







这篇博客是一篇论文阅读札记,这篇论文的主题是使用GNN来优化加速器设计中的设计空间探索耗时过长的问题。
这篇文章的标题是《Enabling Automated FPGA Accelerator Optimization Using Graph Neural Networks》,值得注意的是这是它的预印版,2021年发布在arxiv上。正文后经过修改删减之后发布在DAC‘22上(6页),标题也改为了《Automated accelerator optimization aided by graph neural networks》,这篇文章的目的在于使用图神经网络来拟合HLS综合工具的结果,以期快速地对设计做出准确评估,加快DSE的过程。
0 Abstract
这部分作为全文的摘要, 和上一篇AutoDSE一样,提出了当前开发FPGA加速器的主要难点在于FPGA的开发门槛太高。另一方面虽然HLS的诞生在一定程度上缓解了这个问题,但是它在很多层次上涉及到HLS参数的选择,这个解决空间是非常大的,这个选择非常依赖于设计者的经验。另一方面,从HLS工具获得结果反馈耗时也非常大,一般在几分钟到数小时。
这篇工作针对这种情况开发了DSE-GNN框架,主要方法是通过GNN来拟合HLS模型来使得它可以应用于非常广泛的应用场景,从而使得设计者在毫秒级就可以得到高精度的设计点质量汇报,这可以帮助无论是手工设计者还是已有DSE框架在更更短的时间内找到帕累托最优解。
1 Introduction
这部分开头和摘要部分差不多,主要讲明了现有使用HLS来设计FPGA的困难之处,也就是HLS涉及到的重要选择点太多,这些不同的选择点组成了一个超大规模的设计空间。如何高效地去执行设计空间的搜索从而找出最优解是一个非常耗时的任务。所以一个全自动化的设计空间探索(DSE)框架是非常有现实意义的,但是
随后,这部分总结出了HLS-based DSE框架面临的几个挑战:
1.现有的商用HLS框架综合时间往往很长,这使得评估一个设计点的时间非常长,如若不然就必须得减小设计待搜索空间的尺寸,否则就会导致探索时间过长而难以承受。
2.超大规模设计空间,设计空间的规模随着候选参数的数量指数上升,为了高效地进行设计空间探索,每个配置点(configuration)的搜索时间必须尽可能短。
3.设计参数对性能的影响是非单调的并且相关的,文中举出的一个例子是性能随着UNROLL因子的变化不会呈现完全的单调效果。
