一次指定5,6,7,8多个GPU,会在test的环节报错cuDNN,但是只指定一个CPU就不会,原因暂未知晓。
模型结果的测试
由于使用的是screen虚拟机,在打开的时候很多关键信息没有留存,只剩
weight: 0x7f836f000000
grad_output: 0x7f836f180000
grad_weight: 0x7f836f000000
Backward filter algorithm: 5
在main函数中,语句 logger_test.set_names([‘Epoch’, ‘Natural’, ‘PGD20’, ‘ema_Natural’, ‘ema_PGD20’])
会在循环结束的测试时记录以下的准确数值,在120次的epoch后,在"/Generalist/Generalist-main/logs/log_results.txt"记录的每次输出的log如下:
Epoch Natural PGD20 ema_Natural ema_PGD20
1.000000 66.584256 2.363528 42.840190 29.173259
2.000000 77.432753 0.316456 47.577136 31.991693
3.000000 82.416930 0.039557 50.870253 34.246440
4.000000 84.285997 0.029668 53.777690 36.234177
5.000000 85.828718 0.009889 56.477453 37.500000
6.000000 87.005538 0.000000 59.266218 39.428402
7.000000 87.954905 0.000000 61.382516 40.892009
8.000000 88.330696 0.000000 62.984573 42.019383
9.000000 88.765823 0.000000 63.854826 42.701741
10.000000 89.369066 0.000000 64.299842 43.463212
11.000000 89.952532 0.000000 64.121835 43.908228
12.000000 90.259098 0.009889 64.517405 44.452136
13.000000 90.684335 0.000000 64.378956 44.541139
14.000000 90.812896 0.000000 64.102057 44.204905
15.000000 91.238133 0.000000 63.350475 43.888449
16.000000 91.495253 0.000000 62.549446 43.186313
17.000000 91.673259 0.000000 61.639636 42.464399
18.000000 91.871044 0.000000 60.017801 41.435918
19.000000 91.791930 0.000000 58.959652 40.555775
20.000000 91.910601 0.000000 58.623418 40.199763
21.000000 92.197389 0.000000 58.791535 40.308544
22.000000 92.217168 0.000000 59.681566 41.070016
23.000000 92.454509 0.000000 61.056171 42.207278
24.000000 92.484177 0.000000 62.678006 43.651108
25.000000 92.711630 0.000000 64.903085 45.282832
26.000000 92.840190 0.000000 67.207278 47.270570
27.000000 93.028085 0.000000 69.392801 48.467168
28.000000 93.077532 0.000000 70.905854 49.713212
29.000000 92.988528 0.000000 72.438687 50.593354
30.000000 93.196203 0.000000 73.556171 51.414161
31.000000 93.304984 0.000000 74.643987 51.770174
32.000000 93.037975 0.000000 75.415348 52.136076
33.000000 93.037975 0.000000 76.028481 52.343750
34.000000 93.028085 0.000000 76.592168 52.581092
35.000000 93.206092 0.000000 77.047073 52.798655
36.000000 93.166535 0.000000 77.403085 52.798655
37.000000 93.225870 0.000000 77.828323 52.897547
38.000000 93.146756 0.000000 78.125000 52.956883
39.000000 93.334652 0.000000 78.411788 52.966772
40.000000 93.324763 0.000000 78.540348 53.194225
41.000000 93.433544 0.000000 78.550237 53.184335
42.000000 93.542326 0.000000 78.639241 53.253560
43.000000 93.532437 0.000000 78.866693 53.253560
44.000000 93.482991 0.000000 79.084256 53.431566
45.000000 93.364320 0.000000 79.262263 53.401899
46.000000 93.482991 0.000000 79.539161 53.540348
47.000000 93.562104 0.000000 79.638054 53.629351
48.000000 93.631329 0.000000 79.845728 53.609573
49.000000 93.502769 0.000000 80.092959 53.827136
50.000000 93.680775 0.000000 80.379747 53.955696
51.000000 93.730222 0.000000 80.518196 54.015032
52.000000 93.769778 0.000000 80.646756 54.133703
53.000000 93.670886 0.000000 80.706092 54.113924
54.000000 93.710443 0.000000 80.696203 54.291930
55.000000 93.868671 0.000000 80.893987 54.282041
56.000000 93.680775 0.000000 81.101661 54.450158
57.000000 93.809335 0.000000 81.358782 54.351266
58.000000 93.779668 0.000000 81.576345 54.262263
