






一、背景
消息传递模型(Message Passing Model)基于拉普拉斯平滑假设(邻居是相似的),试图聚合图中的邻居的信息来获取足够的依据,以实现更鲁棒的半监督节点分类。
图神经网络(Graph Neural Networks, GNN)和标签传播算法(Label Propagation, LPA)均为消息传递算法,其中GNN主要基于传播特征来提升预测效果,而LPA基于迭代式的标签传播来作预测。
一些工作要么用LPA对GNN预测结果做后处理,要么用LPA对GNN进行正则化。但是,它们仍不能直接将GNN和LPA有效地整合到消息传递模型中。
为解决这个问题,本文提出了统一消息传递模型(UNIMP)[1],它可以在训练和推理时结合特征和标签传播。UniMP基于两个简单而有效的想法:
- 将特征嵌入和标签嵌入同时作为输入信息进行传播
- 随机掩码部分标签信息,并在训练时对其进行预测
UniMP在概念上统一了特征传播和标签传播,具有强大的经验能力。 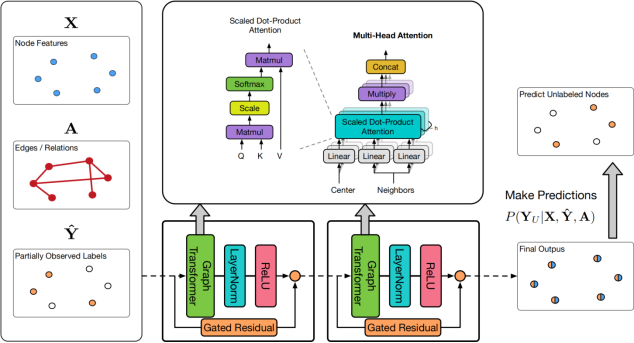
二、实现
2.1 关键部分
- 将标签进行嵌入(原有的C类One-hot标签,通过线性变换成与原始节点特征相同的维度)。
- 然后,将标签嵌入和节点特征相加作为GNN输入。 为避免训练时使用标签导致标签泄露,这里使用了掩码标签训练的策略。每个Epoch随机将训练集中部分节点的标签置(掩码)0(视为训练监督信号),然后利用节点特征 \(\mathbf{X}\) 和 \(\mathbf{A}\)以及剩余的标签去预测被掩码的标签)。
2.2 模型部分
UniMP中使用了GraphTransformer(Transformer中的Q、K、V注意力形式,并加上边特征),同时引入了Highway GCN(H-GCN)的门控残差机制来缓解过平滑。
2.3 代码
在百度飞桨的"飞桨学习赛:图神经网络入门节点分类"中使用了Arxiv引用文献数据集,https://aistudio.baidu.com/aistudio/projectdetail/5000390。
点击查看基于Paddle和PGL的代码
import pgl
import math
import paddle.fluid.layers as L
import pgl.layers.conv as conv
import paddle.fluid as F
from transformer_gat_pgl import transformer_gat_pgl
def get_norm(indegree):
float_degree = L.cast(indegree, dtype="float32")
float_degree = L.clamp(float_degree, min=1.0)
norm = L.pow(float_degree, factor=-0.5)
return norm
class UniMP(object):
def __init__(self, config, num_class):
self.num_class = num_class
self.num_layers = config.get("num_layers", 2)
self.hidden_size = config.get("hidden_size", 64)
self.out_size=config.get("out_size", 40)
self.embed_size=config.get("embed_size", 100)
self.heads = config.get("heads", 8)
self.dropout = config.get("dropout", 0.3)
self.edge_dropout = config.get("edge_dropout", 0.0)
self.use_label_e = config.get("use_label_e", False)
def embed_input(self, feature):
lay_norm_attr=F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=1))
lay_norm_bias=F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=0))
feature=L.layer_norm(feature, name='layer_norm_feature_input',
param_attr=lay_norm_attr,
bias_attr=lay_norm_bias)
return feature
def label_embed_input(self, feature):
label = F.data(name="label", shape=[None, 1], dtype="int64")
label_idx = F.data(name='label_idx', shape=[None, 1], dtype="int64")
label = L.reshape(label, shape=[-1])
label_idx = L.reshape(label_idx, shape=[-1])
embed_attr = F.ParamAttr(initializer=F.initializer.NormalInitializer(loc=0.0, scale=1.0))
embed = F.embedding(input=label, size=(self.out_size, self.embed_size), param_attr=embed_attr )
feature_label = L.gather(feature, label_idx, overwrite=False)
feature_label = feature_label + embed
feature = L.scatter(feature, label_idx, feature_label, overwrite=True)
lay_norm_attr = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=1))
lay_norm_bias = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=0))
feature = L.layer_norm(feature, name='layer_norm_feature_input',
param_attr=lay_norm_attr,
bias_attr=lay_norm_bias)
return feature
def get_gat_layer(self, i, gw, feature, hidden_size, num_heads, concat=True,
layer_norm=True, relu=True, gate=False):
fan_in=feature.shape[-1]
bias_bound = 1.0 / math.sqrt(fan_in)
fc_bias_attr = F.ParamAttr(initializer=F.initializer.UniformInitializer(low=-bias_bound, high=bias_bound))
