






目录
一、引言
图像去噪是一种经典的图像恢复任务,其目的是从有噪声的观测中预测出一幅干净的图像。在加性-噪声-破坏假设下,观测模型可表示为:

其中x为干净的图像,n为噪声。
二、分离聚合网络
本节将详细介绍所提出的用于图像去噪的分离聚合网络(SANet)。SANet由三个块组成,包括卷积分离块、深度映射块和带聚合块。SANet的架构如图1所示。
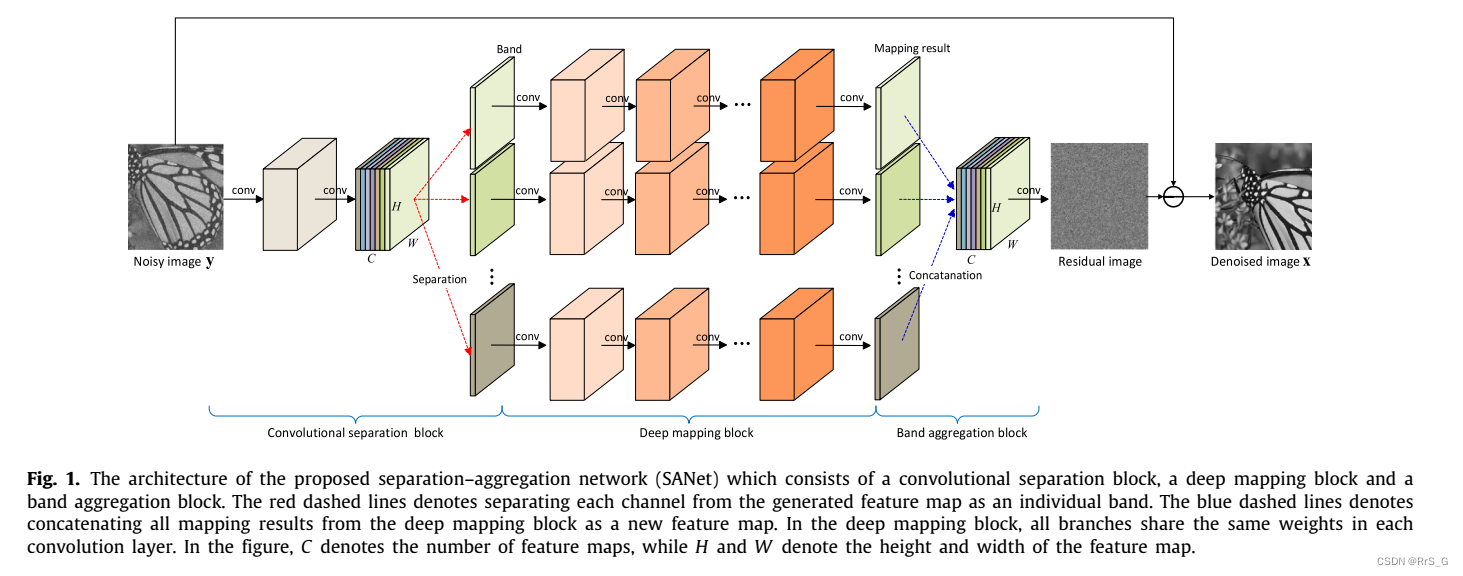
在SANet中,首先对输入的噪声图像进行卷积分离块。然后,将生成的特征映射中的每个通道视为一个单独的图像带,分别送入后续的深度映射块进行非线性变换。最后,带聚合块将所有映射结果连接为一个新的特征映射,并对其进行卷积输出。
2.1、卷积分离块
在SANet中,卷积分离块的作用是将输入的噪声图像分解成多个带,每个带呈现出更简单的模式。在深度卷积网络中,卷积层中的每个滤波器都可以看作是特定局部模式的检测器。在卷积过程中,表现出特定模式的像素会对结果feature map中对应的检测器(即filter)产生较高的响应,而其他具有不同模式的像素则会被抑制。因此,结果特征图中的每个通道只激活显示特定类型模式的像素,这比原始噪声图像简单得多。受此启发,作者采用SANet中的第一个卷积层作为卷积分离块,将每个通道从生成的feature map中分离出来作为一个单独的图像波段,如图1所示。因此,带的数量与卷积产生的特征图中的信道数相同。
将输入的噪声图像表示为y,则卷积分离块的输出可以表示为
![]()
为了证明卷积分离块的有效性,作者在图2中描述了一些分解波段的可视化示例。

可以看出,每个带噪声的图像都可以分解成多个带,这些带具有一些基本的模式,这些模式在图像之间是共享的。
2.2、深度映射块
给定第i个图像波段,该块的输出可以表示为

2.3、带聚合块
这个模块将所有这些n个映射结果连接到一个新的n通道特征映射,然后卷积这个特征映射来给出输出。相应的数学公式如下:

其中F表示n通道的特征映射。
2.4、用SANet进行残差学习
最近,研究表明残差学习方案有利于训练更好的深度神经网络用于图像去噪。受此启发,作者也利用SANet来预测残差图像(即噪声)。因此Eq.(3)中的Xr表示残差图像,如图1所示,对于SANet的训练问题可以给出为
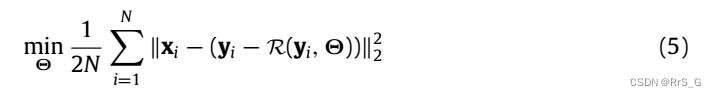
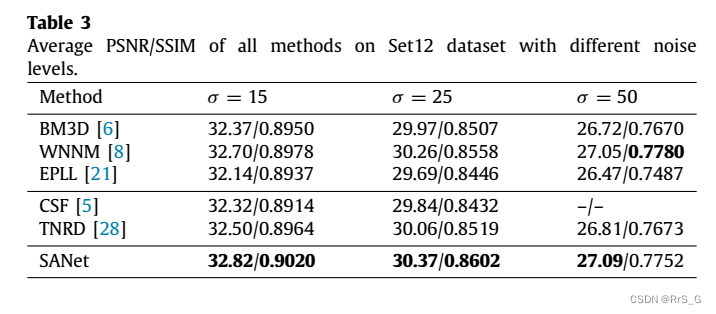
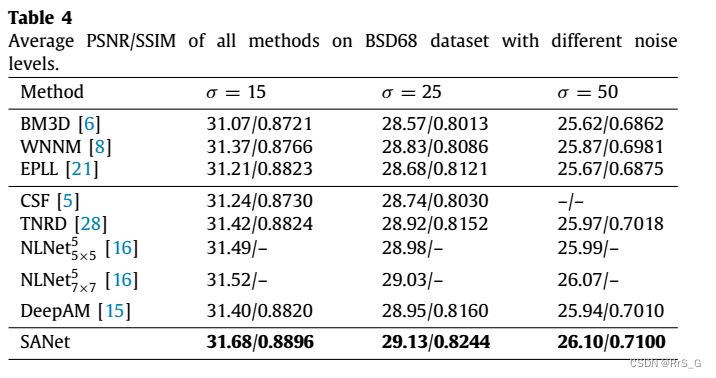
三、实验结果















 1693
1693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