59.000000 93.878560 0.000000 81.803797 54.430380
60.000000 93.898339 0.000000 81.922468 54.499604
61.000000 93.839003 0.000000 82.130142 54.657832
62.000000 93.928006 0.000000 82.397152 54.736946
63.000000 93.868671 0.000000 82.693829 54.885285
64.000000 93.858782 0.000000 82.763054 54.865506
65.000000 93.819225 0.000000 82.921282 54.974288
66.000000 93.848892 0.000000 83.049842 55.073180
67.000000 93.858782 0.000000 83.208070 55.092959
68.000000 93.789557 0.000000 83.316851 55.172073
69.000000 93.839003 0.000000 83.573972 54.984177
70.000000 93.928006 0.000000 83.613528 54.895174
71.000000 94.007120 0.000000 83.781646 55.033623
72.000000 94.076345 0.000000 83.939873 55.092959
73.000000 94.086234 0.000000 84.117880 55.043513
74.000000 94.066456 0.000000 84.177215 55.053402
75.000000 10.096915 10.096915 84.404668 55.003956
76.000000 10.096915 10.096915 84.572785 54.934731
77.000000 10.096915 10.096915 84.760680 54.727057
78.000000 10.096915 10.096915 84.859573 54.756725
79.000000 10.096915 10.096915 84.899130 54.578718
80.000000 10.096915 10.096915 85.027690 54.519383
81.000000 10.096915 10.096915 83.415744 54.934731
82.000000 10.096915 10.096915 81.062104 54.479826
83.000000 10.096915 10.096915 78.738133 53.134889
84.000000 10.096915 10.096915 77.403085 52.066851
85.000000 10.096915 10.096915 76.295491 51.315269
86.000000 10.096915 10.096915 76.305380 51.196598
87.000000 11.234177 10.116693 77.828323 51.789953
88.000000 34.117880 17.405063 79.717168 52.640427
89.000000 64.220728 28.678797 81.121440 53.233782
90.000000 73.556171 39.843750 82.486155 53.441456
91.000000 83.425633 44.659810 83.524525 53.698576
92.000000 87.826345 42.800633 84.256329 53.639241
93.000000 90.268987 38.973497 85.166139 53.372231
94.000000 91.218354 35.096915 85.878165 53.085443
95.000000 90.308544 43.028085 86.451741 52.877769
96.000000 90.634889 42.840190 86.738528 52.709652
97.000000 91.168908 39.992089 87.114320 52.442642
98.000000 91.495253 36.342959 87.420886 51.878956
99.000000 91.693038 33.662975 87.717563 51.503165
100.000000 90.931566 40.822785 87.935127 51.157041
101.000000 90.921677 41.089794 88.063687 50.791139
102.000000 91.267801 38.390032 88.182358 50.435127
103.000000 91.485364 35.808940 88.370253 49.950554
104.000000 91.683149 33.376187 88.518592 49.535206
105.000000 91.020570 39.982199 88.706487 49.159415
106.000000 91.020570 40.427215 88.775712 48.941851
107.000000 91.248022 38.508703 88.904272 48.704509
108.000000 91.505142 36.382516 88.973497 48.457278
109.000000 91.554589 33.959652 89.072389 48.091377
110.000000 91.079905 39.309731 89.161392 47.676028
111.000000 91.030459 40.219541 89.191060 47.596915
112.000000 91.218354 38.686709 89.220728 47.329905
113.000000 91.307358 36.639636 89.171282 46.934335
114.000000 91.426028 34.889241 89.339399 46.479430
115.000000 90.990902 39.388845 89.369066 46.044304
116.000000 90.832674 40.446994 89.428402 45.886076
117.000000 90.901899 39.299842 89.438291 45.925633
118.000000 90.981013 38.034019 89.477848 45.609177
119.000000 91.129351 36.778085 89.606408 45.401503
120.000000 90.753560 39.952532 89.665744 45.045491
在同目录下,我们有了两个模型数据文件"ema_bestpoint.pth.tar"和"lastpoint.pth.tar",在深度学习中,.pth.tar 文件通常是模型的参数文件,它们包含了模型的权重和优化器状态等信息。这些文件通常由 PyTorch 框架生成,可以用于加载训练好的模型或者恢复训练过程。那么如何使用这两个文件做我们想要的测试呢?