不仅如此,这部分提到虽然FPGA加速器的应用范围遍及各个领域,但其实不同的应用之间会有一些共享的代码结构,使用一种学习算法学会这种通用的结构就可以实现不同领域之间知识的相互迁移。
这篇工作为了解决上述的问题,采纳了包含迁移学习的图神经网络(GNN with support for transfer learning)。这项工作首先建立了可以快速估计HLS加速器设计的模型,估算的时间大约在毫秒级,在这个过程中完全不用调用HLS工具来估算设计的表现。因为HLS在优化设计时使用了许多启发式方法(个人觉得这里所提到的启发式方法是HLS设计经验中的一些RTL专家经验),并且设计参数之间彼此会相互影响,所以在这里采用了深度学习模型来学习它们之间的相互作用关系。
本项工作将程序表示为一个图,这张图使用控制、数据、调用和设计参数(pragma)的形式来表示程序语义,并且使用GNN来提取预测设计质量所需要的图特征。除此之外,本项工作还提出了一些其他技术来提升模型预测的精度,包含:
1.跳跃知识网络(Jumping Knowledge Network, JKN)
2.节点注意力(Node Attention)
3.多头目标预测(Multi-head Objective Prediction)
在完成上述模型的构建之后,在其上运行DSE工具,结果表明在此模型的帮助下,DSE不仅可以快速地找到训练集中的设计最优点,也可以找到数据库之外的内核设计最优点。并且此模型的实现与工具无关,既可以用于Xilinx的FPGA,也可以迁移至Intel的FPGA。
这篇工作做出了如下贡献:
1.提出了一种基于图的程序表达方法,它既可以表示程序上下文,还可以包含设计参数流。
2.基于图神经网络设计了一个预测模型作为HLS评估工具的代替物,它可以在毫秒级得出一个设计点的质量,并且还开发了一些额外技术来帮助提升它的精度。
3.建立了一个自动化框架GNN-DSE,来建立一个关于FPGA设计的数据库,并用其中的数据来训练一个学习模型来预测一个设计的质量,最后在其上运行一个DSE来得到设计的最优点。
4.实验结果表明GNN-DSE框架不仅可以找到数据库内的FPGA设计最优点,还可以找到它未曾见过的其他设计的最优设计配置。
2 Background
这部分简单对以下几部分做了简单的介绍:
1.如何将程序表示成图:这里使用的是将程序经由LLVM编译之后生成的中间表示IR转化为图(CDFG图,Control and Data Flow Graph),图中的节点表示的是LLVM指令,图中的边表示的是指令之间的操作数。
