







2021-IJCA-Masked Label Prediction Unified Message Passing Model for Semi-Supervised Classification

GNN通过神经网络形成特征传播来进行预测,而LPA使用跨图邻接矩阵的标签传播来获得结果。然而,仍然没有有效的方法将这两种算法直接结合起来。
模型
作者使用Graph Transformer,联合使用标签嵌入将上述特征和标签传播结合在一起,构建UniMP模型。此外,引入了一种屏蔽标签预测策略来训练我们的模型,以防止标签泄漏问题。
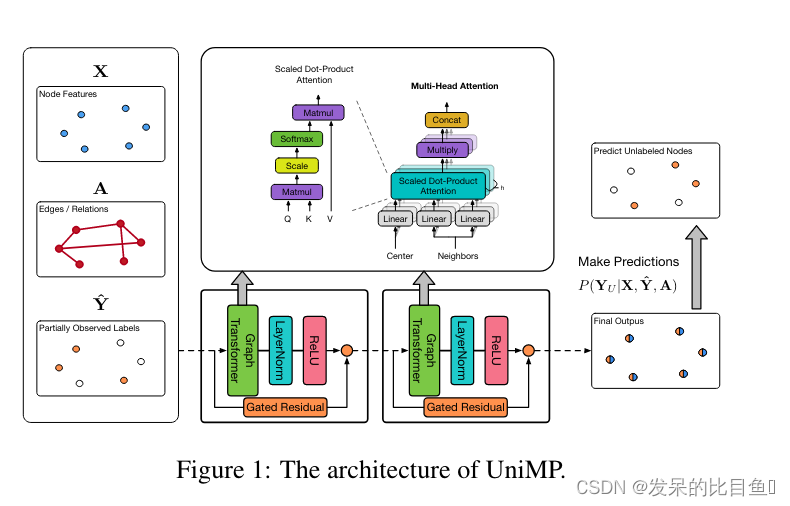
方法
已知定节点特征
H
(
l
)
=
{
h
1
(
l
)
,
h
2
(
l
)
,
…
,
h
n
(
l
)
}
H^{(l)}=\left\{h_1^{(l)}, h_2^{(l)}, \ldots, h_n^{(l)}\right\}
H(l)={h1(l),h2(l),…,hn(l)},计算从 j 到 i 的每条边的多头注意力:
q
c
,
i
(
l
)
=
W
c
,
q
(
l
)
h
i
(
l
)
+
b
c
,
q
(
l
)
k
c
,
j
(
l
)
=
W
c
,
k
(
l
)
h
j
(
l
)
+
b
c
,
k
(
l
)
e
c
,
i
j
=
W
c
,
e
e
i
j
+
b
c
,
e
α
c
,
i
j
(
l
)
=
⟨
q
c
,
i
(
l
)
,
k
c
,
j
(
l
)
+
e
c
,
i
j
⟩
∑
u
∈
N
(
i
)
⟨
q
c
,
i
(
l
)
,
k
c
,
u
(
l
)
+
e
c
,
i
u
⟩
\begin{gathered} q_{c, i}^{(l)}=W_{c, q}^{(l)} h_i^{(l)}+b_{c, q}^{(l)} \\ k_{c, j}^{(l)}=W_{c, k}^{(l)} h_j^{(l)}+b_{c, k}^{(l)} \\ e_{c, i j}=W_{c, e} e_{i j}+b_{c, e} \\ \alpha_{c, i j}^{(l)}=\frac{\left\langle q_{c, i}^{(l)}, k_{c, j}^{(l)}+e_{c, i j}\right\rangle}{\sum_{u \in N(i)}\left\langle q_{c, i}^{(l)}, k_{c, u}^{(l)}+e_{c, i u}\right\rangle} \end{gathered}
qc,i(l)=Wc,q(l)hi(l)+bc,q(l)kc,j(l)=Wc,k(l)hj(l)+bc,k(l)ec,ij=Wc,eeij+bc,eαc,ij(l)=∑u∈N(i)⟨qc,i(l),kc,u(l)+ec,iu⟩⟨qc,i(l),kc,j(l)+ec,ij⟩
其中,
⟨
q
,
k
⟩
=
exp
(
q
T
k
d
)
\langle q, k\rangle=\exp \left(\frac{q^T k}{\sqrt{d}}\right)
⟨q,k⟩=exp(dqTk)是幂级点积函数,
d
d
d 是每个头部的隐藏大小。对于第
c
c
c个头部注意,首先将源特征
h
i
(
l
)
h^{(l)}_i
hi(l)和远距特征
h
j
(
l
)
h^{(l)}_j
hj(l)转换为查询向量
q
c
,
i
(
l
)
∈
R
d
q_{c, i}^{(l)} \in \mathrm{R}^{\mathrm{d}}
qc,i(l)∈Rd和键向量
k
c
,
j
(
l
)
∈
R
d
k_{c, j}^{(l)} \in \mathrm{R}^{\mathrm{d}}
kc,j(l)∈Rd分别使用不同的可训练参数
W
c
,
q
(
l
)
,
W
c
,
k
(
l
)
,
b
c
,
q
(
l
)
,
b
c
,
k
(
l
)
W_{c, q}^{(l)}, W_{c, k}^{(l)}, b_{c, q}^{(l)}, b_{c, k}^{(l)}