main.py的第318行是main函数中唯一调用test()函数的模块,可以从这里入手。
nat_acc, pgd20_acc, ema_nat_acc, ema_pgd20_acc = test(teacher_st.model, teacher_mixed.model, Attackers, device=device)
第一个目标:按照论文的格式输出无穷范数攻击的测试结果(原论文数据)
操作方法:直接运行程序即可,程序会运行到 model_at.load_state_dict(torch.load(os.path.join(args.out_dir, ‘bestpoint.pth.tar’)))这句话,因为数据集找不到停止测试。
第二个目标:按照论文的格式输出2-范数攻击的测试结果
操作方法:注释掉main函数里的for loop,并修改到训练集的模型目录下,运行。
第三个目标:改由(l2+NT)训练Generalist,输出其无穷范数及2-范数攻击的测试结果
修改main函数中调用train的norm参数为l2即可,
训练该模型的log:
Epoch PGD20_inf PGD20_l2 ema_PGD20_linL ema_PGD20_l2
16.000000 91.940269 30.963212 79.766614 69.521361
17.000000 91.900712 30.290744 78.846915 68.621440
18.000000 92.197389 30.290744 78.204114 68.334652
19.000000 92.236946 29.776503 78.194225 68.344541
20.000000 92.365506 29.499604 78.876582 69.195016
21.000000 92.434731 28.955696 80.468750 70.638845
22.000000 92.602848 28.787579 82.041139 72.409019
23.000000 92.632516 28.579905 83.781646 73.961630
24.000000 92.770965 28.154668 85.176028 75.573576
25.000000 92.820411 27.917326 86.372627 77.086630
26.000000 92.820411 27.472310 87.321994 78.035997
27.000000 92.998418 27.304193 88.142801 78.767801
28.000000 92.998418 27.274525 88.647152 79.094146
29.000000 93.156646 27.027294 89.240506 79.608386
30.000000 93.314873 26.730617 89.507516 79.924842
31.000000 93.285206 26.789953 89.794304 80.290744
32.000000 93.245649 26.799842 90.001978 80.399525
33.000000 93.285206 26.562500 90.209652 80.567642
34.000000 93.285206 26.691060 90.328323 80.617089
35.000000 93.384098 26.819620 90.427215 80.696203
36.000000 93.502769 26.503165 90.575554 80.706092
37.000000 93.571994 26.127373 90.684335 80.824763
38.000000 93.512658 25.979035 90.783228 81.151108
39.000000 93.730222 26.127373 90.852453 81.210443
40.000000 93.641218 25.959256 90.971123 81.259889
41.000000 93.829114 25.662579 91.089794 81.388449
42.000000 93.690665 25.613133 91.198576 81.398339
43.000000 93.660997 25.257120 91.228244 81.457674
44.000000 93.621440 24.930775 91.198576 81.467563
45.000000 93.651108 25.593354 91.277690 81.615902
46.000000 93.759889 25.593354 91.406250 81.645570
47.000000 93.779668 25.207674 91.435918 81.625791
48.000000 93.819225 25.178006 91.604035 81.724684
49.000000 93.829114 25.286788 91.722706 81.912579
50.000000 93.967563 25.346123 91.772152 81.942247
51.000000 93.928006 25.197785 91.851266 81.902690
52.000000 93.888449 25.227453 91.979826 82.011472
53.000000 94.076345 25.652690 92.049051 82.149921
54.000000 93.987342 25.267009 92.187500 82.318038
55.000000 93.888449 25.286788 92.236946 82.436709
56.000000 93.977453 25.128560 92.197389 82.555380
57.000000 94.017009 25.197785 92.345728 82.436709
58.000000 94.026899 25.306566 92.454509 82.654272
59.000000 94.106013 25.385680 92.513845 82.782832
60.000000 94.086234 25.405459 92.672073 82.713608
61.000000 94.135680 25.692247 92.790744 82.525712
62.000000 94.115902 26.097706 92.780854 82.654272
63.000000 94.155459 25.850475 92.711630 82.634494
64.000000 94.254351 26.246044 92.711630 82.674051
65.000000 94.195016 26.424051 92.691851 82.723497
66.000000 94.096123 26.443829 92.711630 82.832278
67.000000 94.086234 26.572389 92.711630 82.753165
68.000000 94.066456 26.780063 92.711630 82.763054
69.000000 94.007120 26.789953 92.741297 82.713608