2.对图神经网络及其几种变式(GCN/GAT)的基本工作原理做了简单的介绍和概括。
3.对Merlin编译器做了简单的介绍,对Merlin编译器支持的设计参数进行了归纳,这一点和AutoDSE中完全一样。
3 Problem Formulation
这部分对问题进行了形式化的定义,首先要构建一个预测模型,它可以尽可能精确地拟合HLS综合工具给出的结果,首先给出一个候选设计点(design candidate)的定义:
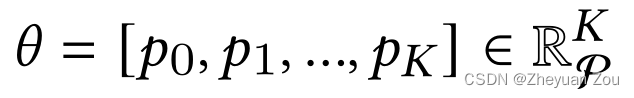
这个候选的定义和AutoDSE中的定义非常接近,有k个候选可以改变,它们的选择共同构成了一个候选(candidate)。标准HLS工具估测出的标准设计耗时和资源使用情况定义如下
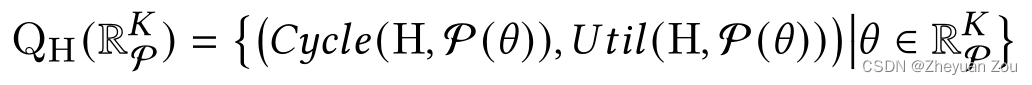
我们要构建的模型预测结果要足够接近HLS工具给出的真实值,这个目标的形式化表示如下:
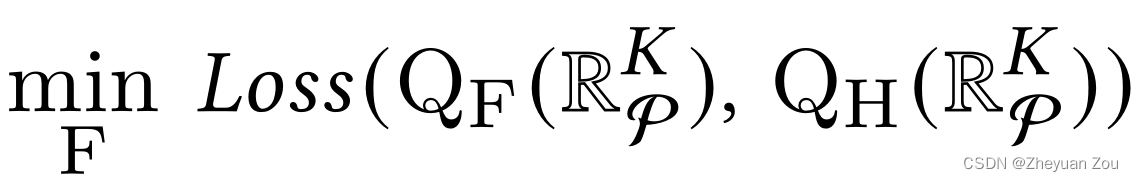
在上述预测模型的基础之上,我们就可以快速地进行HLS的自动设计空间探索,在这个过程中要充分考虑FPGA的可用资源并且同时保证设计的性能最高,这个目标的形式化描述如下:
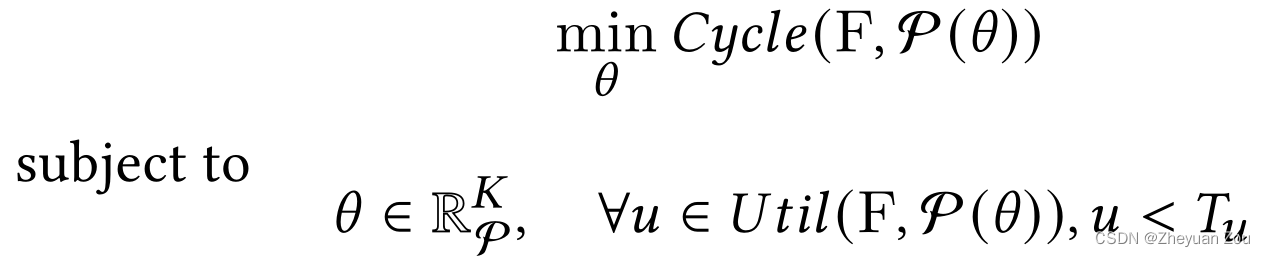
4 Related Work
这部分介绍了和本工作相关的之前其他工作,分析了它们的不足之处和它们与本文工作的对比,为后文提出本文架构做出了铺垫。
5 Our Proposed Methodology
这部分开始介绍GNN-DSE框架,首先给出GNN-DSE框架的整体框图:
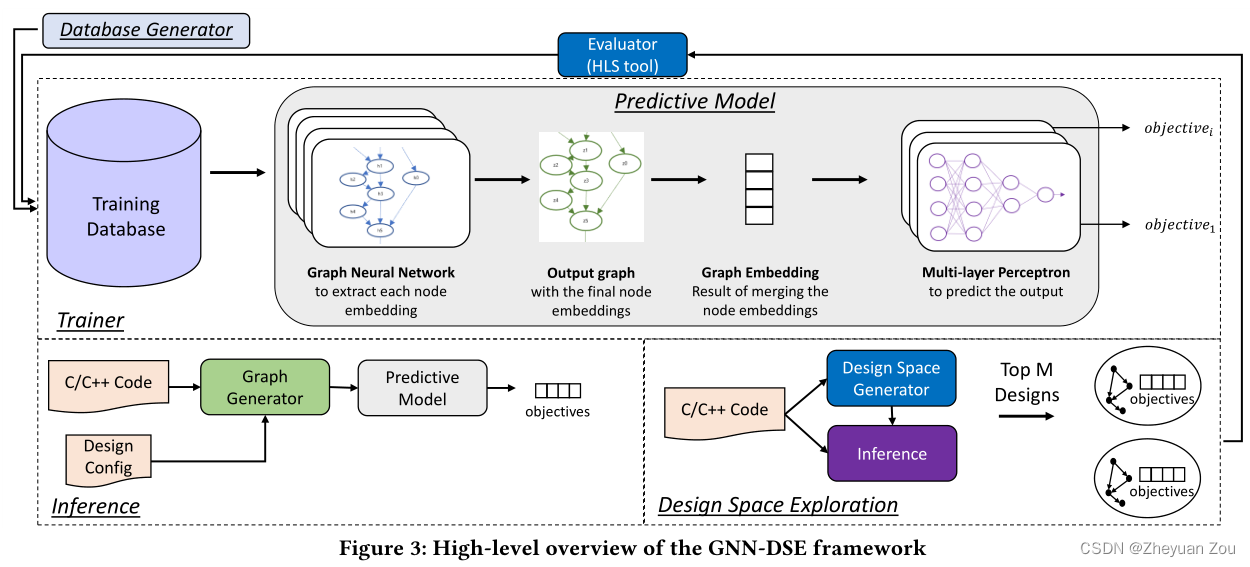
从上图中可以看出GNN-DSE框架有三种运行模式,训练模式、推理模式和设计空间探索模式。
在训练模式下,GNN-DSE会从数据库中获取真实设计样例并且使用真实的HLS评估数据来训练预测模型。模型会将每个数据库中的设计抽象成一张图,并将其交给图神经网络来提取图嵌入,最后通过一个多层感知机(MLP)来对各种指标进行预测,在这个过程中不断通过正确的结果对图神经网络进行更新,使得它可以更好地调整图嵌入(Graph Embedding)。
