






LoRA核心思想
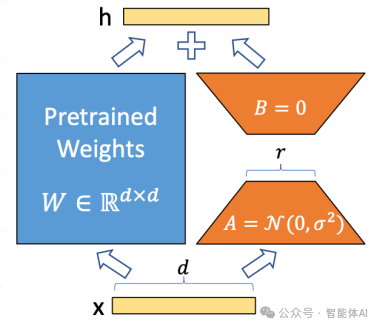
LoRA的核心思想是通过对预训练模型的权重矩阵进行低秩分解,在下游任务中仅对增量部分进行训练,从而减少训练成本。
使用LoRA微调Qwen2
1.指令集构建
指令微调是指使用特定格式的数据来微调模型,使其更好地理解和执行用户命令。数据通常包含instruction、input和output三部分。
指令数据格式
{
"instruction": "回答以下用户问题,仅输出答案。",
"input": "1+1等于几?",
"output": "2"
}
- instruction:用户指令,告知模型需要完成的任务。
- input:用户输入,完成指令所需的具体内容。
- output:模型应给出的输出。
除了指令集数据集之外还有多种不同格式的微调数据集,每种格式适用于特定的任务和微调目标。
当然,除了指令集数据集之外,还有多种不同格式的微调数据集,每种格式适用于特定的任务和微调目标。以下是一些常见的数据集格式及其应用场景:
1. 纯监督学习数据集(Supervised Fine-Tuning Datasets)
1.1 问答对(Question-Answer Pairs)
-
描述:包含问题和相应的答案,通常用于训练模型进行准确的回答生成。
-
示例:
{ "question": "地球有多重?", "answer": "地球的质量约为5.97 × 10²⁴千克。" }
1.2 翻译对(Translation Pairs)
-
描述:包含源语言文本和目标语言文本,用于训练机器翻译模型。
-
示例:
{ "source": "Hello, how are you?", "target": "你好,你怎么样?" }
1.3 文本分类(Text Classification)
-
描述:每个样本包含文本和相应的类别标签,用于情感分析、主题分类等任务。
-
示例:
{ "text": "这部电影真是太棒了!", "label": "积极" }
1.4 摘要生成(Summarization)
-
描述:包含长文和其简短摘要,用于训练模型生成文本摘要。
-
示例:
{ "article": "长篇文章内容...", "summary": "文章摘要。" }
2. 多轮对话数据集(Multi-turn Dialogue Datasets)
-
描述:包含多轮对话历史和相应的回复,适用于训练聊天机器人和对话系统。
-
示例:
{ "conversation": [ {"role": "user", "content": "你好!"}, {"role": "assistant", "content": "你好!有什么我可以帮忙的吗?"}, {"role": "user", "content": "今天天气怎么样?"}, {"role": "assistant", "content": "今天天气晴朗,气温适中。"} ] }
3. 序列标注数据集(Sequence Labeling Datasets)
3.1 命名实体识别(NER)
-
描述:每个单词或标记被标注为特定的实体类别,如人名、地点等。
-
示例:
{ "tokens": ["张三", "去了", "北京"], "labels": ["B-PER", "O", "B-LOC"] }
3.2 词性标注(POS Tagging)
-
描述:每个单词被标注为其对应的词性,如名词、动词等。
-
示例:
{ "tokens": ["我", "喜欢", "学习"], "labels": ["PRON", "VERB", "VERB"] }
4. 无监督学习数据集(Unsupervised Fine-Tuning Datasets)
- 描述:不需要明确的标签,仅使用大量文本数据进行预训练或微调,如自回归语言模型训练。
- 应用:适用于提升模型的语言理解和生成能力,但不针对特定任务。
5. 强化学习数据集(Reinforcement Learning Datasets)
5.1 人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)
-
描述:通过人类反馈(如评分、选择优选答案)来优化模型生成的内容。
-
流程:
- 收集反馈:人类对模型生成的多个候选答案进行评分或排序。
- 训练奖励模型:基于人类反馈训练一个奖励模型。
- 优化生成模型:使用策略优化算法(如PPO)根据奖励模型优化生成模型。
-
示例:
-
初始对话生成:
{ "prompt": "请解释量子力学。", "responses": [ "量子力学是研究微观粒子行为的物理学分支。", "量子力学探讨物质和能量在微观尺度上的性质和相互作用。" ] } -
人类反馈:
{ "prompt": "请解释量子力学。", "preferred_response": "量子力学探讨物质和能量在微观尺度上的性质和相互作用。" }
-
6. 指令-响应数据集(Instruction-Response Datasets)
-
描述:类似于指令集数据集,包含明确的指令和期望的响应,用于训练模型执行特定任务。
-
示例:
{ "instruction": "将以下英文句子翻译成中文。", "input": "The quick brown fox jumps over the lazy dog.", "output": "敏捷的棕色狐狸跳过懒狗。" } -
区别:虽然与指令集数据集类似,但可以更加多样化,涵盖不同类型的指令和任务。
7. 多模态数据集(Multimodal Datasets)
-
描述:包含多种模态的数据,如文本、图像、音频等,用于训练能够处理多种数据类型的模型。
-
示例:
{ "image_url": "http://example.com/image.jpg", "caption": "一只在草地上奔跑的狗。" } -