negative_slope = math.sqrt(5)
gain = math.sqrt(2.0 / (1 + negative_slope ** 2))
std = gain / math.sqrt(fan_in)
weight_bound = math.sqrt(3.0) * std
fc_w_attr = F.ParamAttr(initializer=F.initializer.UniformInitializer(low=-weight_bound, high=weight_bound))
if concat:
skip_feature = L.fc(feature,
hidden_size * num_heads,
param_attr=fc_w_attr,
name='fc_skip_' + str(i),
bias_attr=fc_bias_attr)
else:
skip_feature = L.fc(feature,
hidden_size,
param_attr=fc_w_attr,
name='fc_skip_' + str(i),
bias_attr=fc_bias_attr)
out_feat = transformer_gat_pgl(gw, feature, hidden_size, 'gat_' + str(i), num_heads, concat=concat)
# out_feat= out_feat + skip_feature
if gate:
fan_in = out_feat.shape[-1]*3
bias_bound = 1.0 / math.sqrt(fan_in)
fc_bias_attr = F.ParamAttr(initializer=F.initializer.UniformInitializer(low=-bias_bound, high=bias_bound))
negative_slope = math.sqrt(5)
gain = math.sqrt(2.0 / (1 + negative_slope ** 2))
std = gain / math.sqrt(fan_in)
weight_bound = math.sqrt(3.0) * std
fc_w_attr = F.ParamAttr(initializer=F.initializer.UniformInitializer(low=-weight_bound, high=weight_bound))
gate_f = L.fc([skip_feature, out_feat, out_feat - skip_feature], 1,
param_attr=fc_w_attr,
name='gate_' + str(i),
bias_attr=fc_bias_attr)
gate_f = L.sigmoid(gate_f)
out_feat = skip_feature * gate_f + out_feat * (1 - gate_f)
else:
out_feat = out_feat + skip_feature
if layer_norm:
lay_norm_attr = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=1))
lay_norm_bias = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=0))
out_feat = L.layer_norm(out_feat, name='layer_norm_' + str(i),
param_attr=lay_norm_attr,
bias_attr=lay_norm_bias)
if relu:
out_feat = L.relu(out_feat)
return out_feat
def forward(self, graph_wrapper, feature, phase):
if phase == "train":
edge_dropout = self.edge_dropout
dropout = self.dropout
else:
edge_dropout = 0
dropout = 0
if self.use_label_e:
feature = self.label_embed_input(feature)
gate = True
else:
feature = self.embed_input(feature)
gate = False
if dropout > 0:
feature = L.dropout(feature, dropout_prob=dropout,
dropout_implementation='upscale_in_train')
for i in range(self.num_layers - 1):
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout)
feature = self.get_gat_layer(i, ngw, feature,
hidden_size=self.hidden_size,
num_heads=self.heads,
concat=True,
layer_norm=True, relu=True, gate=gate)
if dropout > 0:
feature = L.dropout(feature, dropout_prob=self.dropout,
dropout_implementation='upscale_in_train')
feature = self.get_gat_layer(self.num_layers - 1, ngw, feature,
hidden_size=self.out_size, num_heads=self.heads,
concat=False, layer_norm=False, relu=False, gate=True)
pred = L.fc(
feature, self.num_class, act=None, name="pred_output")
return pred
class Res_Unimp_Large(object):
def __init__(self, config, num_class):
self.num_class = num_class
self.num_layers = config.get("num_layers", 2)
self.hidden_size = config.get("hidden_size", 128)
self.out_size=config.get("out_size", 40)
self.embed_size=config.get("embed_size", 100)
self.heads = config.get("heads", 8)
self.dropout = config.get("dropout", 0.3)
self.edge_dropout = config.get("edge_dropout", 0.0)
self.use_label_e = config.get("use_label_e", False)
# 编码输入
def embed_input(self, feature):