一旦训练阶段完成,GNN-DSE就可以进入推理阶段,GNN-DSE会将输入的C/C++程序传递给图生成器(Graph Generator),并输入当前配置(configuration),图神经网络会抽取当前设计的图嵌入并传递给MLP,最终得到当前配置的指标预测值。
在DSE阶段的运行策略和推理阶段一致,也是针对相应的输入给出指标的预测值,但是在完成DSE之后会挑选出Top M个设计点,使用真实的HLS工具再次实际运行这些配置点,并将其纳入数据库。这相当于是在推理时进一步丰富了数据库的知识范围,可以更好的对模型进行训练。
5.1 Database Generation
这部分讲述了GNN-DSE是如何生成初始训练数据库的,这部分生成数据库的工作借助了AutoDSE,它首先采用与AutoDSE完全一致的设计空间定义方法,也采纳了所有AutoDSE中的设计空间剪枝方法(这里的具体细节可以参考AutoDSE的Reading Note) 。
但这里存在一个问题,AutoDSE是一个追求“最优解”的自动设计空间探索工具,它会瞄着最好的设计点去探索。但是神经网络不能只学习好的设计点,它也要可以鉴别坏的设计点。为此,GNN-DSE的探索器在原有AutoDSE的探索器上做了扩展,它支持如下几种探索方式:
1.AutoDSE中的已有探索器,这个探索器专门用来找好的解
2.混合探索器,当AutoDSE的探索器的最优解效果每提升X%,探索器自动评估新设计点附近的P个邻居,X、P都是可以由用户指定的超参数,邻居的定义是配置点中仅有一个参数不同。
引入混合探索器的意义在于这样可以更加清晰地让神经网络学习到,改变不同的参数会对设计造成何种影响。
3.随机探索器,专门用来检测前两种探索器接触不到的配置点,增强模型的泛化性
以上三种探索器所搜索到的程序会交给图生成器来生成这个程序对应的图,配置则会和程序一起提交给Merlin编译器来生成最终的评估结果。<图、评估结果>组成的二元组会被纳入数据库,训练数据库会逐渐积累来自不同应用的设计实例,并使用它们来训练模型。
5.2 Program Representation
首先这部分提到CDFG图在程序表示上的不足:它会忽略掉操作数的精度和值。所以GNN-DSE取而代之使用PrograML来表示程序,如何将程序表示为一张图可以参考和学习一下PrograML这份工作。PrograML是构建在CDFG之上的,它为操作数分配独立的节点以补足缺失的信息。
PrograML接收LLVM IR作为输入,为程序生成一张包含数据、控制和调用信息的一张有向图。
