







 超级会员免费看
超级会员免费看
简介
- 前面我们通过 算法理论+手动实现 的方式,深入了解了机器学习的基本原理
- 这种方式不仅深化了对基础原理的理解,同时也一定程度锻炼了代码实现能力,而这些都是一名算法工程师的基本功
- 代码实现主要用到 Numpy 模块,还涉及 Matplotlib 绘图,Pandas 和一些基础语法,总结了一些常用技能,但还需要自主思考深化理解,手动写代码看源码
- 不过,伴随着算法难度逐渐加深,以前的学习方式将逐渐变得不太适用,至少对初学者来说,面对复杂算法学习时,并不高效。对于定位在利用算法解决问题的算法工程岗位来说,整体的技能要求其实是内功和招式并重的
- 也就是说,我们不仅需要通晓算法原理以及具备一定的编程能力,同时也需要掌握一些能够比手动编写算法更高效的执行机器学习建模的工具,也就是掌握一些算法包或者算法库工具
- 所谓算法库或者算法包,其实就是指封装了一系列可以执行机器学习算法建模相关功能的函数和类的程序模块,其功能调用方法和此前我们自定义的ML_basic_function.py文件类似
- 当然,对于不同的编程语言和运行环境,其实有对应不同的算法库或算法包,例如在 R 语言中,就有数以万计的针对不同算法的一个个独立的算法包,比较有名的诸如提供分类模型建模功能支持的rpart 包、提供聚类算法建模功能的 cluster 包等等
- 尽管这些分门别类的包在每一项(类)具体算法建模过程中都能提供非常专业的功能支持,但由于这些算法包是由不同的团队/个人来进行的开发和维护,包的使用方法和维护都各不相同,这就使得一个使用 R 语言的算法工作者在日常工作中至少需要和几十个算法包打交道,并且由于各个包相对独立,使得算法工作者需要时刻关注各包的更新情况及兼容方法(如果需要的话),这些都在无形之中对使用R语言进行机器学习建模造成了一定的阻碍
- 虽然 Python 也是开源语言,但或许是吸取了R语言的前车之鉴(Python比R诞生更晚),也或许是拥有了更完整的科学计算库 SciPy,Python 数据科学的一些核心功能都由一些更加统一和规范的第三方库来提供,例如科学计算库 NumPy、表格数据分析包 Pandas,以及机器学习算法库Scikit-Learn
- 算法包、算法库、算法框架概念辨析:
- 很多时候我们在使用这三个概念的时候并不会特别在意三者的区别,或者说大多数时候这三者概念的区别并不会影响我们实际对不同的程序模块的称呼,例如我们会称呼 sklearn 为一个算法库,要使用 xgboost 时候需要安装一个对应的算法包,而类似 PyTorch、TensorFlow 这种能够执行深度学习运算的模块,我们则会称其为算法框架
- 但其实三者其实还是略有区别,对于算法包来说,可能只是包含了支持单独一个或一类算法使用的类或函数
- 而算法库则指封装程度更高、对机器学习这一大类算法功能实现更加完整、甚至是定义了一类数据结构的代码模块
- 如果是算法框架,则会在算法库的基础上,更进一步定义基本对象类型的运行方式
- 这一篇,我们主要研究 Scikit-Learn 算法库的基本使用
Scikit-Learn
- 前世今生

- 作为非营利性组织维护的开源项目,我们可以从 Scikit-Learn 项目官网学到很多有价值的东西

