






前不久Google Research在Dreamfields-3D基础上做了改进,发布了新成果DreamFusion,让**生成模型的形态、颜色、光线、密度有巨大的飞跃**,虽然 DreamFusion 还未开放使用,但项目网站提供了生成画廊:[DreamFusion预览地址](https://dreamfusion3d.github.io/index.html)。要直接训练一个text-to-3D的模型非常困难,因为DALL-E 2等模型的训练需要数十亿个图像-文本对作为训练集,但并不存在如此大规模的3D标注数据。DreamFusion先使用一个预训练2D Diffusion模型基于文本提示生成一张二维图像,然后引入一个基于概率密度蒸馏的损失函数,通过梯度下降法优化一个随机初始化的神经辐射场NeRF模型,实现无需3D训练数据的文生3D。
用从2D扩散模型的蒸馏中得到的损失来代替CLIP。我们的损失是基于概率密度蒸馏,最小化基于前向扩散过程的具有共享均值的高斯分布族与通过预先训练的扩散模型学习的得分函数之间的KL散度。所得到的分数蒸馏采样(SDS)方法使得能够经由可微分图像参数化中的优化进行采样。通过将SDS与针对此3D生成任务定制的NeRF变体相结合,DreamFusion为用户提供的各种文本提示生成高保真连贯的3D对象和场景。
论文创新点
应用场景
图像分辨率:64*64 在4芯片的TPUv4上进行优化(每个芯片渲染一个独立视图):Iteration=15, 000 ;T≈1.5h
000 ;T≈1.5h
方法
Diffusion 模型
在DreamFusion中,使用了一个预先训练的二维文本到图像Diffusion模型,扩散模型是latent-variable生成模型,它将样本从可控制的噪声分布逐渐转换为数据分布。扩散模型包括一个正向过程q,通过添加噪声慢慢地从数据x中消除原始数据分布;以及一个反向过程或生成模型p,从噪声 Zt 开始缓慢地添加数据分布。
用(加权)证据下界(ELBO)训练生成模型,简化为参数φ的加权去噪得分匹配目标:
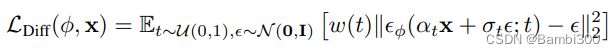
其中w ( t ) 是取决于时间步长t 的加权函数。扩散模型训练由此可以被视为学习潜变量/学习与数据的噪声版本相对应的分数函数序列。
Score Distillation Sampling(分数蒸馏采样)
SDS是通过评分蒸馏获取样本的质量或重要性信息,并结合采样生成高质量和多样性的样本集合。其核心思想是用Diffusion模型来监督NeRF的参数优化,使得NeRF渲染出的image跟Text一致。
蒸馏:因为扩散模型是固定的,所以 p(Φ)就是学习好的概率分布,这里需要学习的是让后验分布和扩散模型的分布更接近,这是一个蒸馏的过程。
采样器:在t=0的时候是没有噪声的,就是一个采样器