lay_norm_attr=F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=1))
lay_norm_bias=F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=0))
feature=L.layer_norm(feature, name='layer_norm_feature_input',
param_attr=lay_norm_attr,
bias_attr=lay_norm_bias)
return feature
# 连同部分已知的标签编码输入(MaskLabel)
def label_embed_input(self, feature):
label = F.data(name="label", shape=[None, 1], dtype="int64")
label_idx = F.data(name='label_idx', shape=[None, 1], dtype="int64")
label = L.reshape(label, shape=[-1])
label_idx = L.reshape(label_idx, shape=[-1])
embed_attr = F.ParamAttr(initializer=F.initializer.NormalInitializer(loc=0.0, scale=1.0))
embed = F.embedding(input=label, size=(self.out_size, self.embed_size), param_attr=embed_attr )
feature_label = L.gather(feature, label_idx, overwrite=False)
feature_label = feature_label + embed
feature = L.scatter(feature, label_idx, feature_label, overwrite=True)
lay_norm_attr = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=1))
lay_norm_bias = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=0))
feature = L.layer_norm(feature, name='layer_norm_feature_input',
param_attr=lay_norm_attr,
bias_attr=lay_norm_bias)
return feature
def forward(self, graph_wrapper, feature, phase):
if phase == "train":
edge_dropout = self.edge_dropout
dropout = self.dropout
else:
edge_dropout = 0
dropout = 0
if self.use_label_e:
feature = self.label_embed_input(feature)
else:
feature = self.embed_input(feature)
if dropout > 0:
feature = L.dropout(feature, dropout_prob=dropout,
dropout_implementation='upscale_in_train')
#改变输入特征维度是为了Res连接可以直接相加
feature = L.fc(feature, size=self.hidden_size * self.heads, name="init_feature")
for i in range(self.num_layers - 1):
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout)
from model_unimp_large import graph_transformer, attn_appnp
res_feature = feature
feature, _, cks = graph_transformer(str(i), ngw, feature,
hidden_size=self.hidden_size,
num_heads=self.heads,
concat=True, skip_feat=True,
layer_norm=True, relu=True, gate=True)
if dropout > 0:
feature = L.dropout(feature, dropout_prob=dropout,
dropout_implementation='upscale_in_train')
# 下面这行便是Res连接了
feature = res_feature + feature
feature, attn, cks = graph_transformer(str(self.num_layers - 1), ngw, feature,
hidden_size=self.out_size,
num_heads=self.heads,
concat=False, skip_feat=True,
layer_norm=False, relu=False, gate=True)
feature = attn_appnp(ngw, feature, attn, alpha=0.2, k_hop=10)
pred = L.fc(
feature, self.num_class, act=None, name="pred_output")
return pred根据该比赛分享的Notebook,完全调通后的Notebook如下: 常规赛:图神经网络入门节点分类_UniMPlarge:https://aistudio.baidu.com/aistudio/projectdetail/5000390?sUid=2273234&shared=1&ts=1673617889761
可使用AiStuidio的免费算力一键运行, 大致在划分的验证集上Accuracy有0.755左右。
三、个人实验
将标签作为输入,在ArixV数据集节点分类任务上,能在小数点后第2位提升接近2个点。
论文BOT[2]中也对标签作为输入做了阐述,其作者还发表了相应的论文来论证标签作为输入的有效性的原因。
四、总结
标签有效的直觉就是,在图上的节点分类任务中,邻居标签也是预测目标节点标签的关键特征(这也和标签传播的思想一致)
标签嵌入和掩码标签预测是提升节点分类任务简单有效的方法。
这也印证了,特征层面的改进有时或许比模型结构提升来得更快。
参考文献
[1] Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification
[2] Bag of Tricks for Node Classification with Graph Neural Networks















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