Wc,q(l),Wc,k(l),bc,q(l),bc,k(l)
提供的边缘特征
e
c
,
i
j
e_{c,ij}
ec,ij 将被编码并添加到关键向量中,作为每个层的附加信息。在得到图的多头注意后,从远处的
j
j
j 到源
i
i
i 进行消息聚合:
v
c
,
j
(
l
)
=
W
c
,
v
(
l
)
h
j
(
l
)
+
b
c
,
v
(
l
)
h
^
i
(
l
+
1
)
=
∥
c
=
1
C
[
∑
j
∈
N
(
i
)
α
c
,
i
j
(
l
)
(
v
c
,
j
(
l
)
+
e
c
,
i
j
)
]
\begin{gathered} v_{c, j}^{(l)}=W_{c, v}^{(l)} h_j^{(l)}+b_{c, v}^{(l)} \\ \hat{h}_i^{(l+1)}=\|_{c=1}^C\left[\sum_{j \in N(i)} \alpha_{c, i j}^{(l)}\left(v_{c, j}^{(l)}+e_{c, i j}\right)\right] \end{gathered}
vc,j(l)=Wc,v(l)hj(l)+bc,v(l)h^i(l+1)=∥c=1C
j∈N(i)∑αc,ij(l)(vc,j(l)+ec,ij)
其中||是 c 个头注意力的连接操作多头注意矩阵取代了原始的归一化邻接矩阵作为消息传递的转移矩阵。
然后是残差连接,防止模型过度平滑
r
i
(
l
)
=
W
r
(
l
)
h
i
(
l
)
+
b
r
(
l
)
β
i
(
l
)
=
sigmoid
(
W
g
(
l
)
[
h
^
i
(
l
+
1
)
;
r
i
(
l
)
;
h
^
i
(
l
+
1
)
−
r
i
(
l
)
]
)
h
i
(
l
+
1
)
=
RELU
(
LayerNorm
(
(
1
−
β
i
(
l
)
)
h
^
i
(
l
+
1
)
+
β
i
(
l
)
r
i
(
l
)
)
)
\begin{gathered} r_i^{(l)}=W_r^{(l)} h_i^{(l)}+b_r^{(l)} \\ \beta_i^{(l)}=\operatorname{sigmoid}\left(W_g^{(l)}\left[\hat{h}_i^{(l+1)} ; r_i^{(l)} ; \hat{h}_i^{(l+1)}-r_i^{(l)}\right]\right) \\ h_i^{(l+1)}=\operatorname{RELU}\left(\operatorname{LayerNorm}\left(\left(1-\beta_i^{(l)}\right) \hat{h}_i^{(l+1)}+\beta_i^{(l)} r_i^{(l)}\right)\right) \end{gathered}
ri(l)=Wr(l)hi(l)+br(l)βi(l)=sigmoid(Wg(l)[h^i(l+1);ri(l);h^i(l+1)−ri(l)])hi(l+1)=RELU(LayerNorm((1−βi(l))h^i(l+1)+βi(l)ri(l)))
多头平均,删除线性变换
h
^
i
(
l
+
1
)
=
1
C
∑
c
=
1
c
[
∑
j
∈
N
(
i
)
α
c
,
i
j
(
l
)
(
v
c
,
j
(
l
)
+
e
c
,
i
j
(
l
)
]
h
i
(
l
+
1
)
=
(
1
−
β
i
(
l
)
)
h
^
i
(
l
+
1
)
+
β
i
(
l
)
r
i
(
l
)
\begin{gathered} \hat{h}_i^{(l+1)}=\frac{1}{C} \sum_{c=1}^c\left[\sum_{j \in N(i)} \alpha_{c, i j}^{(l)}\left(v_{c, j}^{(l)}+e_{c, i j}^{(l)}\right]\right. \\ h_i^{(l+1)}=\left(1-\beta_i^{(l)}\right) \hat{h}_i^{(l+1)}+\beta_i^{(l)} r_i^{(l)} \end{gathered}