应用:适用于图像描述生成、视觉问答等任务。
8. 生成式任务数据集(Generative Task Datasets)
8.1 文本生成(Text Generation)
-
描述:提供部分文本作为提示,训练模型生成后续内容。
-
示例:
{ "prompt": "从前有一只小狐狸,它", "completion": "在森林中快乐地生活着。" }
8.2 编程代码生成(Code Generation)
-
描述:包含代码片段和相应的描述或注释,用于训练模型生成代码。
-
示例:
{ "description": "编写一个函数,计算两个数的和。", "code": "def add(a, b):\n return a + b" }
9. 知识图谱数据集(Knowledge Graph Datasets)
-
描述:包含实体及其关系,用于训练模型进行知识推理和问答。
-
示例:
{ "subject": "爱因斯坦", "predicate": "出生地", "object": "德国乌尔姆" }
10. 对抗性数据集(Adversarial Datasets)
-
描述:设计特定的挑战性样本,测试和提升模型的鲁棒性。
-
示例:
-
含有歧义的句子:
{ "sentence": "我看到她带着望远镜。", "question": "谁带着望远镜?", "answer": "她带着望远镜。" }
-
2.数据格式化
为了训练LoRA,数据需要经过格式化和编码。
主要任务包括:
- 编码输入和输出文本:将自然语言文本转换为模型可以处理的数字形式(即
input_ids和labels)。 - 处理注意力掩码(Attention Mask):指示模型在处理输入时应关注哪些位置。
- 管理序列长度:确保输入序列不超过模型的最大处理长度,必要时进行截断。
- 构建训练所需的字典结构:将处理后的数据组织成字典,以便后续训练步骤使用。
2.1定义预处理函数
该函数将每个样本的instruction和input编码为input_ids,output编码为labels。
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
# 构建指令部分的编码
instruction = tokenizer(
f"<|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n"
f"<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n"
f"<|im_start|>assistant\n",
add_special_tokens=False
)
# 构建输出部分的编码
response = tokenizer(f"{example['output']}", add_special_tokens=False)
# 合并输入和输出的input_ids,并添加pad_token_id作为结束标志
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]# 这里相加是拼接
# 合并注意力掩码,并作为pad_token_id添加关注标记(1)
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # eos token 也需要关注
# 构建labels,instruction部分的labels设置为-100,表示在计算损失是忽略这部分损失
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
# 如果序列长度超过MAX_LENGTH,则进行截断
if len(input_ids) > MAX_LENGTH: # 截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
# 将处理后的input_ids、attention_mask和labels组织成一个字典,供后续训练使用。
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
编码指令部分
instruction = tokenizer(
f"<|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n"
f"<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n"
f"<|im_start|>assistant\n",
add_special_tokens=False
)
模板构建:使用特定的模板将 system、user 和 assistant 三部分的信息整合到一起。
<|im_start|>system\n...<|im_end|>:定义系统角色的指令,告知模型其角色和任务。<|im_start|>user\n...<|im_end|>:包含用户的指令和输入。<|im_start|>assistant\n:预留模型生成响应的部分。
分词:使用 tokenizer 对构建的字符串进行分词,得到 input_ids 和 attention_mask。
参数说明:
add_special_tokens=False:不自动添加额外的特殊token,因为模板中已经手动添加了<|im_start|>和<|im_end|>。
在使用Transformer模型进行文本处理事,原始的自然语言文本需要被转换为模型能够理解和处理的数值形式。这一转换过程设计两个关键步骤:
- Tokenization(分词):将文本拆分为更小的单元(如单词、子词或字符),并将这些单元映射为唯一的整数标识符,即
input_ids。 - 生成
attention_mask:创建一个掩码,指示模型在处理输入时应该关注哪些位置,哪些位置应被忽略(如填充部分)。
例如当有如下句子:
Hello, world!
