







一、背景
目前NLP主流范式是在大量通用数据上进行预训练语言模型训练,然后再针对特定下游任务进行微调,达到领域适应(迁移学习)的目的。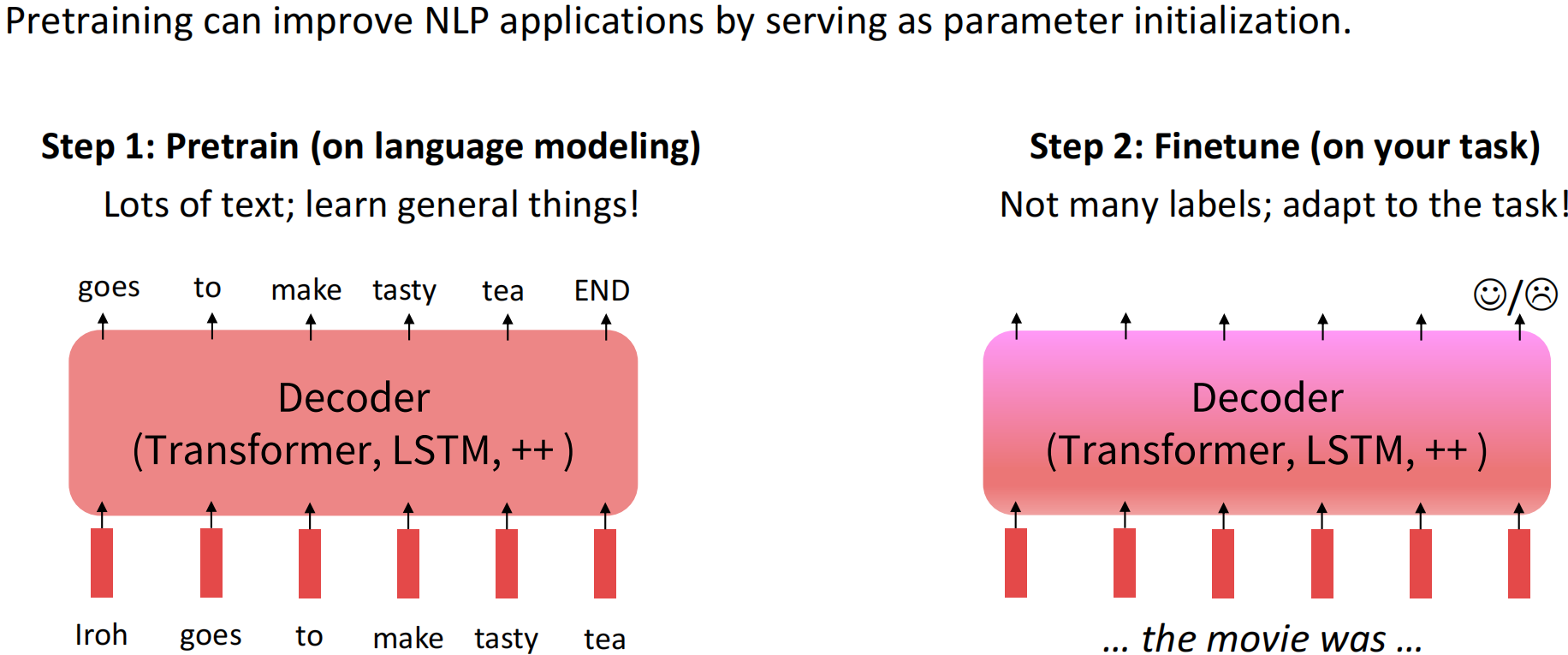
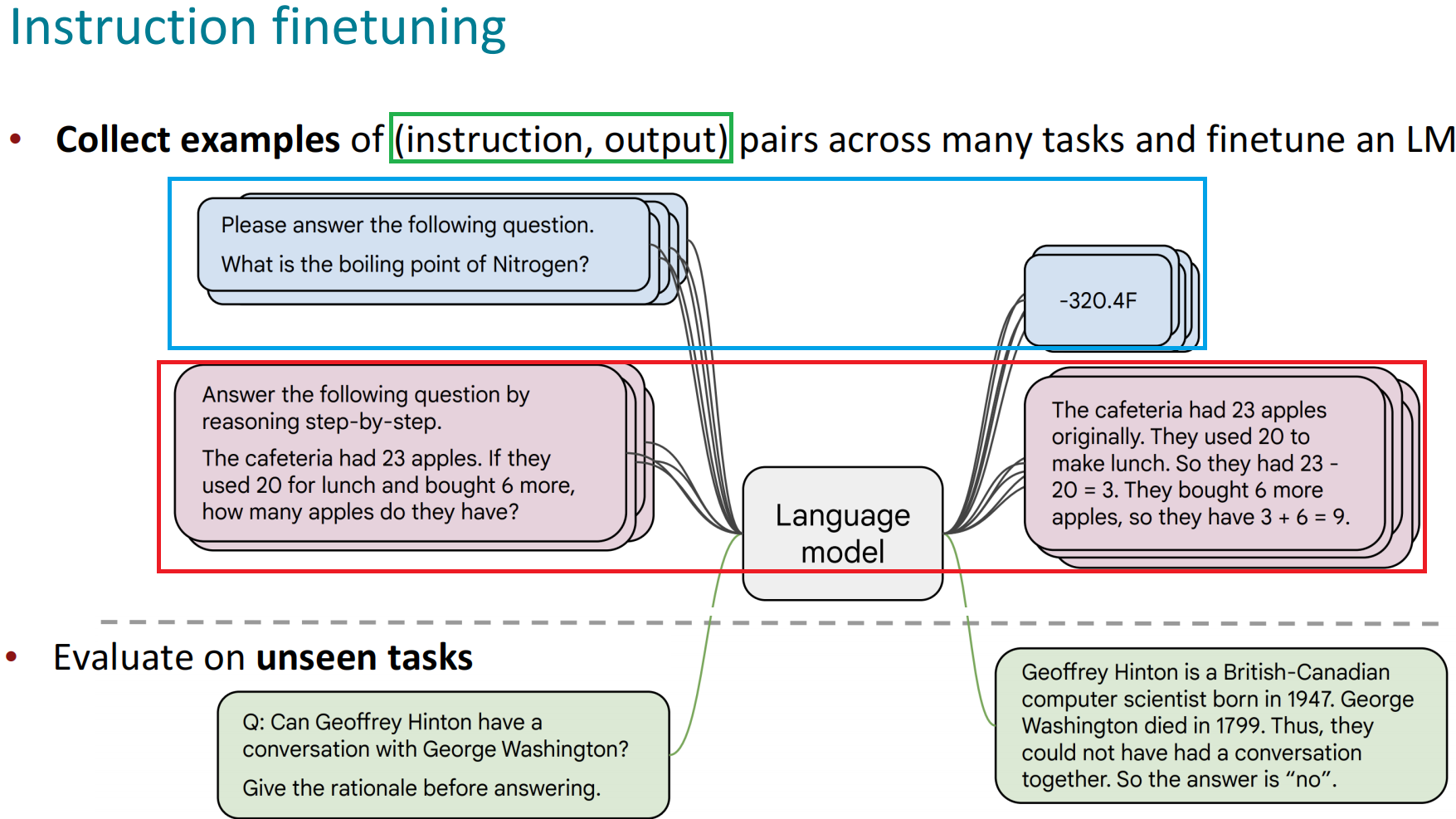
指令微调是预训练语言模型微调的主流范式
其目的是尽量让下游任务的形式尽量接近预训练任务,从而减少下游任务和预训练任务之间的Gap, 实现预训练语言模型适应下游任务,而非下游任务去适应模型。

