







5月13日,火山引擎FORCE LINK AI创新巡展上,Seed团队推出的视觉-语言多模态大模型Seed1.5-VL,以仅20B激活参数的架构,横扫60个评测基准中的38项SOTA,在视频理解、GUI智能体等关键指标上直接叫板谷歌Gemini 2.5 Pro,而推理成本仅为对方的1/3。

这款新的模型,正在重新定义AI性价比的极限。
技术突破:从拼参数到炼架构
Seed1.5-VL的颠覆性首先体现在全能战士般的多模态理解力。上传一张画作,它能全面分析画面元素,自动识别出作品的作者、艺术风格、画面元素、思想内涵等。
面对包含多个人物的图片,Seed1.5-VL 能精准识别观众、棒球、座椅、围栏等画面元素,并给出正确坐标:
【视频来源于网络,侵删】
更令人惊叹的地方是在处理公务员图形推理题时,Seed1.5-VL仅用10秒便破解黑白方块「去同存异」的叠加规律。
这种融合视觉定位、语义解析、数学推理的复合能力,是传统单模态AI难以企及的高度。
而在视频理解领域,Seed1.5-VL则展现出侦探般的敏锐度。
输入一段监控视频询问「小猫今天干了哪些坏事」,它能快速标记出抓挠沙发、打翻水杯等现场,并生成带时间戳的“案情报告”:
【视频来源于网络,侵删】
这种时序推理能力若延伸到商业场景,自动分析6小时直播中的高光片段,将不是难题。
而Seed1.5-VL的杀手锏多模态智能体功能,可以让AI能像人类一样操作PC界面:在测试中成功完成点击点赞按钮、填写表单等GUI交互任务,可以为自动化测试、智能客服等场景打开新的可能。
Seed1.5-VL采用三件套设计:
532M参数的SeedViT视觉编码器处理任意比例图像,MLP适配器对齐多模态表征;
20B参数的MoE架构语言模型专注复杂推理。这种模块化组合既保证性能,又将推理成本压至每千token输入0.003元,输出仅0.009元,比同类模型降低67%;
训练策略上独创渐进式解锁:先冻结视觉编码器训练MLP对齐特征,再解冻所有参数进行大规模预训练,最后引入强化学习优化长链推理。
这种精细调优,让模型在3T token的多模态数据中提炼出了极致效率。
与谷歌Gemini 2.5 Pro的对比,虽然Gemini支持6小时长视频处理和音视代码融合,但Seed1.5-VL在GUI智能体任务中拿下3项SOTA,且推理成本仅为前者的1/3。
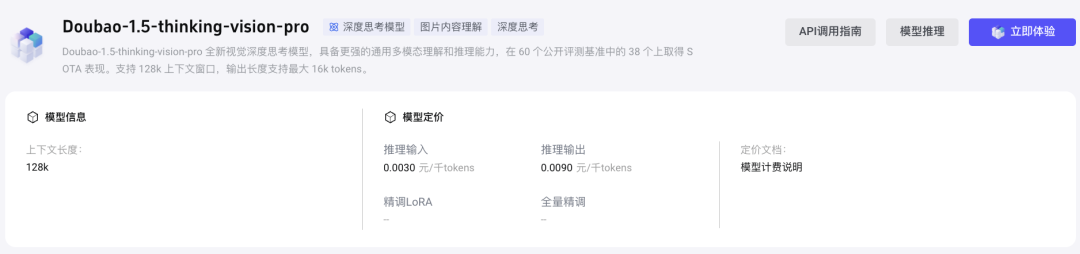
当然,Seed1.5-VL在复杂空间关系解释、长视频动作时序推理等方面仍然存在短板,例如面对华容道谜题时可能产生错误假设。但字节跳动已经开放API接口,并承诺每月迭代模型。
据透露,该模型已开始在抖音内容审核、飞书智能助手等场景试点,预计半年内接入全线产品。
当多模态理解成本大幅降低,AI绘画、数字人、智能客服等赛道将迎来洗牌。特别是短视频领域,自动生成高质量UGC内容的技术,可能颠覆现有内容生产逻辑。


















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









