







模型结构图:
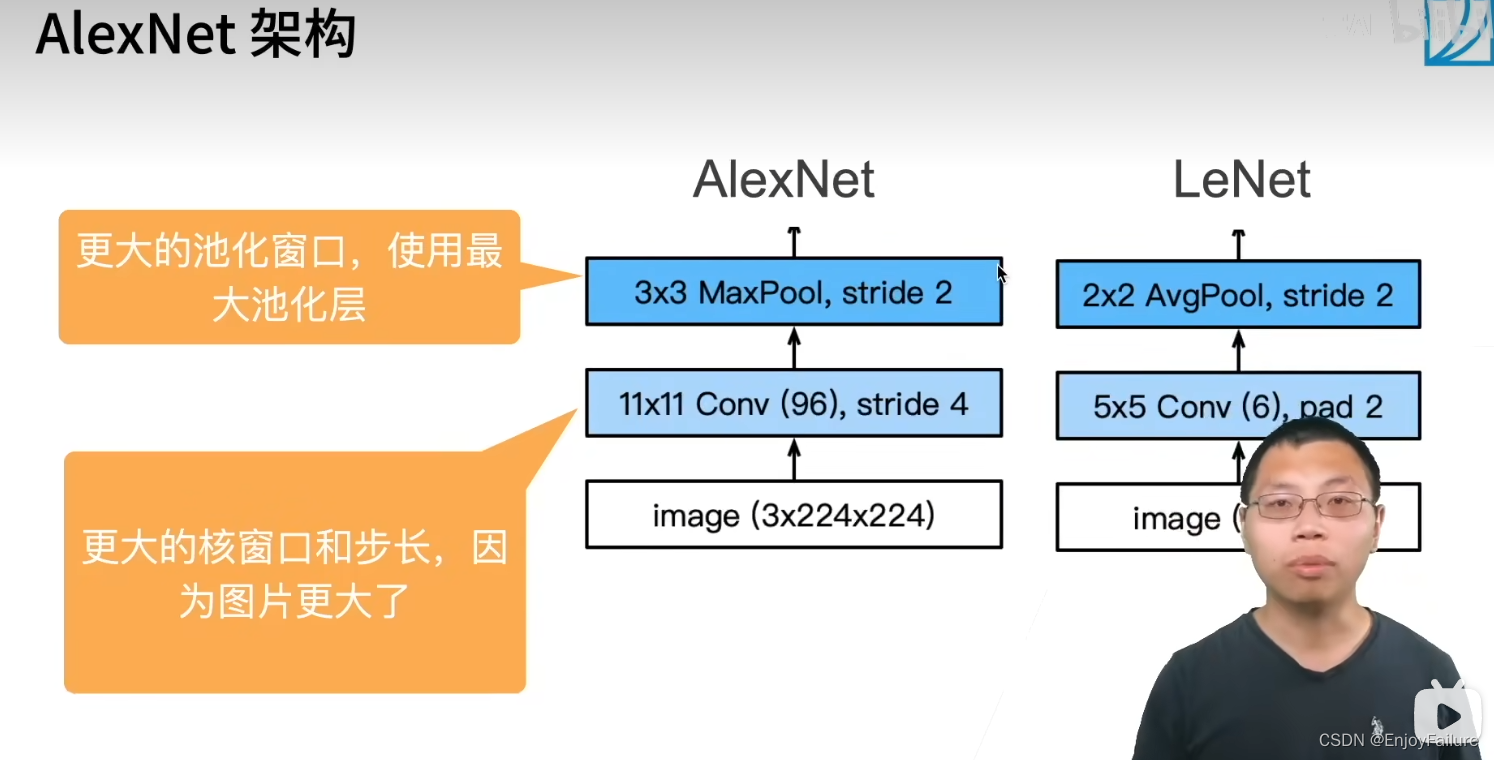
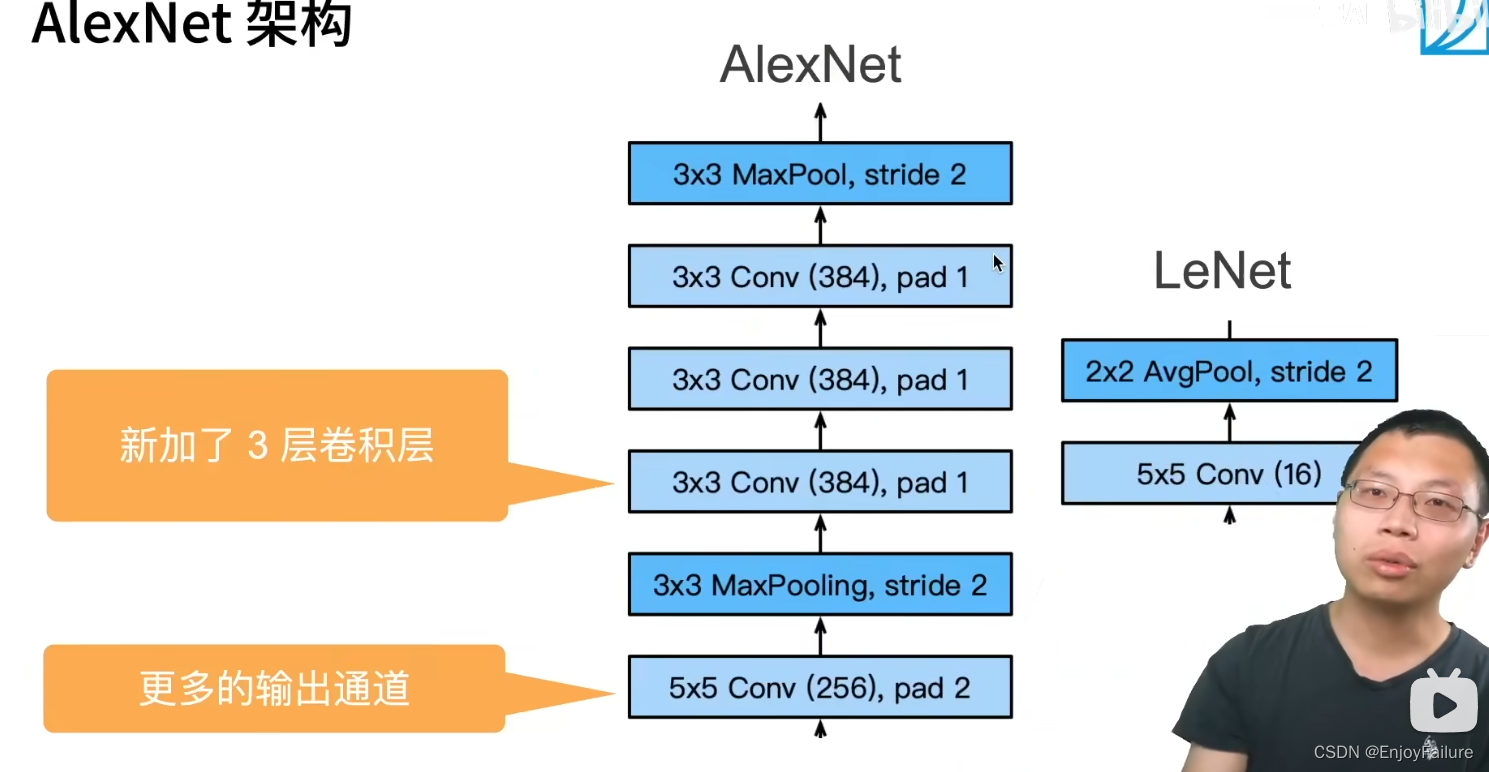
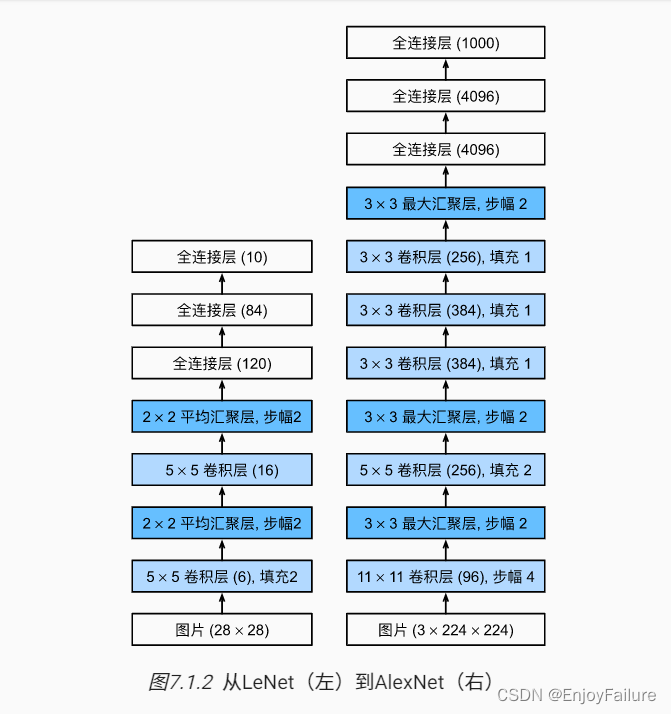
与LeNet相比,AlexNet具有以下新加入的东西:
1.激活函数选择了ReLU函数,跟sigmoid相比,其缓解了梯度消失的现象
2.加入了丢弃法(dropout)
3.池化层选择了最大池化层
4.数据增强操作,将不同情况下的数据也加入到训练中(例如不同的色温、不同的亮度、随机截取一部分作为输入等),给模型”脱敏“,因为卷积对位置敏感
Pytorch代码
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))














 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