- sklearn 中核心对象类型就是 NumPy 当中的数组(array),诸多数学计算过程也都是基于 SciPy 中的相关功能来进行实现
- 为啥强调这个呢?因为底层数据结构对算法库的影响是至关重要的
- 在分布式计算框架 Spark 中,算法库就有两类,其一是围绕Spark基本数据结构 RDD 构建的
ML包 - 其二则是围绕Spark高级数据结构 DataSet 和 DataFrame 构建的
MLLib包。当然由于基于更高级的数据结构所构建的算法模型更易于使用,因此ML包已经不再更新了
- 安装
- 对于通过 Anaconda 安装 Python,sklearn 包已经在安装Anaconda的过程中安装好了,并且不同平台的Anaconda就已经自带了能够在对应平台运行的 sklearn 包
- 这里使用 scikit-learn-1.2.0
概念
- 作为功能完整算法库,sklearn 不仅提供了完整的机器学习建模功能支持,同时也提供了包括数据预处理、模型评估、模型选择等诸多功能
- 并且支持以Pipelines(管道)形式构建机器学习流,而基于Pipeline和模型选择功能甚至能够衍化出AutoML(自动机器学习)的相关功能,也就是现在所谓的 Auto-sklearn
- 核心对象类型:评估器(estimator)
- 很多功能完整的第三方库其实都有各自定义的核心对象类型,如NumPy中的数组(Array)、Pandas中的DataFrame、以及PyTorch中的张量(tensor)等
- 当然这些由第三方库定义的数据结构实际上都是定义在源码中的某个类,在调用这些对象类型时实际上都是在实例化对应的类
- 而对于sklearn来说,定义的核心对象类型就是评估器。我们可以将评估器就理解成一个个机器学习模型,而sklearn的建模过程最核心的步骤就是围绕着评估器进行模型的训练
- 同样,围绕评估器的使用也基本分为两步,其一是实例化该对象,其二则是围绕某数据进行模型训练
LinearRegression
- 接下来,我们就尝试调用sklearn中的线性回归评估器(模型)来进行线性回归建模实验
# 此前定义的、基本规律满足 𝑦=2𝑥1−𝑥2+1 分布回归类数据集 # 设置随机数种子 np.random.seed(24) # 扰动项取值为0.01 features, labels = arrayGenReg(delta=0.01) # 可视化数据分布 plt.subplot(121) plt.plot(features[:, 0], labels, 'o') plt.subplot(122) plt.plot(features[:, 1], labels, 'o') # 方法一:直接导入sklearn import sklearn # 然后在sklearn里面的linear_model模块内查询LinearRegression评估器 sklearn.linear_model.LinearRegression # 方法二:直接导入sklearn内的linear_model模块 from sklearn import linear_model # 然后在linear_model模块内查询LinearRegression评估器 linear_model.LinearRegression # 