







Cross-Modality 3D Object Detection(point-wise fusion+roi-wise fusion)
WACV 2021
先验知识:RPN的分类分数只是用来判断anchor是否含有目标,但可能对应是正例的anchor没完全包含目标,不过没有影响,这些都是靠RPN的另一分支去做位置回归来调整,有目标就是正例,只有分类为正例的anchor才会进行位置修正。在检测头回归bbox坐标时,其实就是针对proposal的坐标进行微调了(可以理解为把proposal看出新的anchor)
1.摘要+intro
本文重点探讨了图像和点云的融合在三维目标检测中的应用。
以双目图像和原始点云为输入,提出了一种新颖的两级多模态融合网络用于三维目标检测,整个网路结构便于两级融合。
通过点特征融合,可以使双目图像中的每个点具有丰富的语义信息。通过ROI-wise的融合,使得产生的proposal更鲁棒。利用联合anchor机制,我们可以很好地约束3d bbox回归。此外,我们还提出使用伪激光雷达点云来增强GT点云的稀疏性,自适应地裁剪伪激光雷达点,并添加到GT点云中作为一种数据增强方法。
2.贡献点
1)提出了一种结合双目图像对和点云的两阶段融合框架来进行三维目标检测
2)通过将3D bounding box投影到2D图像空间,提出了一种2D-3D耦合损耗,以充分利用图像信息,约束3D bbox
方案与2D bbox一致。
3)我们通过在真实的3D场景中添加伪激光雷达点来补偿点云的稀疏性。
3.Method

利用双目图像和相应的LiDAR点云作为输入。在第一阶段,双目图像被传递给特征提取器,以提取其特征图,用于后续的point-wise特征融合。对于给定的点云,我们添加一个分类分支来预测每个点的置信度,并以前景点为中心放置3D anchor。然后将这些3D anchors投影到图像上,并采用它们进行2D分类和回归。在第二阶段,我们对第一阶段生成的每一对2D和3D proposals进行ROI级融合,以学习最终预测的更稳健和更具区分性的表示。
3.1. 特征提取
对于图像,利用改进的ResNet50作为编码器提取双目图像特征,经过编码的特征图下采样了32倍,分辨率较低不利用point-wise的融合,所以受FPN启发,采用自下而上的解码器对特征图进行多尺度上采样。对于点云,使用Pointnet++作为backbone。
3.2 Point-wise 特征融合

通过在不同层次的特征图上进行point-wise融合,使点能够从RGB图像中获得高层语义信息。首先从四个size的组中分别提取点的XYZ坐标,并将其投影到相应大小的图像特征图上。例如,(B,4096,96)的点云对应(B,1024,H/32,W/32),(B,256,96)的点云对应(B,256,H/32,W/32)。 这里点云投影到像素上,有些像素可能没有对应的点。
3.3. Proposal 生成网络
3.3.1 Joint Anchor
在生成proposals(proposal就理解为微调后的anchor)之前,我们需要确定预先的anchor。我们基于point-wise融合的特征对原始点云进行分割,只从分割的前景点中生成proposals,以减小3D proposals生成的搜索空间。通过对训练数据集进行聚类得到每个anchor预先的大小定义。将这些3D anchor的中心点放置在对应每个前景点的中心,然后将其投影到图像上以生成2D anchor。得益于投影,不需要为图像分配不同比例的额外2D anchor,因为它的尺度自适应得益于投影。通过anchor生成机制,2D和3D区域紧密相连,便于后续分类和回归。
3.3.2 Joint Proposal

