







 本文介绍了基于图标签传播的深度半监督学习方法。首先使用有标签样本训练特征提取器和分类器,然后计算所有样本的特征相似度以生成伪标签。接着,通过解决线性方程组得到归一化的伪标签矩阵,并采用加权策略处理伪标签的确定性和数据不平衡问题。最后,结合未标记数据的损失函数进行优化。实验在CIFAR-10、CIFAR-100和Mini-ImageNet数据集上验证了该方法的有效性。
本文介绍了基于图标签传播的深度半监督学习方法。首先使用有标签样本训练特征提取器和分类器,然后计算所有样本的特征相似度以生成伪标签。接着,通过解决线性方程组得到归一化的伪标签矩阵,并采用加权策略处理伪标签的确定性和数据不平衡问题。最后,结合未标记数据的损失函数进行优化。实验在CIFAR-10、CIFAR-100和Mini-ImageNet数据集上验证了该方法的有效性。
code:code
paper:paper
一篇半监督学习文章,基于图标签传播的转导学习。
主要步骤如下:1.用有label的样本学习一个特征提取器和对应分类器。2.基于特征提取器提取的特征计算所有样本(包括无label)之间的相似度。3.基于有label样本的label和相似度矩阵,计算出样本的伪label。4.用伪label进行监督学习。重复2到4这个步骤。
文章不是按算法的顺序进行介绍的,它先介绍别人的部分,然后再介绍自己补充的部分,下面我将文章中介绍的次序进行整理,以符合上面算法的流程,便于理解。
模型和算法
下面详细介绍上面几个步骤
有监督的loss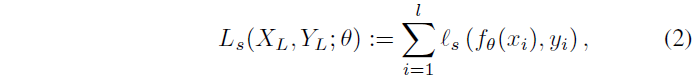
l s l_s ls通常是交叉熵,在开始的T个epoch,只进行有label部分的学习
基于特征相似性计算伪label
计算出n个样本的特征
V = ( v 1 , . . . , v n ) V = (v_1,...,v_n) V=(v1,..
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