指令微调的效果要优于基于Zero/Few-shot的提示词工程的上下文学习。
但随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。
例如:
- 全参微调Qwen1.5-7B-Chat预估要2张80GB的A800,160GB显存(需要确认一下😮)
- 全参微调Qwen1.5-72B-Chat预估要20张80GB的A800,至少1600GB显存😱。
而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难
当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数😓

为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。

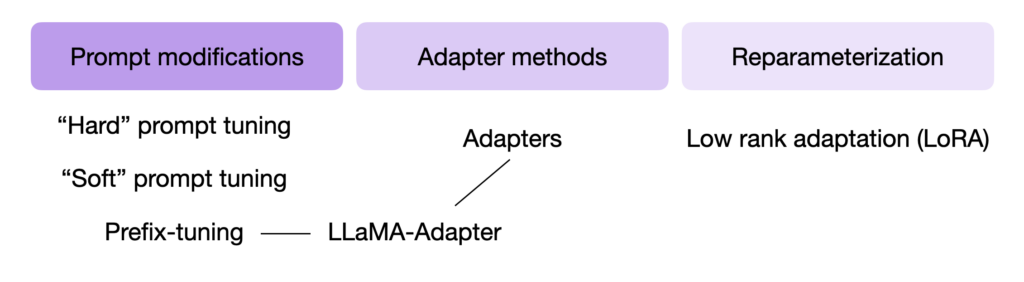
接下来将介绍如下4个PEFT方法(重点是主流的LoRA);
- Adatper Tuning
- Prompt Tuning
- Prefix Tuning
- LoRA
二、参数高效微调
2.1 Adapter Tuning
Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。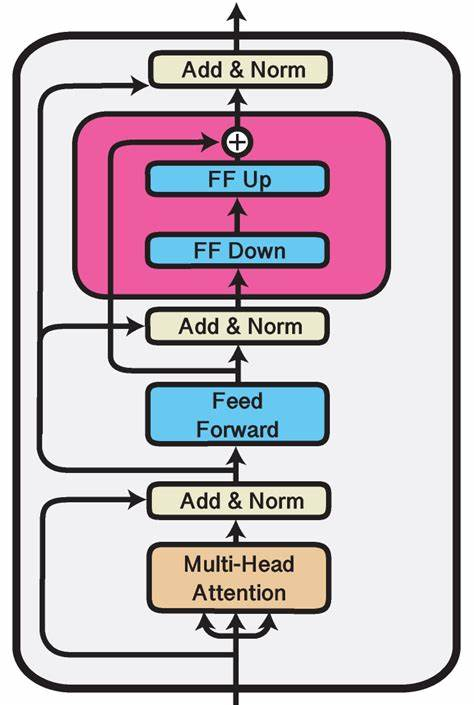
Adapter即插入的FF up + FF Down。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