1)对于生成proposal的分类部分(分类的作用:只有被分为正例的anchor才会对anchor进行位置微调生成proposal):利用生成的point-to-pixel fusion特征,进行点云分割,分割出前景和背景;以每个前景点为中心放置3d anchor。3d anchor被投影到图像生成2d anchor,利用框的IOU阈值判断该2d点是前景还是背景,3d和2d是用的同样置信度分数即都等于3d分割出的那个分数,但是由于点个数不同,这两个分割损失的大小是有区别的。2D 分割损失为binary cross entropy loss,3D 分割损失为 focal loss,将两者加起来使得2d和3d产生联系。
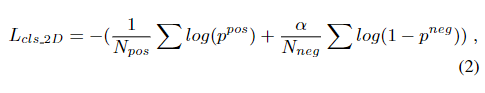
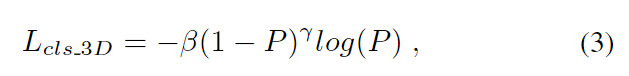
2)对于生成proposal的回归部分:作者提出了一种重投影损失,以提高proposals生成的性能。因为2D anchor对应于真实世界的平截体区域,通过回归2d proposals,我们其实就是将圆锥体区域回归到真实世界的区域。虽然它不能为3D方案提供精确的3D位置,它仍然能够为3D回归提供粗略的方向。对3D anchor和2D anchor分别在他们的检测头计算完损失后,将回归的3D anchors投影到2D 生成2D anchors。然后再计算生成的2D anchor和2D回归的anchor之间的loss,用(x,y,w,h)和投影的(x’,y’,w’,h’)来计算。
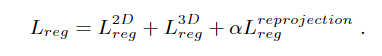
3.4 Box Refinement
3.4.1 Proposal-wise 特征融合

在第一阶段获得高质量的3D bbox proposals之后,最后要对proposals进行最后的调整。虽然上述已经进行了point-wise的融合来丰富高层语义信息,但这只是点对像素级的融合,对于学习每个proposal的特定局部特征来说仍然太稀疏了。因此,我们应用基于区域的特征融合来学习更密集的表示。
具体做法就是对于3d proposal,转换到每个proposal的local坐标系,其中坐标系的中心点是proposal的center,X,Z轴平行于地面。X轴指向proposal的heading方向,这样的方式更有利于local特征的学习。将每个点到传感器的距离作为损失的深度信息的补充。再通过几个MLP编码3D local point feature。对于2d proposal,直接从multi-scale feature的最后一层提取image feature,对再通过FC layer将其编码到与3D local point feature相同维度(这里思路就是把2d像素点数大小搞到和3d点数大小一样,其实等同于将像素点个数复制到N份是一个思路,只是MLP比复制n份实现更复杂),作为2D region feature。最后将3D local point feature、局部点云坐标、深度信息和2D region feature 四个信息concatenate,形成Fused features。
3.4.2 Final Prediction
对于上述给定高质量的proposals和上述强表示的fused feature,采用轻量级的Point-Net进行refine,生成最终检测结果。
3.5. Pseudo-LiDAR Fusion
由于点云的稀疏性,一些需要检测的对象可能只包含很少的点,因此我们希望通过伪LiDAR点云来补偿这种稀疏性来提高检测性能。对于双目图像,可以通过立体匹配来预测像素视差,再通过逆投影得到每个像素对应的pseudo lidar point。举个例子:对于高度遮挡或者远距离的3D物体,其像素大小为10*10,但仅有10个点云,我们可以通过预测pixel-wise的深度来产生100个pseudo lidar point进行补充。训练阶段,仅fuse 2D GT box内的pseudo point;inference阶段,利用fuse 2D 预测box内的pseudo point。
但是,由于深度估计的误差,生成的pseudo point通常不准确,包括 long tails 和 local misalignment问题:长尾效应主要是由于目标边缘深度预测不准确造成的,为此我们设计了一个点云统计过滤来过滤掉所有的孤立点。针对local misalignment问题,利用GT 点云纠正pseudo 点云,即:对于每个预测2D Bbox,提取对应的GT点云和pseudo点云,然后计算每个pseudo点云到最近K个 GT点云的平均距离D,再将整体点云作为一个整体移动一定距离使得所有平均距离D的和最小,以实现深度矫正。
4.实验结果
















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