h^i(l+1)=C1c=1∑c
j∈N(i)∑αc,ij(l)(vc,j(l)+ec,ij(l)]hi(l+1)=(1−βi(l))h^i(l+1)+βi(l)ri(l)
标签嵌入和传播
H
(
l
)
=
(
(
1
−
β
)
A
∗
+
β
I
)
l
(
X
+
Y
^
W
d
)
W
(
1
)
W
(
2
)
…
W
(
l
)
=
(
(
1
−
β
)
A
∗
+
β
I
)
l
X
W
+
(
(
1
−
β
)
A
∗
+
β
I
)
l
Y
^
W
d
W
H^{(l)}=\left((1-\beta) A^*+\beta I\right)^l\left(X+\widehat{Y} W_d\right) W^{(1)} W^{(2) \ldots W^{(l)}}=\left((1-\beta) A^*+\beta I\right)^l X W+\left((1-\beta) A^*+\beta I\right)^l \widehat{Y} W_d W
H(l)=((1−β)A∗+βI)l(X+Y
Wd)W(1)W(2)…W(l)=((1−β)A∗+βI)lXW+((1−β)A∗+βI)lY
WdW
其中模型近似分解为特征传播
(
(
1
−
β
)
A
∗
+
β
I
)
l
X
W
\left((1-\beta) A^*+\beta I\right)^l X W
((1−β)A∗+βI)lXW和标签传播
(
(
1
−
β
)
A
∗
+
β
I
)
l
Y
^
W
d
W
\left((1-\beta) A^*+\right.\beta I)^l \widehat{Y} W_d W
((1−β)A∗+βI)lY
WdW
屏蔽标签预测
在给定 X 和 A 的情况下监督训练其模型参数
θ
\theta
θ:
arg
max
θ
log
p
θ
(
Y
^
∣
X
,
A
)
=
∑
i
=
1
V
^
log
p
θ
(
y
i
^
∣
X
,
A
)
\underset{\theta}{\arg \max } \log p_\theta(\widehat{Y} \mid X, A)=\sum_{i=1}^{\widehat{V}} \log p_\theta\left(\widehat{y_i} \mid X, A\right)
θargmaxlogpθ(Y
∣X,A)=∑i=1V
logpθ(yi
∣X,A)
图神经代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import TransformerConv
class Transformer(torch.nn.Module):
#初始化
def __init__(self, hidden_channels):
super(Transformer, self).__init__()
torch.manual_seed(12345)
self.conv1 = TransformerConv(10, hidden_channels,dropout=0.5) #GCNConv更换为TransformerConv
self.conv2 = TransformerConv(hidden_channels, 2,dropout=0.5)#GCNConv更换为TransformerConv
#前向传播
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
#注意这里输出的是节点的特征,维度为[节点数,类别数]
return x
x = torch.randn(4, 10)
edge_index = torch.tensor([[0,0,0,1,1,2],[1,2,3,2,3,3]])
model = Transformer(36)
res = model(x, edge_index)
print(res)
















 2767
2767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











