







写下此论文笔记仅是为了记录自己看论文的一个过程以及一些收获希望,希望能够和更多志同道合的朋友一起讨论交流!
感觉本篇论文的主要创新点是在于将低层、中间层和高层的feature maps结合起来形成Hyper Feature来进行region proposal和object detection,其它部分与Faster R-CNN很相似。
摘要:现在的目标检测都是用region proposals来做的。但大多数region proposals方法都是需要几千个proposal来保证如回率。本文提出了一个能够同时进行region proposal和object detection的深度层次结构——HyperNet。HyperNet主要是基于弹性设计的Hyper feature,首先 ,然后
,然后 。
。1.引言
(1)R-CNN的成功主要有两个方面:一方面它用从CNN模型中得到的高层目标表示来替换人工设计的特征如HOg等;第二点是它使用几千个与类别独立的region proposals来减小图像的搜索空间。
(2)对于Fast R-CNN和Faster R-CNN都存在一个问题,那就是因为deep CNN的最后一层输出feature map太粗糙(一个32*32大小的物体在VGG-16的最后一个卷积层输出时可能只有2*2大小了)而不利于小物体的分类。
(3)另外,由于深层的定位性能差,所以对于小物体以及IOU阈值高的情况下检测性能不好。
(4)一个能够在较小region proposals下具有较高recall的proposal生成器对于检测任务和其他应用来说都是非常必需的。
(5)从Fast R-CNN和RPN存在的问题反映出:a.对于object proposal和检测的特征信息量应该更多一些(should be more informative);

深层卷积层能够找到具有较高recall的感兴趣物体但检测性能较差;而网络的低层能够更好地定位感兴趣的物体但recall会降低。
所以一个好的object proposal/detection系统应该结合这两者。
(6)我们结合深层粗糙信息和浅层fine information形成Hyper feature。
2.相关工作
3. HyperNet框架结构
(1)HyperNet结构:
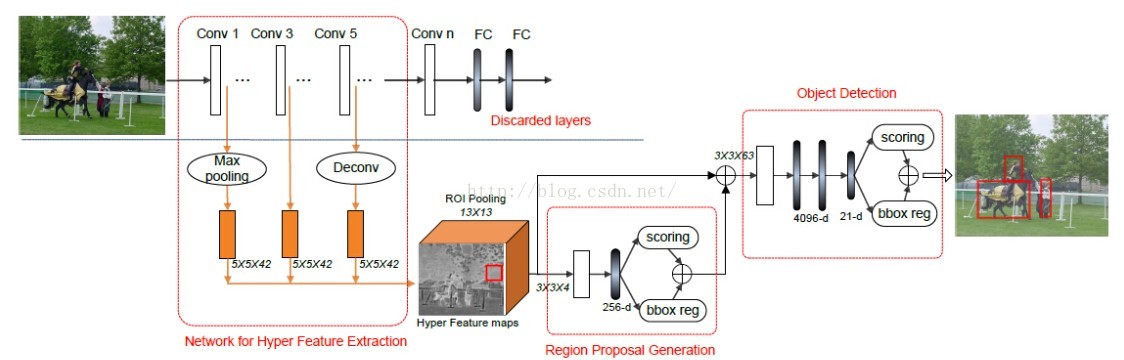
这个结构中主要三部分:第一部分生成Hyper feature;第二部分Region proposal generation;第三部分detection module(检测模块)。
3.1 生成Hyper Feature
(1)给定一个图像,我们运用一个预训练好模型的卷积层来计算整个图像的feature maps。与Fast R-CNN相同,我们在保持图像比例下将图像的short side resize到600像素。
(2)由于CNN中的降采样subsampling和pooling操作,这些特征maps的分辨率不同,所以我们对于不同的层采用不用的采样策略(sampling strategies),我们在最低层增加一个max pooling层进行降采样,对于高层,我们增加一个反卷积层(deconvolutional operation, Deconv)来进行上采样(upsampling)。A convolutional layer(Conv) is applied to each sampled result.
(3)最后,我们使用局部响应标准化(LRN)来对多个feature maps进行归一化,将多个feature maps合在一个单个的输了立方体,我们称为Hyper Feature。
(4)Hyper Feature有以下几个优点:a.多层次的抽象。Deep,intermediate和shallow层的CNN特征对于目标检测来说是互补的。b.合适的分辨率。对于一个1000*600的图像,feature map分辨率是250*150,这对于检测任务比较合适。c.计算的有效性。所有特征都是在region proposal生成和检测之前计算的。
3.2 Region proposal Generation(生成Region Proposal)
(1)我们设计了一个轻量级的ConvNet来生成region proposal,这个轻量级的卷积网络包含一个roi pooling层,一个卷积层和一个完全连接层和两个并行的输出层:scoring分类层和bbox reg层。
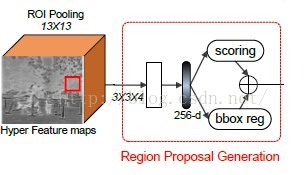
(2)对于每个图像,网络生成约30k个左右具有不同大小和比例的candidata boxes,ROI pooling层对每个box的w*h个output bins进行最大值池化,在本篇论文中,w和h都设置为13。在ROI pooling输出的顶端,一个将每个ROI位置编码成更抽象的(13*13*4)的抽象特征立方体,另一个层将每个立方体编码成一个256-d的短特征向量(a short feature vector),这个网络对每个candidate box有两个输出层。
(3)得到每个candidate box的score,并调整后,有一部分region proposals重叠率很高。为了减小冗余,我们采用NMS(极大值抑制)进行调整。我们将NMS的IoU阈值设置为0.7,使得每个图像留下1k个region proprosals。经过NMS后,我们选择排在前面的k个region proposals(top-k)进行检测。我们使用top-200个region proposals训练检测网络。
3.3 object Detection(目标检测)
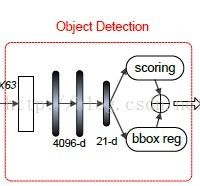
(1)实现目标检测最简单的方式是FC-Dropou-FC-dropout这样的流程。
(2)基于这个pipeline,我们做了两点修改:a.在FC层之前加了一个(3*3*63)的卷进积层;b.dropout的比例从0.5改为0.25。
3.4联合训练(Joint Training)
(1)在训练proposals时,我们为每个box分配一个二值标签。
当一个box与任意一个ground truth box的IoU大于阈值0.45时,就分配一个positive label;当一个box与任意一个ground truth的IoU都小于0.3时,则赋于一个negative label。
(2)训练过程:

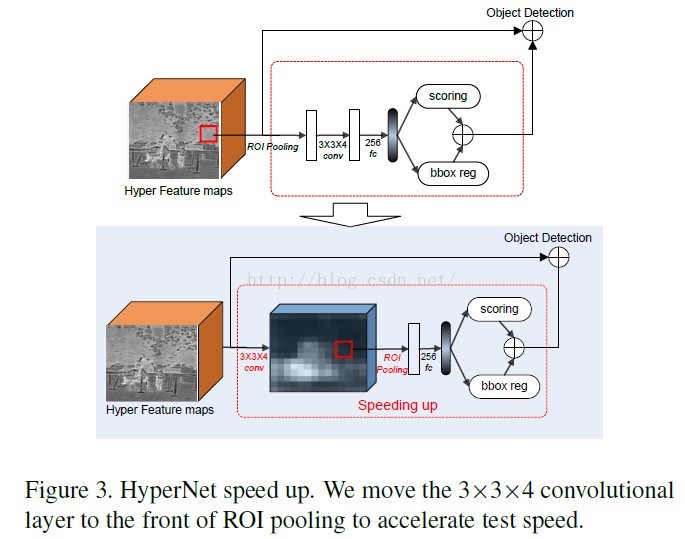
3.5 Speeding Up(加速)
将Region Proposals Generation网络中的3*3*4的卷积层放到roi pooling层的前面。
4.实验效果
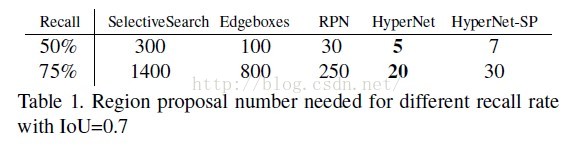
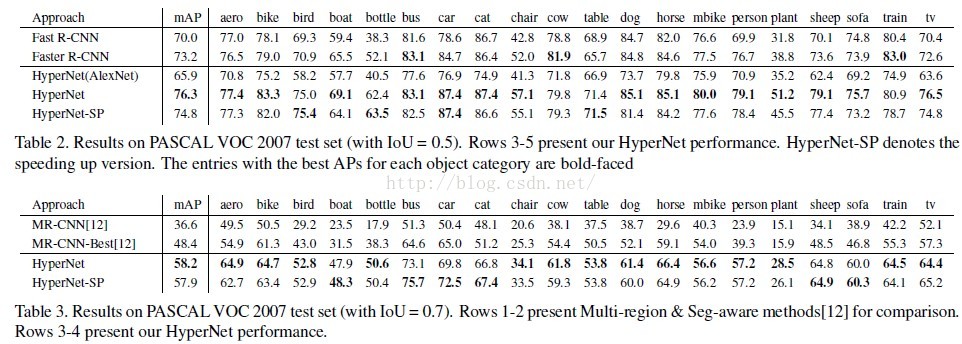














 9065
9065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