70.000000 93.957674 26.997627 92.780854 82.743275
71.000000 93.967563 27.155854 92.810522 82.594937
72.000000 93.878560 27.373418 92.859968 82.614715
73.000000 93.957674 27.412975 92.879747 82.585047
74.000000 93.898339 27.759098 92.859968 82.604826
75.000000 10.096915 10.096915 92.840190 82.565269
76.000000 10.096915 10.096915 92.840190 82.525712
77.000000 10.096915 10.096915 92.850079 82.535601
78.000000 10.096915 10.096915 92.869858 82.407041
79.000000 10.096915 10.096915 92.909415 82.367484
80.000000 10.096915 10.096915 92.879747 82.357595
81.000000 10.096915 10.096915 92.691851 82.219146
82.000000 10.096915 10.096915 92.335839 82.001582
83.000000 10.096915 10.096915 91.841377 81.873022
84.000000 10.096915 10.096915 91.702927 81.526899
85.000000 10.749604 10.383703 91.475475 81.259889
86.000000 29.341377 23.180380 91.475475 81.190665
87.000000 65.664557 53.619462 91.613924 81.408228
88.000000 82.120253 70.559731 91.752373 81.536788
89.000000 88.746044 77.442642 91.920491 81.566456
90.000000 90.516218 79.380934 92.088608 81.685127
91.000000 91.574367 80.933544 92.187500 81.724684
92.000000 92.454509 81.250000 92.325949 81.803797
93.000000 92.879747 81.240111 92.513845 81.724684
94.000000 93.087421 81.042326 92.622627 81.744462
95.000000 92.939082 81.348892 92.662184 81.764241
96.000000 92.899525 81.368671 92.731408 81.645570
97.000000 92.958861 81.101661 92.761076 81.625791
98.000000 92.998418 81.091772 92.780854 81.447785
99.000000 93.067642 81.012658 92.810522 81.546677
100.000000 92.978639 81.141218 92.820411 81.388449
101.000000 92.988528 81.200554 92.850079 81.497231
102.000000 93.057753 81.220332 92.830301 81.358782
103.000000 93.067642 81.022547 92.840190 81.358782
104.000000 93.107199 80.933544 92.830301 81.339003
105.000000 93.047864 81.279668 92.850079 81.289557
106.000000 92.948972 81.081883 92.889636 81.319225
107.000000 93.008307 81.141218 92.869858 81.240111
108.000000 93.018196 81.042326 92.850079 81.269778
109.000000 93.067642 81.012658 92.780854 81.210443
110.000000 92.968750 81.131329 92.830301 81.200554
111.000000 92.919304 81.200554 92.840190 81.151108
112.000000 92.929193 81.022547 92.869858 81.151108
113.000000 92.869858 80.933544 92.840190 81.200554
114.000000 92.879747 81.012658 92.800633 81.190665
115.000000 92.889636 80.933544 92.810522 81.071994
116.000000 92.899525 81.012658 92.830301 81.032437
117.000000 92.850079 80.973101 92.810522 81.190665
118.000000 92.840190 80.933544 92.761076 81.052215
119.000000 92.850079 81.002769 92.770965 80.992880
120.000000 92.830301 81.052215 92.780854 81.022547
参考网站
[1] 苏剑林. (Mar. 01, 2020). 《对抗训练浅谈:意义、方法和思考(附Keras实现) 》[Blog post]. Retrieved from https://kexue.fm/archives/7234
[2] 【Shell 命令集合 系统管理 】Linux 终端复用工具 screen命令 使用指南https://blog.csdn.net/qq_21438461/article/details/131441286
[3] 【CUDA_VISIBLE_DEVICES作用】http://t.csdnimg.cn/KByyp
[4] AT训练总榜 https://robustbench.github.io/
[5] 【argparse简介】如何再命令行配置训练参数:https://blog.csdn.net/feichangyanse/article/details/128559542
[6] 【Linux服务器miniconda安装及使用教程】:https://blog.csdn.net/qq_41795565/article/details/114181048?spm=1001.2014.3001.5501
[7] 【对抗样本中L0、L2、Linf范数的理解与实现】:https://blog.csdn.net/qq_56039091/article/details/125231973















 6382
6382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