方法三:直接导入LinearRegression评估器,一般使用这种方法 from sklearn.linear_model import LinearRegression # 实例化 model = LinearRegression() X = features[:, :2] # 特征矩阵,不需要包含截距项系数(全1列) y = labels # 标签数组 # 调用评估器中的fit方法进行模型训练 model.fit(X, y) fit方法是 LinearRegression 类中的一个至关重要的方法,同时也是 sklearn 中代表模型的评估器都具有的方法,当 fit 方法执行完后,即完成了模型训练,此时 model 就相当于一个参数个数、参数取值确定的线性方程(模型出炉了)- 而这些包括参数取值在内的所有模型信息,我们都可以通过调用model对象当中的一些属性来查看
# 查看自变量参数 model.coef_ # 查看模型截距 model.intercept_ - 可以发现,整个过程简洁明了,但要注意
- 无论是特征矩阵还是标签数组,最好都先转化成 array 对象类型再进行输入;不建议使用 array-like
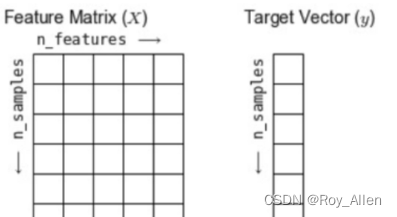
- 一般称特征矩阵为 Features Matrix,称特征数组为 Target Vector,并且以
n
s
a
m
p
l
e
s
n_{samples}
nsamples 表示数据行数,
n
f
e
a
t
u
r
e
s
n_{features}
nfeatures 表示特征矩阵列数
- 也可以对比最小二乘法的手动计算结果
np.linalg.lstsq(features, labels, rcond=-1)[0] # 结果一样 - 预测
model.predict(X)[:10] # 对比 y[:10] # 通过对比,我们不难发现发现,模型整体预测效果较好
实用函数
- 尝试调用 sklearn 中的
MSE计算函数,对上述建模结果进行模型评估 - 值得注意的是,这些函数不属于评估器(类),而是一个个单独的函数,要区分
# 在metrics模块下导入MSE计算函数 from sklearn.metrics import mean_squared_error # 输入数据,进行计算 mean_squared_error(model.predict(X), y) # 9.300731379745624e-05 # 参数 l = model.coef_.flatten().tolist() l.extend(model.intercept_.tolist()) # [1.9996189241115245, -0.9998528065894624, 0.9997054101551712] w = np.array(l).reshape(-1, 1) # 对比手动计算的MSE计算结果 MSELoss(features, w, y) # array([[9.30073138e-05]]) 简直一毛一样
超参数
- 所谓超参数,指的是无法通过数学过程进行最优值求解、但却能够很大程度上影响模型形式和建模结果的因素