但是为了对设计空间中的参数进行表示,GNN-DSE将PrograML生成的图做了扩展,使得其可以有效表示设计参数。

比如说对于上述这段简单的代码,扩展后的PrograML图会生成如下的一张图:
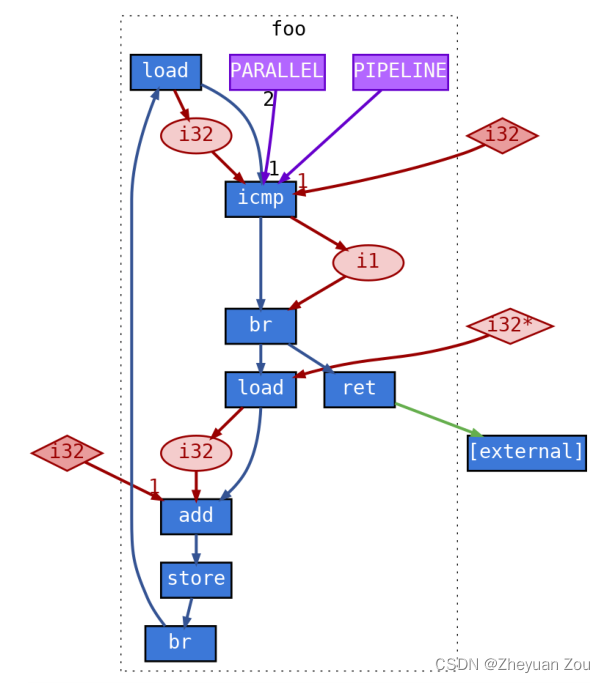
图中蓝色节点表示LLVM的指令(控制流),红色节点表示变量和常量数据(数据流),设计参数则以紫色节点的形式标出,连接在表示循环的特殊节点icmp上。
对于多层循环嵌套的情况,则必须要辨别出不同的设计参数被施加在哪一层循环上。这个信息首先可以从图中提取出来,因为图中包含了程序的控制流。另一方面也可以从节点所附加的信息中提取出来,因为节点中包含了LLVM的块ID号。
在扩展的PrograML图中节点和边包含的属性如下:

其中type、flow、position字段编号和其所代表的含义展示如下:

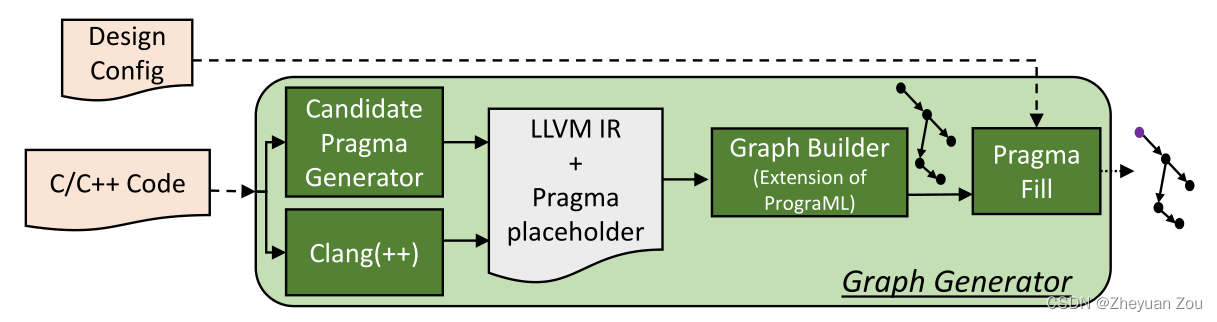
这一部分的最后对GNN-DSE中的图生成器做了简单的介绍,下面是它的简图:
图生成器的输入是C/C++代码,在读入设计代码之后会生成一张扩展的PrograML图,但是其中的候选参数全部由占位符占据着。随后根据5.1节所述的那样,按照不同的探索器探索到的参数按照顺序一一填入占位符中得到完整的图。
所以,在同一个kernel的不同配置情况下,只有填入的参数顺序是不一样的。
5.3 Predictive Model
这部分主要描述预测器的结构,首先给出GNN-DSE中使用的神经网络架构概览:
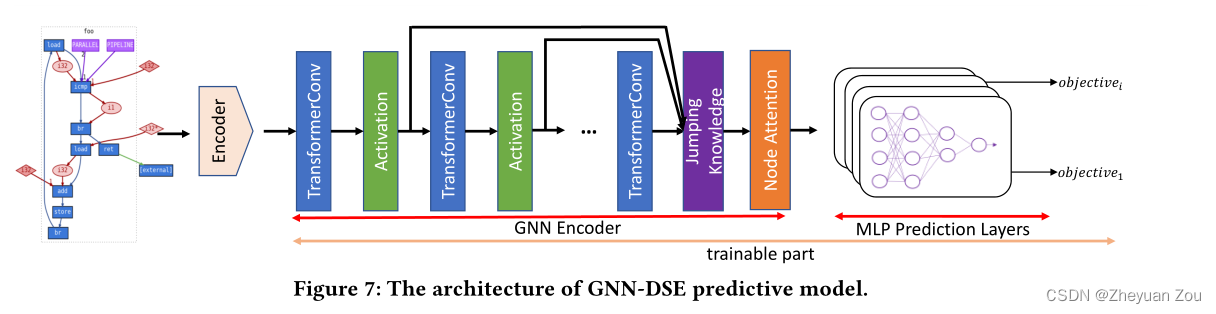
预测器首先接收上述使用扩展的PrograML表示的程序图作为输入,然后对其节点和边的属性进行编码。在对节点和边进行编码时,首先对数据库中所有属性和所有参数的可用选项都进行统计,并对它们的每一项(指所有属性和所有参数)都构造一个独热码(one-hot encoding),这样有助于模型对其中比较重要的影响因素分配更大的权重。
5.3.1 GNN Encoder
首先来看GNN的编码器部分,这部分由三个部分组成:
1.用于提取节点嵌入(node embeddings)的一系列堆叠的TransformerConv层
2.用于将不同层的邻居节点嵌入信息综合起来的跳跃知识网络(Jumping Knowledge Network)
3.用于将节点级嵌入结合起来的注意力机制,用来生成最终图级别嵌入