扩散模型的训练和采样都是在像素空间上,但是这里想得到的是从一个3D的模型渲染图像,从任意角度看都要效果比较好的模型。这样的模型可以叫做[可微分的图像参数化](DIP),即一个可微分的生成器把参数映射为图像 x=g(θ) 。在NeRF中, θ就是模型参数, g 就是体素渲染。
本文就是要优化NeRF模型的参数,使得NeRF渲染的图像看起来像扩散模型的样本。为了实现这个优化,首先使用扩散模型的训练误差来学习条件概率密度 P(x|y) ,最小化关于渲染图像的扩散模型误差。本章在实验后发现直接只用这个损失函数效果并不好,作者从损失函数的梯度上分析了原因:
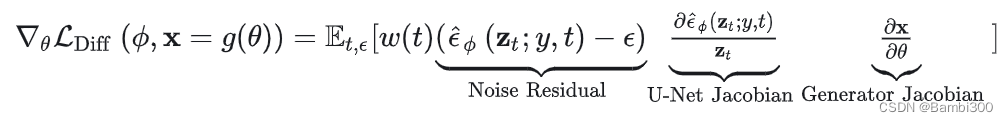
这里U-Net Jacobian项计算是十分耗时的,并且这是训练用于拟合边缘概率密度的缩放Hessian矩阵,对于小的噪声不友好。所以抛弃这一项:
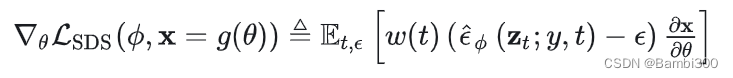
直观来说,就是和扩散模型一样采样一个时间点t,然后计算噪声误差,然后把这个误差反向传播计算梯度,即网络更新的方向。它是使用从扩散模型学到的分数函数的加权概率密度蒸馏损失的梯度。
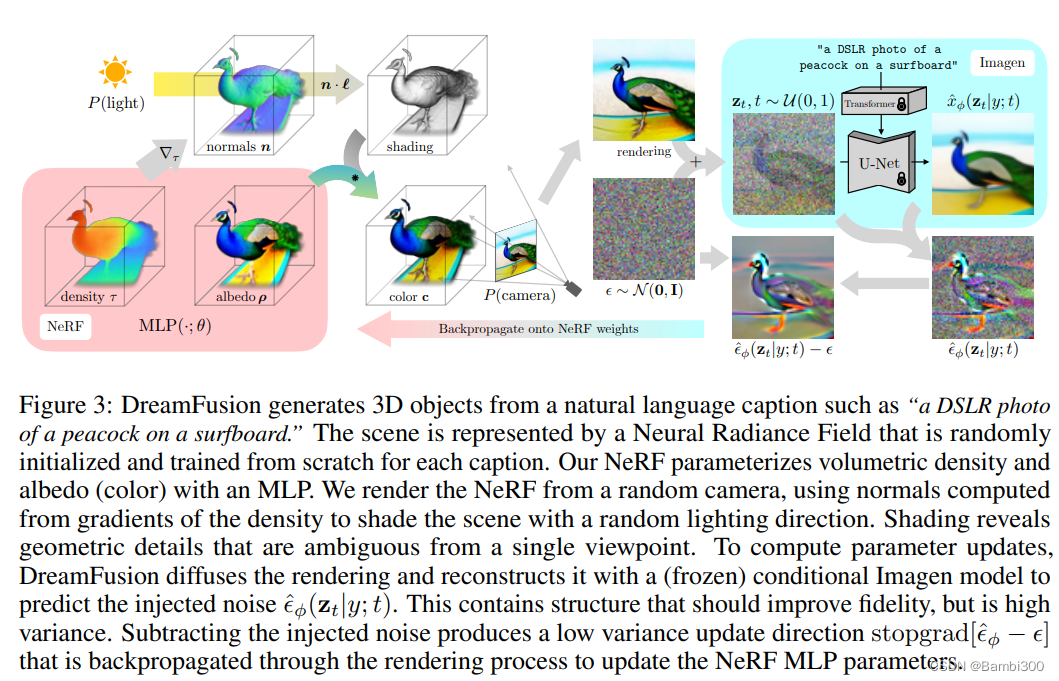
THE DREAMFUSION ALGORITHM
DreamFusion优化的每次迭代都会执行以下操作:(1)随机采样摄像头和光线,(2)渲染来自该摄像头的NeRF图像并使用光线着色,(3)计算SDS损失相对于NeRF参数的梯度,(4)用优化器更新NeRF参数。
扩散模型:Imagen,图像分辨率:64*64,随机初始化NeRF,随机渲染NeRF从不同的视角,作为扩散模型的输入。基于JAX 的mip-NeRF360的代码实现
Shading 传统的NeRF模型发射的辐射度,是以观察三维点的射线方向为条件的RGB颜色。相比之下,本文的MLP对表面本身的颜色进行参数化,然后由我们控制的照明来照亮它(这个过程通常被称为 通常被称为 "**Shading** "阴影")。每个点使用 τ (体积密度)、ρ(材料的颜色)表示:

点光源坐标 ℓ 和颜色 ℓρ ,环境光ℓa ,采样点的颜色计算表示为:
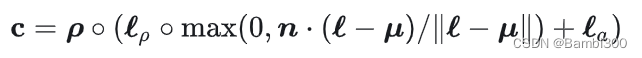
随机把 ρ 替换成(1, 1, 1)可以防止网络学成一个平面结构。
Scene Structure 1. 固定的球形边界。2. 用一个环境MLP来表示背景颜色,这是一个单独的MLP,和Urban-NeRF单独一个MLP表示天空一样,只和方向又关系。然后在渲染的颜色上加这个背景的颜色,这可以防止NeRF模型在离摄像机很近的地方用密度填满空间,同时还可以让它在生成的场景后面画上适当的颜色或背景。
Geometry regularizers 除了mip-NeRF360的约束外,还增加了对法线的约束和对不透明度的约束。对法线的约束作用是希望法向量在可见时朝向摄像机。不透明度的约束是可以在空白的空间不要出现物体,也就可以减少漂浮物。
启示
DreamFusion先使用一个预训练2D扩散模型基于文本提示生成一张二维图像,然后引入一个基于概率密度蒸馏的损失函数,通过梯度下降法优化一个随机初始化的神经辐射场NeRF模型。
DreamFusion用从2D扩散模型的蒸馏中得到的损失来代替CLIP,其损失是基于概率密度蒸馏,最小化基于前向扩散过程的具有共享均值的高斯分布族与通过预先训练的扩散模型学习的得分函数之间的KL散度。分数蒸馏采样(SDS)方法使得能够经由可微分图像参数化中的优化进行采样。通过将SDS与针对此3D生成任务定制的NeRF变体相结合,DreamFusion为用户提供的各种文本提示生成高保真连贯的3D对象和场景。

















 4977
4977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