- 例如线性回归中,方程中自变量系数和截距项的取值是通过最小二乘法或者梯度下降算法求出的最优解,然而,是否带入带入截距项、是否对数据进行归一化等,这些因素同样会影响模型形态和建模结果,但却是人工判断然后做出决定的选项,而这些就是所谓的超参数
- sklearn 中,对每个评估器进行超参数设置的时机就在评估器类实例化的过程中
- 我们可以查看L inearRegression 评估器的相关说明
LinearRegression?,会返回类说明

- 可以查看模型对象的参数情况:
model.get_params()
- 我们可以查看L inearRegression 评估器的相关说明
- 值得注意,超参数的设置方法和参数不同,一个模型的参数形式基本根据模型的计算规则就能确定,而一个模型包含几个超参数,其实是因模型而异、因工具而异的
- 例如,对于sklearn来说,我们可以通过 n_jobs 来设置参与计算的 CPU 核数,而在 Spark 中则是通过配置文件中的配置选项来分配每个任务的计算资源,不需要在算法执行过程中设置该超参数
- 但无论如何,sklearn 中的超参数设计一定是一整套最符合 sklearn 设计理念以及模型运行方式的超参数,我们在实例化模型的过程中必须谨慎的选择模型超参数,以达到最终模型训练的预期
- 不过 sklearn 非常人性化的一点是,尽管大多数模型有非常多的超参数(线性回归除外),但sklearn 都对其设置了一套非常普适的默认值,从而使得在很多场景下,在无需特别关注的一些超参数的取值上,我们都能够直接使用默认值带入进行建模
- 还能够在类的说明中查阅关于模型对象训练完后的相关属性(只有当模型训练完毕后才能)
- 例如对线性回归
- 例如对线性回归
参数求解方法
- sklearn 用的什么求解方法呢?梯度下降?
- 要详细了解训练过程的参数求解方法,需要回到官网中查阅评估器的相关说明
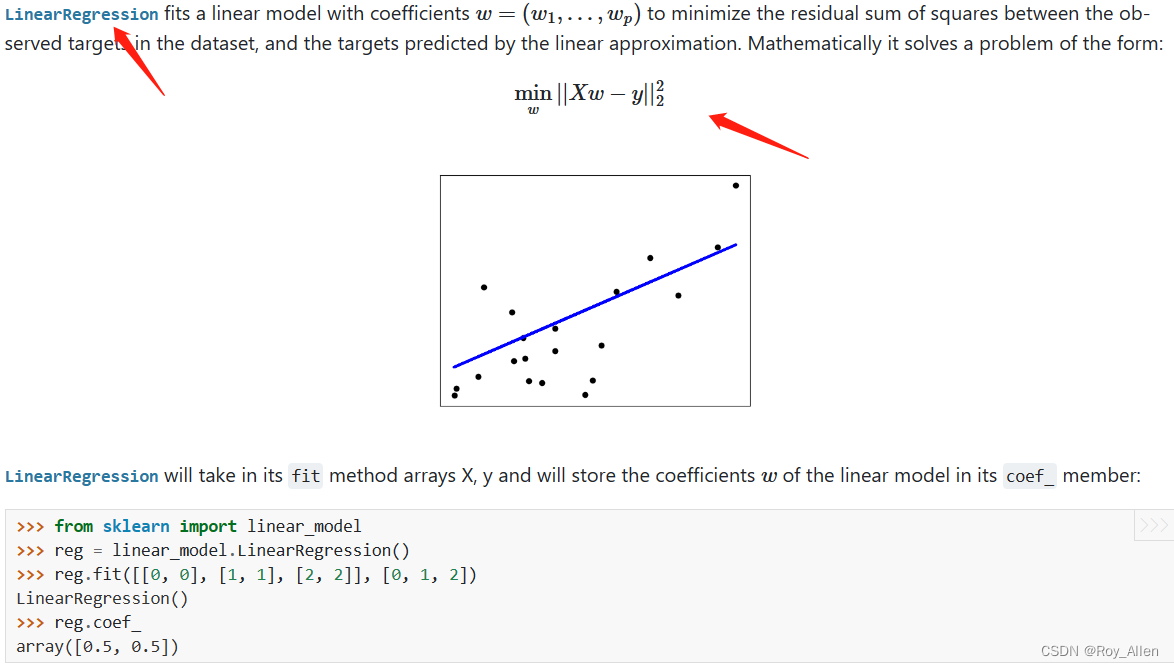
- 官网关于求解方法的说明很详细,以线性回归为例

- 官网分六大版块
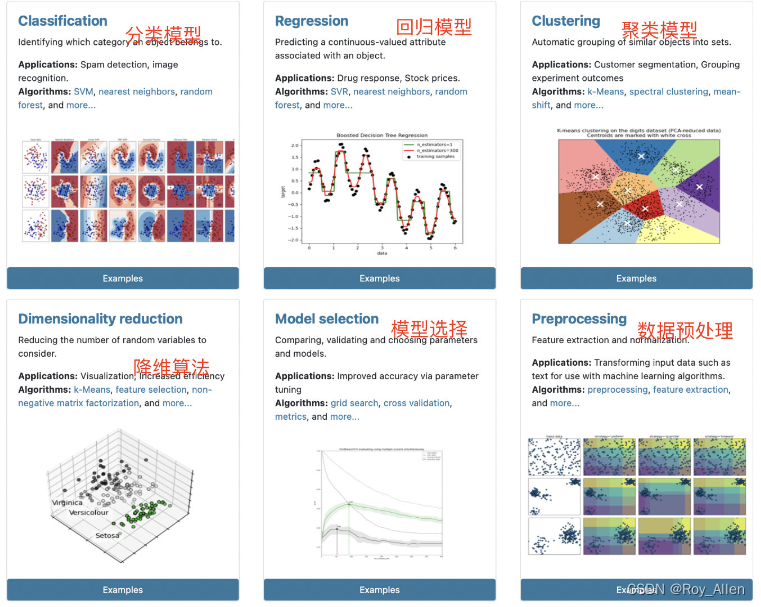
- 其中分类模型、回归模型和聚类模型是机器学习内主流的三大类模型,其功能实现主要依靠评估器类,并且前两者是有监督学习、聚类模型属于无监督学习范畴
- 当然,sklearn 中并未包含关联规则相关算法,如 Apriori 或者 FP-Growth,这其实一定程度上和sklearn 只能处理 array-like 类型对象有关
- 而后三者,降维算法、模型选择方法和数据预处理方法,则多为辅助建模的相关方法,并且既有评估器也有实用函数
- 上述六个功能模块的划分其实是存在很多交叉的,对于很多模型来说,既能处理分类问题、同时也能处理回归问题,而很多聚类算法同时也可以作为降维方法。不过这并不妨碍我们从这些功能入口出发,去寻找我们需要的评估器或实用函数
- 例如线性回归对用评估器可从 Regression 进入进行查找,而对用模型评估指标,由于评估指标最终是指导进行模型选择的,因此模型评估指标计算的实用函数的查找应该从
Model selection入口进入,并且在 3.3 Metrics and scoring: quantifying the quality of predictions内
- 因为说的详细,所以我们找自己需要的内容也有些麻烦,如果快速定位?
