









目录
2.2 python2.x解释器对.py文件解码解的实际上是unicode对象
2.3 python2.x解释器默认编码方式为ASCII编码
3.2 对str对象和unicode对象误用encode和decode函数
对于IO过程中的编码解码,核心一点就是解码方式和编码方式保持一致,比如用utf8编码的文件,读取后就应该用utf8方式解码。在python2.x中,所有被解码后得到的对象,都是Unicode对象。所以本文要讲的是在源代码中的编码解码问题,这是很多程序员容易出错的地方。
1 python执行程序哪里会涉及到编码解码?
python程序从源代码到被执行这个过程,有两个地方涉及到编码和解码。首先是我们在编辑器中写入源代码后,被保存成.py文件这个过程,编辑器会依据某种编码方式对源代码进行编码,源代码被编码成字节码后保存到.py文件中;然后当程序文件被python解释器执行的时候,python解释器会对.py文件中的字节码进行解码,这个过程python会使用解释器中设定的解码方式对其进行解码。总体过程如下图所示。
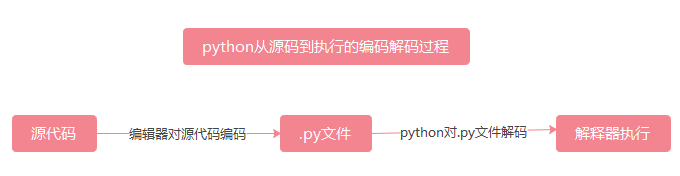
2 预备知识:python2.x程序中的字符类型及编码处理
2.1 2.x中的str和unicode
在分析具体的问题之前,还需要注意python2.x对字符类型的怪异处理。在python2.x中,我们通常所理解的字符串类型并不是python2.x中的str,而是unicode对象。对于ascii字符,可以认为str和unicode是等价的,那是因为2.x中对str和unicode对于ascii字符做了一些对用户封装的底层处理,这些处理使得对于ascii字符来说,str是正常的str,但是一旦出现非ascii字符,这种底层处理便无能为力,会出现报错。这里如何定义正常的str?我们通常所理解的字符串,其应该是字符的最高层的人类可理解的形式,是字节码解码后的对象,也是为了得到字节码而被编码的直接对象;但是在2.x中不是这样的,在2.x中,真正的我们所理解的具有正常字符串那种特性的对象是unicode对象,不是str对象。即在2.x中,字节码解码后得到的对象是unicode对象,而且unicode对象也是为了得到字节码而被直接编码的对象,而不是str对象。实际上,str对象在2.x中,底层是一个字节码序列。但是2.x为了让str看起来和我们正常所理解的字符串一样,其实际上在底层对用户实现了进一步的封装。所以,当我们尝试对一个str对象进行encode时,由于本质上其是一个字节码,而且2.x直接被编码的对象是unicode对象,所以2.x中python会先对str使用默认的ascii编码方式对str进行decode,得到unicode对象,然后再使用ascii编码方式对unicode对象进行encode,得到str.encode的结果,这里无论encode函数中指定的编码方式是什么,都需要经历ascii编码对str字节decode的过程,然后对得到的unicode进行encode时,才会使用最初encode函数中参数指定的编码方式。
如下图所示,当我们对一个str对象调用encode函数,并指定编码方式为utf8,我们所期望的过程是虚线所示的过程;但是对于2.x,实际对用户封装的过程是上面的实线过程:先使用ascii编码方式对str解码得到unicode对象,然后再直接对unicode对象使用utf8方式进行编码得到最终的字节码。

所以,2.x中,str不是我们所通常认为的字符串对象,其实际上是一个字节码序列,unicode对象才在2.x中扮演了我们通常所理解的字符串的角色:即直接被编码的对象和解码后得到的对象。此外,为了让str看起来是正常的字符串类型,2.x对str的encode函数做了上述的封装。而且,为了使得被解码后的对象看起来也是str,2.x还让对于ascii码的str和unicode在==运算符下返回True的结果。这样,对于ascii字符来说,str就具备了正常的特点和行为,但我们要知道,其实际上只是一种对ascii字符有效的封装而已。
同理,对于unicode对象,由于其是被解码后得到的对象,因此实际上不应该再有decode方法。但是2.x中,还是对其封装了decode方法,如下图所示,当调用unicode.decode('utf8')函数时,实际过程是上面的实线过程,即先通过ascii编码方式对其编码得到字节码后,再进一步对字节码进行解码,得到新的unicode对象。

2.2 python2.x解释器对.py文件解码解的实际上是unicode对象