5.3.1.1 TransformerConv
传统的GCN和GAT都都忽略了边的嵌入信息(edge embedding),这里使用:
《 Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification》
论文中引入的TransformerConv算子对图的信息进行捕捉,这个算子目前已经被pytorch标准化,可以直接调用之。
简而言之TransformerConv算和GAT的想法非常接近,都有注意力因子,但是TransformerConv的注意力因子计算公式如下:
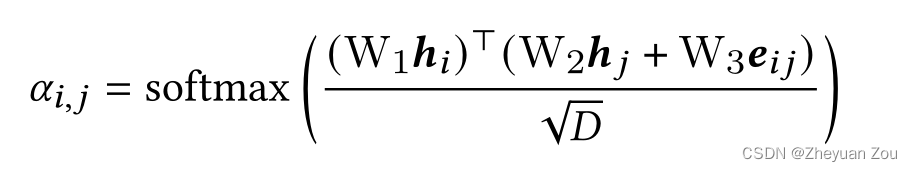
其中
W
1
,
W
2
,
W
3
W_1,W_2,W_3
W1,W2,W3都是可以学习的参数,注意这里面的
e
i
j
e_{ij}
eij引入了边嵌入,这使得TransformerConv可以兼顾到边信息,这对于处理PrograML生成的图是很有好处的,因为边也有很多属性(attributes)需要处理。另外,Transformer还有防止过度平滑(over-smoothing)的好处。
5.3.1.2 Jumping Knowledge Network
因为GNN的影响力是逐层传播的,所以一个节点在第一层只能学到1-近邻的信息,第二层才可以学到2-近邻的信息,以此类推。为了灵活的为每个节点选择不同的领域范围,在这里引入了跳跃知识网络(JKN),具体而言它接收前面所有层的嵌入并执行一个最大池化操作,让每个节点自己决定截止到哪个阶段的近邻对其影响最大,从中挑选一个最大值,而忽略此层以后的其他嵌入。
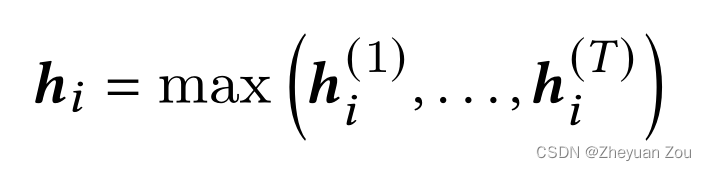
5.3.1.3 Node attention-based graph-level embedding generation
这里主要介绍了如何使用节点注意力机制为图生成最后的向量表示。
一般而言对于一张图可以使用将所有节点的embedding相加的形式来创建图的embedding,但是由于扩展的PrograML中有多种不同类型的节点,这种方式会默认将它们等同处理,这样显示是不科学的。
取而代之,这里引入了节点注意力机制来让模型自行学习不同的节点重要性。

通过引入节点注意力机制,模型可以成功地捕捉不同节点的重要性:
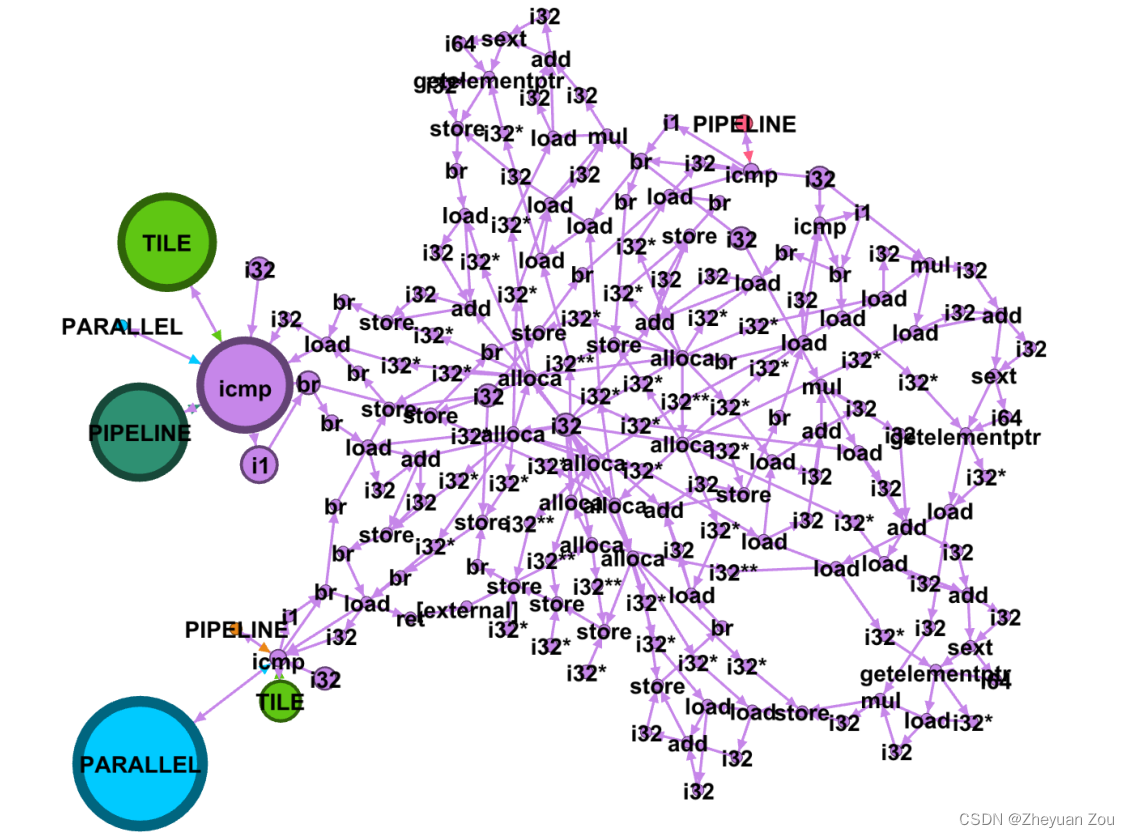