使用分词器处理后,可能得到以下tokens和对应的input_ids:

因此,input_ids 为 [7592, 1010, 2088, 999]。
attention_mask 是一个与 input_ids 长度相同的二进制(或布尔)向量,用于指示模型在计算注意力(Attention)时应关注哪些位置。具体而言:
- 1(或
True):表示该位置的 token 应被模型关注。 - 0(或
False):表示该位置的 token 是填充(Padding),应被模型忽略。
attention_mask 的主要作用是避免模型在处理填充部分时产生无意义的计算,从而提高计算效率和模型性能。
attention_mask 的示例
继续以上面的示例,假设 input_ids 为 [7592, 1010, 2088, 999, 0, 0, 0](其中 0 为 pad_token_id),则对应的 attention_mask 为 [1, 1, 1, 1, 0, 0, 0]。
在 process_func 中,attention_mask 是通过合并指令部分和响应部分的 attention_mask 后,再添加 1(表示 pad_token_id 也应被关注)生成的:
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
这确保了模型在生成响应时能够正确关注填充部分。
2.2Prompt模板
Qwen2使用的Prompt Template格式如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
你是谁?<|im_end|>
<|im_start|>assistant
我是一个有用的助手。<|im_end|>
该模板用于构建输入和输出的格式,使模型更好地理解对话上下文。
角色定义
-
<|im_start|>system ... <|im_end|>:
- 定义系统角色的指令,设定模型的基本行为和身份。例如,“You are a helpful assistant.” 告诉模型它是一个有用的助手。
-
<|im_start|>user ... <|im_end|>:
- 包含用户的输入和指令。例如,“你是谁?” 是用户的问题。
-
<|im_start|>assistant ... <|im_end|>:
- 模型应生成的回答部分。例如,“我是一个有用的助手。” 是模型对用户问题的回答。
作用
- 上下文构建:通过明确的角色和对话结构,帮助模型理解对话的上下文和预期的回应方式。
- 一致性:确保训练数据的一致性,使模型在面对类似结构的输入时能够生成符合预期的输出。
格式优势
- 明确分隔:使用
<|im_start|>和<|im_end|>明确分隔不同的对话部分,便于模型区分和学习。 - 灵活性:模板可根据具体需求进行调整,例如添加更多角色或复杂的指令。
3.定义LoRA配置
使用 peft 库中的 LoraConfig 类来配置 LoRA 微调的参数。
from peft import LoraConfig, TaskType
config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 模型的最后一层要匹配相应的分类器
target_modules=[
"q_proj", "k_proj", "v_proj",
"o_proj", "gate_proj", "up_proj", "down_proj"
],# 指定哪些模块需要学习
inference_mode=False, # 训练模式
r=8, # LoRA 秩
lora_alpha=32, # LoRA alpha
lora_dropout=0.1 # Dropout 比例
)
参数说明
- task_type:任务类型,此处为因果语言模型(Causal LM)。
- target_modules:需要训练的模型层名称,主要是
attention部分的层。不同模型层名称可能不同,可传入数组、字符串或正则表达式。 - r:LoRA 的秩,决定了低秩矩阵的维度。
- lora_alpha:LoRA 的缩放因子,通常用于控制权重更新的幅度。缩放比例为
lora_alpha / r,在此配置中为4。 - lora_dropout:在 LoRA 层引入的 Dropout 比例,用于防止过拟合。
4.自定义TrainingArguments参数
使用 transformers 库中的 TrainingArguments 类来配置训练参数。以下是常用参数的说明和示例配置:
from transformers import TrainingArguments
args = TrainingArguments(
output_dir="./output/Qwen2_instruct_lora", # 模型输出路径
per_device_train_batch_size=4, # 每设备训练批次大小
gradient_accumulation_steps=4, # 梯度累加步数,适用于显存较小的情况
logging_steps=10, # 日志记录步数
num_train_epochs=3, # 训练轮数
save_steps=100, # 模型保存步数
learning_rate=1e-4, # 学习率
save_on_each_node=True, # 是否在每个节点保存模型
gradient_checkpointing=True # 启用梯度检查点,减少显存占用
)
参数详细说明
- output_dir:微调后模型的保存路径。
- per_device_train_batch_size:每个设备(如 GPU)的训练批次大小。
- gradient_accumulation_steps:梯度累加步数,通过累积多个小批次的梯度来模拟更大的批次,有助于在显存有限的情况下进行训练。
- logging_steps:每隔多少步记录一次训练日志。