- 上面说到的方法是一种,就是从功能入手,关联到某个板块
- User Guide:sklearn 所有内容的合集文档;可以下载慢慢研读(和高数一起)
- API:按照二级模块(某个大类下面的)首字母排序的接口查询文档(根据评估器或实用函数的名字去查找)
- 源码阅读
- 阅读开源算法框架的源码,其实是很多高阶算法工程师自我提升的必经之路。尽管 sklearn 中出于代码运行速度考虑,有部分算法是用 cython 重写了,但目前大多数代码都在朝着代码可读性和易用性方向发展(降低协作门槛),因此大部分模块的代码还是相对不难读懂的
- 不过在初中级阶段、尤其是以调用评估器建模为主的情况下,还是应以熟练掌握常用评估器和实用函数、以及其背后的实现原理(数学过程)为核心进行学习,并不推荐在当前阶段阅读源码
- 接下来,熟悉一下 sklearn 提供的其他常用功能
常用功能
- 为了进一步构建功能更加完整与复杂的模型,先来练习使用更多的 sklearn 功能
数据集读取
- sklearn 提供了非常多的内置数据集,并且还提供了一些创建数据集的方法
- sklearn 中的数据集相关功能都在
datasets模块下,我们可以通过 API 文档中的datasets模块对所有的数据集和创建数据集的方法进行概览 - 不难发现,sklearn 中提供了结构化数据集(如经典的鸢尾花数据集、波士顿房价数据集、乳腺癌数据集等),同时也提供了一些如图片数据、文本数据等
- 此外,sklearn 中还提供了许多能够创建不同数据分布的数据生成器(用 make 函数创建),和我们此前定义的数据生成器类似

- 鸢尾花数据的读取
from sklearn.datasets import load_iris iris_data = load_iris() # 在默认情况下,数据读取结果的类型是Bunch类型,是一个类似字典类型的对象 type(iris_data) # sklearn.utils._bunch.Bunch # 该对象有如下属性
# 特征数据 iris_data.data[:10] # 特征名称 iris_data.feature_names # 标签数据 iris_data.target[:10] # 类别(标签名称) iris_data.target_names[:10] # ['setosa', 'versicolor', 'virginica'] - 如果希望只返回特征矩阵和标签数组,则可以通过在读取数据集时设置参数
return_X_y为 True 来实现 - 如果想创建 DataFrame 对象,则可以通过在读取数据集时设置参数
as_frame为 True 来实现iris_dataFrame = load_iris(as_frame=True) iris_dataFrame.frame
- 数据集切分
from sklearn.model_selection import train_test_split # 查阅该函数的帮助文档 train_test_split? # 注意随机数种子 random_state 的设置 X = np.arange(12).reshape((6, 2)) y = np.array([0, 0, 0, 1, 1, 1]) train_test_split(X, y, random_state=42) # 结果如下 [array([[10, 11], [ 4, 5], [ 8, 9], [ 6, 7]]), array([[0, 1], [2, 3]]), array([1, 0, 1, 1]), array([0, 0])] train_test_split(X, y, random_state=24) # 结果如下 [array([[2, 3], [0, 1], [6, 7], [4, 5]]), array([[ 8, 9], [10, 11]]), array([0, 0, 1, 0]), array([1, 1])] stratify参数控制训练集和测试集中,不同类别样本所占的比例;若希望切分后的训练集和测试集中0、1两类的比例和原始数据相同,则可另stratify=ytrain_test_split(X, y, stratify=y, random_state=42) # 注意,是个list,方便取各数据集 [array([[ 2, 3], [10, 11], [ 0, 1], [ 8, 9]]), array([[6, 7], [4, 5]]), array([0, 1, 0, 1]), array([1, 0])]
标准化与归一化
- 从功能上划分,sklearn 中的归一化分为标准化(Standardization)和归一化(Normalization)两类
- 其中,此前所介绍的 Z-Score 标准化和 0-1 标准化,都属于 Standardization 的范畴,而在sklearn中,Normalization 则特指针对单个样本(一行数据)利用其范数进行放缩的过程
- 此前在大多数场景下我们并不会对标准化和归一化进行特意的区分,但 sklearn 中标准化和归一化则指不同的数据处理方法
- 不过二者都属于数据预处理范畴,在 sklearn 中的 preprocessing 模块下
from sklearn import preprocessing
标准化
- sklearn 的标准化过程,包括 Z-Score 标准化和 0-1标准化;既可以通过实用函数来进行标准化处理,也可以利用评估器来执行标准化过程
- Z-Score 标准化
- 函数实现方法