第一部分中,我们说过,从.py文件到被执行,python解释器会对其进行解码,这个过程中,对于字符串的解码实际上只会对unicode对象有解码操作,对于str对象,python解释器会保留其字节序列,不会对其进行解码,这实际上是符合unicode对象在2.x中扮演的角色的,因为其本身就扮演着正常的字符串角色,所以该解码过程只对unicode解码也是预期之中的。并且,在程序中,str对象也始终是字节序列,而这个字节序列实际上是在编辑器中源代码被保存成.py文件时生成的,所以这个字节序列的内容取决于编辑器中源代码被保存成.py文件时的编码方式。
2.3 python2.x解释器默认编码方式为ASCII编码
python2.x中,解释器对py文件进行解码时,使用的默认解码方式是ASCII解码方式,所以只要我们没有特别声明,那么python2.x解释器都会使用默认的ascii编码方式对py文件进行解码。这点在3.x版本中有所变化,3.x版本中默认的编码方式是utf8,不再是ascii编码。
3 源代码出现中文触发的编码问题原因分析及解决办法
由于几乎所有的编码方式都是兼容ascii编码的,而且python2.x也做了相应的底层封装以适应用户对str的理解,所以在只出现英文以及相应符号的代码中,无论用户在哪个过程用的是什么编码,基本都不会出现编码问题,但是一旦源代码中出现非ASCII字符,那么由于python2.x的默认处理方式,以及不同编码之间的不完全兼容性,各种问题就会暴露出来了。本部分,将基于上述的储备知识 ,对python2.x源代码出现中文编码报错问题进行逐一分析。
总体来说,在源代码中写入中文容易出现报错的原因可以归为下面几类:1、直接写入中文,没有进行程序的编码声明;2、由于对python2.x的str对象和unicode对象不了解,误用encode和decode函数;3、编写源代码的编辑器对源代码进行编码时的编码方式和python解释器对.py文件解码时的编码方式不一致;4、直接打印str对象,显示台对str字节序列的解码和程序中对str的编码不一致,导致乱码或者报错。
3.1 直接写入中文,没有进行程序的编码声明
由于python2.x解释器默认的编码方式是ascii编码,因此一旦python检测到源码中出现了执行环境下(注释不会在执行环境下被执行,因此注释不受此限制)的非ASCII字符时,就会报类似下面的错误,但是脚本使用utf8有BOM格式的编码除外,因为有BOM的utf8可以直接被python识别为utf8编码,从而不声明也可以。该错误提示脚本中出现了非ASCII字符,而默认的ascii编码是无法解码非ascii字符对应的字节码的,因此,只要检测到非ASCII字符,就会报错。
SyntaxError: Non-ASCII character '\xc4' in file C:\Users\KK\Desktop\test.py on line 5, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details解决办法很简单,就如提示所示,只要在脚本中声明一下解释器对脚本文件的解码方式就好了。具体的声明方式就是在源代码的最开始写入# -*- coding: utf-8 -*- ,python在解码时,遇到这条声明语句,就会自动将解释器的解码方式转为utf8,这样便不再是默认的ascii编码,从而可以解码非ascii字符的字节码。当然,这里的声明方式也可以是其他形式,读者可以自行上网查,其中解码方式也可以是gbk等其他编码。
3.2 对str对象和unicode对象误用encode和decode函数
从2.1节中我们知道,python2.x中的str不是我们通常所理解的str,尤其对于非ascii字符,这种str的本质就会暴露出来。如果str是一个中文,那么对其调用encode函数时,必然会调用str.decode('ascii'),由于ascii编码无法解码中文字符对应的字节码,所以会报类似下面的错误,即ascii编码无法解码相应的字节码。
# -*- coding: utf-8 -*-
s = '你好'.encode('utf8')
print(s)
#如果执行包含上述源代码的文件,会发生如下报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal not in range(128)同样的,通过2.1节,如果对unicode对象调用decode函数,底层会先调用unicode.encode('ascii')函数,如果这时unicode对象是非ascii字符,那么也会报错,如下所示。这里要注意的是,由于unicode也会在解释器中被解码,因此需要先保证保存源码的编码方式和解释器解码的编码方式是一致的,不然没等decode函数报错,首先会因为上述的两个编码不一致导致解释器对unicode解码失败而先报错。