- num_train_epochs:训练的总轮数。
- save_steps:每隔多少步保存一次模型。
- learning_rate:优化器的学习率。
- save_on_each_node:在分布式训练中,是否在每个节点保存模型。
- gradient_checkpointing:启用梯度检查点,减少显存占用,但会增加计算开销。
5.使用Trainer进行训练
使用 transformers 库中的 Trainer 类进行模型训练。以下是具体步骤:
5.1准备训练数据
假设已经对数据集进行了格式化,并存储在 tokenized_id 变量中
5.2定义数据整理器
使用 DataCollatorForSeq2Seq 进行数据整理,确保输入数据的批次统一。
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True)
5.3初始化Trainer
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=data_collator,
)
5.4开始训练
trainer.train()
6.加载LoRA权重进行推理
LoRA优点
特征
- LoRA冻结了预训练模型权重,仅在每个Transformer层中注入可训练的低秩分解矩阵,大大减少了下游任务的可训练参数数量。
- 相比于全参微调,LoRA可以将可训练参数减少10000倍,GPU内存需求减少3倍,同时保持甚至超越全参数微调的模型质量。
- LoRA的关键思想是假设模型适应过程中权重的变化具有低“内在秩”
多LoRA部署
vLLM是一个用于高效部署和服务大型语言模型(LLM)的开源工具。它提供了对LoRA(Low-Rank Adaptation)模块的支持,使您可以在不修改原始模型参数的情况下,通过添加低秩矩阵来微调模型。这种方法不仅节省了存储空间,还提高了微调的效率。
当需要在同一个基础模型上部署多个LoRA微调时,vLLM允许您同时加载和应用多个LoRA模块。这对于需要提供多种定制化模型服务的场景非常有用。
命令解释
您提供的命令如下:
vllm serve {你的模型地址} --enable-lora --lora-modules {lora1的地址} {lora2的地址}
{你的模型地址}:这是您要加载的基础模型,可以是本地路径或模型仓库(如Hugging Face)的模型名称。--enable-lora:启用LoRA支持,告诉vLLM在加载基础模型后,还需要加载LoRA模块。--lora-modules {lora1的地址} {lora2的地址}:指定要加载的一个或多个LoRA模块的路径或名称。
工作原理
- 加载基础模型:vLLM首先加载指定的基础模型。
- 加载LoRA模块:在启用LoRA支持的情况下,vLLM会依次加载指定的LoRA模块。
- 合并模型参数:vLLM将LoRA模块的参数与基础模型的参数进行合并,但不会修改基础模型的原始参数。
- 启动服务:vLLM启动API服务,您可以通过API调用来使用加载了LoRA微调的模型。
代码示例
以下是如何使用vLLM的Python接口来加载和使用多个LoRA模块的示例。
from vllm import LLM
# 基础模型地址
base_model_path = "your-base-model"
# LoRA模块地址列表
lora_paths = ["path/to/lora1", "path/to/lora2"]
# 初始化LLM对象,启用LoRA,并加载LoRA模块
llm = LLM(
model=base_model_path,
enable_lora=True,
lora_modules=lora_paths
)
# 示例输入文本
input_text = "请生成一段关于人工智能的文章。"
# 指定使用的LoRA模块(假设API支持)
# 这里需要根据实际的vLLM版本和API来调整
output1 = llm.generate(input_text, lora_module="path/to/lora1")
output2 = llm.generate(input_text, lora_module="path/to/lora2")
print("使用LoRA模块1的输出:", output1)
print("使用LoRA模块2的输出:", output2)
注意事项
- LoRA模块的选择:在实际使用中,您需要有一种方式来指定在生成时使用哪个LoRA模块。这可能需要在API请求中添加参数,或者在应用逻辑中进行区分。
- 兼容性:确保您的LoRA模块与基础模型兼容,即它们是在同一个基础模型上训练的。
- 资源管理:加载多个LoRA模块会占用更多的内存和计算资源,请根据实际情况进行配置。
总结
vLLM通过支持同时加载多个LoRA模块,使您能够在一个基础模型的框架下提供多种微调模型的服务。这样,您可以灵活地根据不同的应用场景,使用不同的LoRA微调模型,而无需为每个微调模型单独部署一个完整的基础模型实例。
多LoRA性能
为了验证多Lora的性能,我们特意用Llama3-8b模型,L20GPU显卡进行了压测对比,数据如下

可见,多Lora对推理的吞吐与速度的影响几乎可以忽略。
限制

- 共享基础大模型:所有希望一起部署的多个业务场景必须使用相同的基础大模型。这是因为在多LoRA部署是,基础大模型只需要加载一份,以支持多个LoRA的推理。
- LoRA秩的限制:如果使用vLLM进行多LoRA部署,微调训练是,LoRA的秩R的值不要超过64。大多数情况下,这个条件都是可以满足的,但是在特定场景中需要注意着一点。
LoRA部署提供服务
- 量化(GPTQ、AWQ、SqueezeLLM、FP8 KV Cache)
- 前缀缓存
- 多LoRA
- 张量并行

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