X = np.arange(9).reshape(3, 3) preprocessing.scale(X) array([[-1.22474487, -1.22474487, -1.22474487], [ 0. , 0. , 0. ], [ 1.22474487, 1.22474487, 1.22474487]]) # 用此前定义的函数处理,对比结果 z_score(X)使用函数进行标准化处理,尽管从代码实现角度来看清晰易懂,但却不适用于许多实际的机器学习建模场景
其一是因为在进行数据集的训练集和测试集切分后,我们首先要在训练集进行标准化、然后统计训练集上均值和方差再对测试集进行标准化处理,也就是说还需要一个统计训练集相关统计量的过程
其二则是因为相比实用函数,sklearn 中的评估器提供了 Pipeline 工具能够对多个评估器进行串联,组成一个机器学习流,简化了模型的代码量,因此通过评估器的方法进行数据标准化,是一种更加通用的选择 - 评估器实现方法
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X = np.arange(15).reshape(5, 3) X_train, X_test = train_test_split(X) (array([[ 9, 10, 11], [ 6, 7, 8], [ 0, 1, 2]]), array([[12, 13, 14], [ 3, 4, 5]])) scaler.fit(X_train)虽然同样是输入数据,但标准化的评估器和训练模型的评估器实际上是不同的计算过程;
此前介绍的线性方程的评估器,是输入数据进行训练的过程(fit过程),实际上是计算线性方程的参数,而此处标准化的评估器实际上是对输入数据的相关统计量进行了计算;
后续将用这些统计量对各数据进行标准化计算。且这些统计量都可以通过相关属性进行调用和查看,函数实现方法并不支持# 查看训练数据各列的标准差 scaler.scale_ # 查看训练数据各列的均值 scaler.mean_ # 查看训练数据各列的方差 scaler.var_ # 标准差 np.sqrt(scaler.var_) # 总共有效的训练数据条数 scaler.n_samples_seen_ # 接下来,我们可以通过评估器中的transform方法来进行数据标准化# 利用训练集的均值和方差对训练集进行标准化处理 scaler.transform(X_train) array([[ 1.06904497, 1.06904497, 1.06904497], [ 0.26726124, 0.26726124, 0.26726124], [-1.33630621, -1.33630621, -1.33630621]]) # 利用训练集的均值和方差对测试集进行标准化处理 scaler.transform(X_test) array([[ 1.87082869, 1.87082869, 1.87082869], [-0.53452248, -0.53452248, -0.53452248]]) # 比较 z_score(X_train) - 还可以使用
fit_transform对输入数据进行直接转化scaler = StandardScaler() # X_train上fit和transfrom scaler.fit_transform(X_train) # 接下来,我们就能直接代入标准化后的数据进行建模了
- 函数实现方法
- 0-1 标准化
- 函数实现方法
X = np.arange(15).reshape(5, 3) preprocessing.minmax_scale(X) array([[0. , 0. , 0. ], [0.25, 0.25, 0.25], [0.5 , 0.5 , 0.5 ], [0.75, 0.75, 0.75], [1. , 1. , 1. ]]) # 对比自定义函数计算结果 maxmin_norm(X) - 评估器实现方法
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit_transform(X) # 0-1标准化的统计量 scaler.data_min_ scaler.data_max_
- 函数实现方法
- sklearn 中还有针对稀疏矩阵的标准化(MaxAbsScaler)、针对存在异常值点特征矩阵的标准化(RobustScaler)、以及非线性变化的标准化(Non-linear transformation)等方法,相关内容待后续介绍
归一化
- 和标准化不同,sklearn 中的归一化特指将单个样本(一行数据)放缩为单位范数(1范数或者2范数为单位范数)的过程;放缩 <=> 等比例,和标准化的数学过程不一样
- 该操作常见于核方法或者衡量样本之间相似性的过程中。这些内容此前没介绍过,但此处先介绍关于归一化的相关方法,为后续内容做铺垫;同样,归一化也有函数实现和评估器实现两种
- 函数实现
- 假设向量
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
x = [x_1, x_2, ..., x_n]^T
x=[x1,x2,...,xn]T,则向量x的 1-范数 的基本计算公式为:
∣ ∣ x ∣ ∣ 1 = ∣ x 1 ∣ + ∣ x 2 ∣ + . . . + ∣ x n ∣ ||x||_1 = |x_1|+|x_2|+...+|x_n| ∣∣x∣∣1=∣x1∣+∣x2∣+...+∣xn∣ - 即各分量的绝对值之和,向量x的2-范数计算公式为:
∣ ∣ x ∣ ∣ 2 = ( ∣ x 1 ∣ 2 + ∣ x 2 ∣ 2 + . . . + ∣ x n ∣ 2 ) ||x||_2=\sqrt{(|x_1|^2+|x_2|^2+...+|x_n|^2)} ∣∣x∣∣2=(∣x1∣2+∣x2∣2+...+∣xn∣2) - 即各分量的平方和再开平方