比如在上述的benchmark中,节点注意力机制捕捉到了相对重要的节点是参数节点(节点面积越大表示得到的注意力越多),这说明节点注意力机制起到了很好的作用。
5.3.2 MLP Prediction Layers
到了这一部分就是如何将上述步骤中生成的图嵌入(graph embedding)送入多层感知机MLP来对最后的参数点进行评估了。这个部分分为两个步骤:
1.首先区分一个方案是否可行,这是一个分类任务
GNN-DSE列举出了几种可能的无效设计点产生情况:
1.如果HLS在4小时之内无法综合完成,则此参数组合认为是无效的。
2.因为引用了高并行因子,HLS拒绝完成综合
3.设计参数的组合是非法的,这种情况下Merlin编译器会给出报告,GNN-DSE认为此种组合通通无效
2.根据已有的图嵌入信息进行目标值预测,这是一个回归问题
注意在进行回归时,针对预测的每一个目标值都创建一个MLP,而前面的GNN Encoder部分可以共用(这是因为不同预测目标之间存在相关性),当然也可以创建独立的GNN Encoder。
5.4 Design Space Exploration
这部分开始讲述GNN-DSE的设计空间探索模块,对于每个需要评估的设计配置,首先运行分类模型判断它们是否有效。如果有效就开始运行回归模型对目标值进行预测,如果有任何一项资源的利用情况超过0.8(阈值),GNN-DSE就会因为资源过度利用而拒绝此配置点,这是基于经验而得出的阈值。
在剩下的设计中,会选择出Top 10个设计交给HLS进行真实评估,这部分数据会被纳入数据库以方便模型运行的更好。
但是这部分同时也指出,虽然GNN-DSE可以在毫秒级对目标结果进行预测,但是因为庞大的设计空间,往往还是难以穷极。所以在执行DSE时首先设置了时间限制,另一方面还采用了启发式方法来首先评估最有可能的备选方案。这里提到,HLS更加擅长处理细粒度的循环优化,所以这里会将最内层循环的参数评估放在最前面,并且pipeline原语优先级高于parallel原语。如果两个循环之间存在依赖关系,那么会首先评估占主导地位的参数,比如嵌套循环中外层循环是pipeline内层循环是parallel的情况。
总而言之,GNN-DSE的DSE部分采纳了一些经验方法来优化探索的速度。
6 Evaluation
从略















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