# -*- coding: utf-8 -*-
s = u'你好'.decode('utf8')
print(s)
#如果执行包含上述源代码的文件,会发生如下报错
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)对于上述问题的解决办法就是在理解python2.x中str对象和unicode对象的基础上,正确使用encode和decode函数,避免对str使用encode函数,避免对unicode对象使用decode函数。
3.3 编辑器保存源代码时的编码方式和解释器解码方式不一致
从第一部分我们知道,从源代码到被执行,有两个过程设计到编码解码:1、源代码被保存成.py文件这个过程,由编辑器指定编码方式对源代码进行编码;2、python解释器通过声明的编码方式对.py文件进行解码。自然的,这两个过程的编码和解码的方式必须一致,如果不一致,比如在对源代码编码成.py这个过程使用的是gbk编码,而在解释器中声明的是utf8编码,那么对于中文来说,utf8自然是无法解码经过gbk编码后生成的字节码的。如下所示,该源代码文件以gbk编码保存,运行后会报错,报错提示,utf8编码无法解码相应的字节码。
# -*- coding: utf-8 -*-
s = u'你好'
print(s)
#如果执行包含上述源代码的文件,且用windows下的ansi编码,即gbk编码保存,运行该文件后会发生如下报错
SyntaxError: (unicode error) 'utf8' codec can't decode byte 0xc4 in position 0: invalid continuation byte对此的解决办法就是检查源代码文件的编码方式,或者调整python解释器的编码声明,使得对源代码的编码和解释器对.py文件的解码这两个过程的编码方式是一样的。
3.4 直接操作str对象导致显示乱码或报错
我们在2.1节指出,str对象实际上就是字节码,且对于ascii字符,str、unicode也是相等的;同时我们在2.2节讲过,python解释器进行解码时,不会对str对象进行解码,而是对unicode对象进行解码。所以,如果源代码中,我们对于中文字符串,直接用str对象进行保存,那么该str在python执行程序时,不会被解码,依然是一个字节码。但是要注意的是,如果我们print该str对象,在控制台显示出结果这个过程,该字节码是会被自动解码的,这里的解码方式是控制台决定的。比如,我们在cmd中运行脚本,由于中文windows系统下的cmd默认解码方式是gbk,所以如果我们对源码保存时的编码方式不是gbk,那么生成的字节码用cmd下的gbk去解码,是会乱码或者报错的,看下面的例子。
下面的例子中,源代码用utf8编码保存,在cmd下运行后,由于utf8用三个字节保存一个中文字符,所以s对象是一个有六个字节的字节码,当最后print(s)时,由于显示在cmd下,cmd的默认解码方式是gbk,而gbk编码方式是用两个字节存储一个中文字符的,因此s的六个字节会被gbk解码成3个字符,而且这三个字符是gbk编码体系下对应的字符,所以会出现这样的三个字符的乱码。如果s对应的字节码在gbk中找不到对应的字符,便会报错,不再是出现乱码。
# -*- coding: utf-8 -*-
s = '你好'
print(s)
#如果执行包含上述源代码的文件,且用utf8编码保存,在cmd下运行该文件后会显示下面的乱码
浣犲ソ
对此最直接的解决办法自然就是保持编码一致,可以让源代码用gbk保存,由于这里没涉及unicode对象,解释器不会对str对象解码,且utf8和gbk编码对于ascii字符都是兼容的,因此可以依然保留开头对解释器utf8编码的声明,当然,最好同时也将声明改为gbk编码,保持一致。
上面的解决办法实际上比较麻烦,除非对2.x的编码和相关内容有较好的理解,不然改动的地方和要保持一致的地方太多,容易不小心出错。因此,更好的解决办法是避免直接对str对象操作,更具体的说,是避免在源代码中直接使用str对象,而是使用unicode对象,因为unicode对象和字符的对应关系是全世界统一的,所以不管什么平台,对于unicode对象转到字符的结果都是一致的,是平台独立的,因此便可以完全的避免这种编码平台依赖的问题。因此,一个基本原则就是,源代码中,保持字符对象都是unicode对象,而不是str对象。这也就是为什么很多人说要在定义中文字符的时候,使用u'string',而不是直接的'string'的原因。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