- sklearn 中的 Normalization 过程,实际上就是将每一行数据视作一个向量,然后用每一行数据去除以该行数据的1-范数或者2-范数(单位化)。具体除以哪个范数,以preprocessing.normalize函数中输入的
norm参数为准# 1-范数单位化 preprocessing.normalize(X, norm='l1') np.linalg.norm(X, ord=1, axis=1) - 验证一下
np.linalg.norm(X, ord=1, axis=1) # array([ 3., 12., 21., 30., 39.]) 每一行的范数 np.sum(X, axis=1) # 都是非负数,所以直接sum也是同样的结果 # array([ 3, 12, 21, 30, 39]) X / np.linalg.norm(X, ord=1, axis=1).reshape(5, 1) # 对应行相除 - 二范数单位化也是类似
- 假设向量
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
x = [x_1, x_2, ..., x_n]^T
x=[x1,x2,...,xn]T,则向量x的 1-范数 的基本计算公式为:
- 评估器实现
from sklearn.preprocessing import Normalizer normlize = Normalizer() # 'l2' by default normlize.fit_transform(X) normlize = Normalizer(norm='l1') normlize.fit_transform(X) - 除了标准化和归一化之外,还有一个正则化(Regularization)的概念,所谓正则化,往往指的是通过在损失函数上加入参数的1-范数或者2-范数的过程,该过程能够有效避免模型过拟合
- 关于评估器、解释器、转化器等名词的辨析
- 其实这一组概念广泛存在于不同的算法库和算法框架中,但不同的算法库对其的定义各有不同
- 并且 sklearn 对其定义也并不清晰,因此,为了统一概念,我们称所有的sklearn中类的调用为评估器的调用(都是用作建模),而不区分评估器与转化器
逻辑回归评估器
- 接下来,我们尝试对上述鸢尾花数据进行逻辑回归模型多分类预测,需要注意的是,sklearn 中的逻辑回归在默认参数下就支持进行多分类问题判别,并且支持此前介绍的 MvM 和 OvR 策略
- 先尝试使用逻辑回归评估器进行建模,大部分评估器的使用步骤都是类似的
# 导入逻辑回归评估器 from sklearn.linear_model import LogisticRegression # 数据准备 X, y = load_iris(return_X_y=True) # 查看函数参数 LogisticRegression? # 实例化模型,使用默认参数 clf_test = LogisticRegression(max_iter=1000, multi_class='multinomial') # 最大迭代次数1000,多分类问题时采用MvM策略 # 带入全部数据进行训练 clf_test.fit(X, y) # 查看线性方程系数 clf_test.coef_ # 在全部数据集上进行预测 clf_test.predict(X)[:10] # 查看概率预测结果 clf_test.predict_proba(X)[:10] # 查看准确率 clf_test.score(X, y) # 0.9733333333333334 # 也可以进行准确率计算 from sklearn.metrics import accuracy_score accuracy_score(y, clf_test.predict(X)) - 步骤:准备数据,设置参数,训练,预测,计算准确率
机器学习流
- 指一个完整的模型训练流程(pipeline),一般我们会串联评估器形成机器学习流
- 不能串联实用函数,最终串联的结果其实也等价于一个评估器
- 例如:将数据归一化、逻辑回归进行多分类建模等过程串联在一起
from sklearn.pipeline import make_pipeline # 在make_pipeline中输入评估器的过程同时对评估器类进行参数设置 pipe = make_pipeline(StandardScaler(),LogisticRegression(max_iter=1000)) # 数据集切分 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) # 训练 pipe.fit(X_train, y_train) # 预测 pipe.predict(X_test) # 准确率 pipe.score(X_test, y_test) pipe.score(X_train, y_train) - 当模型构建完毕之后,可以借助
joblib包对模型存储和读取import joblib joblib.dump(pipe,'pipe.model') # 保存 pipe1 = joblib.load('pipe.model') # 读取 pipe1.score(X_train, y_train) - 其实就是保存了特征和系数
- 下一节将从逻辑回归出发,讨论关于正则化、过拟合、特征衍生、特征筛选等非常重要的机器学习概念
















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











